Decoding Protocol Buffers
When a webMethods Messaging Trigger receives a document encoded as a protocol buffer, Integration Server decodes the document using the publishable document type of which the received document is an instance. During decoding, Integration Server uses the message descriptor created for the publishable document type. The message descriptor is a representation of the publishable document type as a protocol buffer. The IData that results from the decoding will be available in the pipeline when the trigger service executes.
Following are notes about how Integration Server handles certain aspects of decoding:

Any undeclared fields that were in the published document will follow the last defined field and immediately precede the
_env field in the decoded IData. Undeclared fields, also called unspecified fields, are those fields that existed in the published document but for which there is not a field in the publishable document type.
If a published document contains multiple fields that reference a single object,
Integration Server decodes the fields as distinct objects instead of as a single object with multiple fields referencing the object.
For example, suppose that a publishable document type has String fields abc and xyz and is used in a flow service. At some point in the flow service, in a MAP step, abc is mapped to xyz. As a result, xyz references abc . The value of xyz is the value of abc. Any subsequent change to the value of abc in the flow service also changes the value of xyz. When a document with multiple references is published, encoded, and then decoded, Integration Server replaces the reference from xyz to abc with the actual value of abc. After decoding, abc and xyz have the same value initially. But if the value of abc later changes, it will not affect the value of xyz.
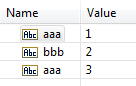
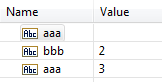
If a list field, such as String List, contains an empty element in the list but later elements in the list contain values, when
Integration Server decodes the list, it condenses the list to fill empty elements.
Integration Server condenses the list, first to last, leaving no empty elements in the list.
If a published document contains... | Integration Server decodes it as... |
| |
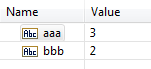
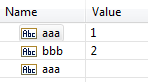
When decoding values for duplicate fields,
Integration Server does not maintain order of the values if one of the fields is empty .
Integration Server decodes later occurrence of the field at/in the position of the empty duplicate field.
The following table provides examples of how Integration Server decodes lists.
If a published document contains... | Integration Server decodes it as... |
| |
| |
| |
In addition, document decoding can fail if Integration Server encounters an unexpected data type. For example, if publishable document type defines a field named myString to be a String but, in the received document, the data type of myString is not an instance of String, Integration Server cannot decode myString because it is not the expected data type. In fact, trigger processing fails with the following error:
Protocol buffer coder cannot handle data type dataTypeName for field fieldName in document type: publishableDocumentType. Error: errorMessage
Often, when the above error occurs, it indicates that the publishable document types on the sending and receiving Integration Servers and the provider definition are out of sync. If the publishable document types were the same on the Integration Servers, during encoding, the publishing Integration Server would have caught the mismatch between the data type specified in the publishable document type and the data published in the instance document.