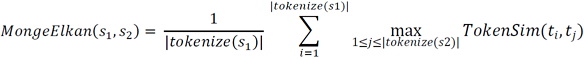Hybrid Similarity Functions
Hybrid similarity functions are combinations of token-based and character-based similarity functions. The input strings are first split into multiple smaller tokens — usually words. For more information on token-based similarity functions that apply splitting of strings, see
Smith-Waterman and
Smith-Waterman-Gotoh.
Monge-Elkan
As a hybrid similarity, Monge-Elkan first tokenizes two strings s 1 and s 2 into tokens t i and t i, respectively. It then matches every token t i from s 1 with the token t i in s 2 that has the maximum similarity using the secondary similarity function TokenSim. The arithmetic mean over these maximum similarity scores gives the final similarity measure:
Note:
The Monge-Elkan similarity is not symmetric. The assumption that MongeElkan(s1,s2) = MongeElkan(s2,s1) is not always true.
Monge-Elkan Example
Let us consider the following input strings “Acme Soft” and “Acm Software.”
Applying the Monge-Elkan similarity function with Levenshtein as the secondary function:
Maximum similarity for “Acme”and ”Acm” is:1 - 1/4 = 75%
1 - 4/8 = 50%
Therefore, the Monge-Elkan similarity is computed as:
Rivulatus
This ISO specific-similarity function is based on token similarity, which is strengthened with a complex character similarity function. In comparison to Scarus similarity, Rivulatus is much more robust in verifying misspellings and handling interchanged tokens.