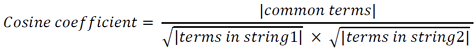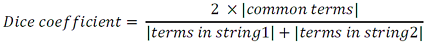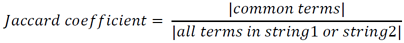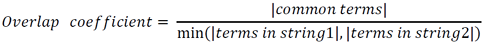Token-Based Similarity Functions
A token is a string of multiple characters like a word. Token-based similarity functions compare matching and dissimilar tokens between two strings in order to compute a similarity score. Therefore, all token-based similarity functions need a pre-processing step to extract a set of tokens out of each input string.
In webMethods OneData Matching API, the StringValueTokenizers perform the task of splitting, and optionally, transforming the original string into tokens (usually smaller sub-strings). For example, the string "the Atlantic coast" can be split into separate words and transformed to lower case as the following tokens:

“the”
“atlantic”
“coast”
Similarly, any number complex string processing is possible. For example, one could do additional splitting for punctuation or domain-specific processing in order to keep product numbers, URLs, or email addresses intact.
Another common approach is to split a string into n-grams, which are tokens of length n. Most often, n=2 or n=3. The n-grams are produced by sliding a window of length n over the input string from left to right. Using n=3 on the input string “the Atlantic coast,” would produce the following 3-grams:“the”, “he”, “ At”, “Atl”, “tla”, “lan”, “ant”, “nti”, “tic”, “ic “, “c c”, “ co”, “coa”, “oas”, “ast”
A common approach is to transform the input strings to lower case, and split them into words on whitespace, before tokenizing each word into n-grams. In which case, the string “the Atlantic coast” would be processed as follows:
To lower case: “the atlantic coast”
Split on whitespace into words: “the”, “atlantic”, “coast”
Split into 3-grams: “the”, “atl”, “tla”, “lan”, “ant”, “nti”, “tic”, “coa”, “oas”, “ast”
Comparing the common n-grams between the two strings gives a good approximation of their similarity. As always, this technique has advantages and disadvantages. Because tokens are sequences of multiple characters, token-based similarities are sensitive to even “minor” edit operations like insertion, deletion, replacement of single characters, or swaps of two characters, which are handled well by character-based similarities.
For example, if we delete the character “n” from “atlantic”, the string “atlatic” looses 3 common 3-grams: “atl”, “tla”, “lan”, “ant”, “nti”, “tic”
Token-based similarities also work well with swaps of whole words, which are handled poorly by character-based similarities. Depending on the tokenization method used, the score might not be affected in any way by word swaps. However, when using n-gram tokenization without prior word splitting, word boundaries are still considered.
For example, compare the following 3-gram tokenization:
“atlantic coast” -> “atl”, “tla”, “lan”, “ant”, “nti”, “tic”, “ic”, “c c”, “co”, “coa”, “oas”, “ast”
“coast atlantic” -> “coa”, “oas”, “ast”, “st ”, “t a”, “ at”, “atl”, “tla”, “lan”, “ant”, “nti”, “tic”
The 3-grams “ic”, “c c”, “co”, “st”, “t a”, and “at” represent the word boundaries and do not match when the two input strings are compared. Based on these pre-processing steps, the similarity functions in the following sections use different formulas to calculate the similarity score.
Cosine Coefficient
Dice Coefficient
Jaccard Coefficient
Overlap Coefficient
webMethods OneData Similarity Function
Other token-based similarity functions, when used with n-gram tokenization, allow the longer words to contribute more to the final score than the shorter words.
Consider the following two strings together with their 3-gram tokenizations:
“Acme Software”“acm”, “cme”, “sof”, “oft”, “ftw”, “twa”, “war”, “are”
“Ajax Software”“aja”, “jax”, “sof”, “oft”, “ftw”, “twa”, “war”, “are”
Here, the word “Software” contributes 6 of 8 tokens to the token set of “Acme Software,” leading to a Jaccard score of 6/10 = 60% or a Dice score of even (2 x 6)/(8 + 8) = 75%.
This behavior is often undesirable because, on a word-based level, you would give these two strings a similarity of 50%. This behavior is what the webMethods OneData similarity improves by taking into account both word-based and word-token relations. Also, more complex cases with compound words (frequent in the German language) or split word fragments are handled well by this technique.