Node-level Monitoring
The node-level monitoring ensures the ability of a particular instance of API Gateway components to serve the functionality (API requests) in the node. The node health is monitored by setting up probes per instance of each API Gateway component in the node.
The node-health monitoring enables you to check the following during the application start-up:

If the bootstrap of the node is completed.
If the node joined the cluster.
If the node is ready to serve the requests.
If the node is unhealthy, it identifies the problem and checks if the server component requires a restart.
The node-health monitoring enables you to check the following when the application in the node runs:
If the application is available.
If the application is under load.
If the application is performing well.
If there are any errors.
If the application is unhealthy, it identifies the problem and checks if the server component requires a restart.
You can monitor the node-health at:
Application level
Infrastructure level
Application level
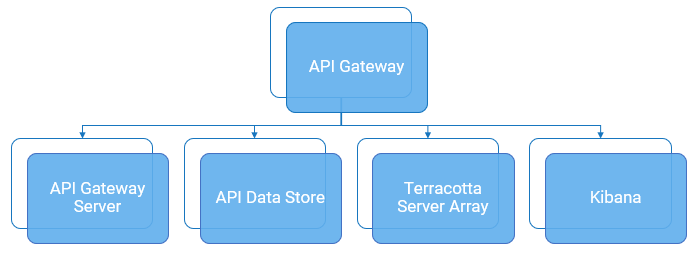
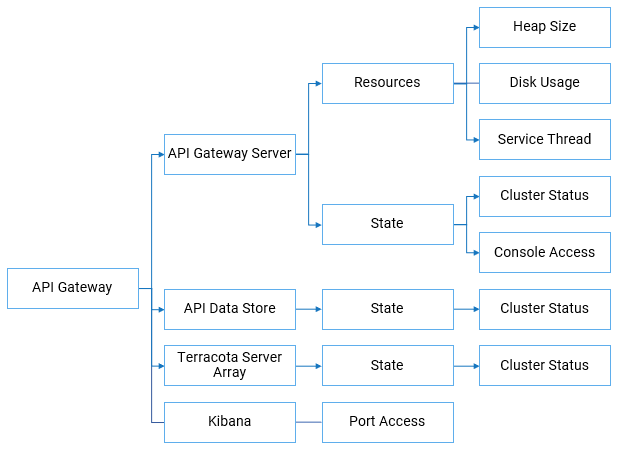
At the application level, you can monitor the state, that is cluster status and console access of the application along with the resource utilization of the application of the following API Gateway components:
API Gateway Server
API Data Store
Terracotta Server Array
Kibana
Note:
It is not required that all the components are hosted on the same node. Few components such as API Data Store,
Terracotta Server Array and so on can be hosted on dedicated nodes.
You can check both the cluster status and console access only for
API Gateway server and only the cluster status for API Data Store and Terracotta Server Array.
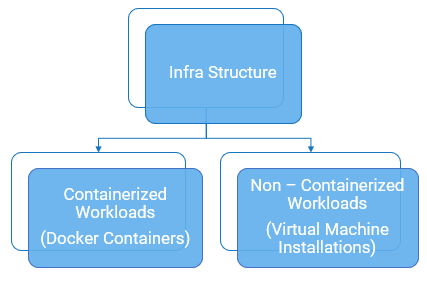
Infrastructure level
Note:
Startup probe is available in the recent versions of Kubernetes and is a recommended alternative to the Runtime Service Health Probe during the bootstrapping of the application. The endpoint is the same as that of the Runtime Service Health Probe but the Startup probe in Kubernetes itself is configured with slightly different characteristics like initial delay for the first check, failure threshold and so on.
At the Infrastructure level, you can monitor both containerized workloads (Docker containers) and non-containerized workloads (Virtual machine installations).
Note:
Most health checks are infrastructure-agnostic and can be used on both the types of infrastructure.
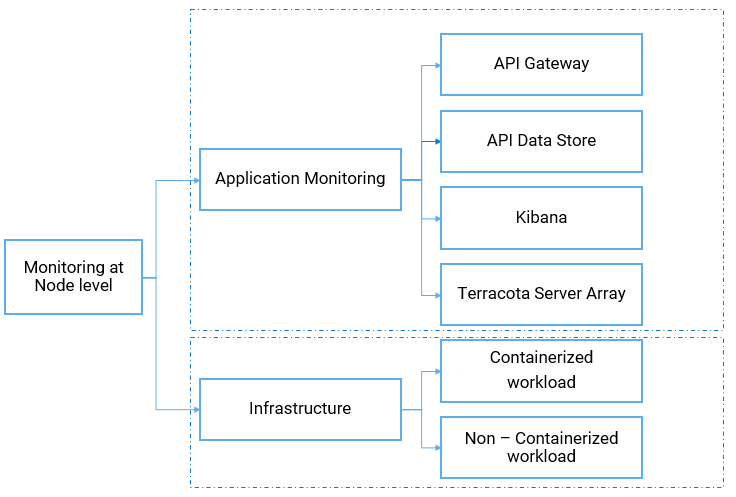
The overall node-level monitoring is explained in the following diagram.
The node-level monitoring in detail with the state and resource information of each component is explained in the following diagram.
How do I monitor the node health of API Gateway?
You can set up the Readiness probe, Runtime Service Health Probe, and Administration Service Health Probe to monitor the overall health status of a particular node of API Gateway.
Requirement | Impact | Solution |
For a running instance of an API Gateway or its components, is there an endpoint that returns yes or no about its readiness for serving the incoming API requests? | For Load Balancer or Kubernetes service to know if the node is healthy for it to be added to the load distribution pool for routing the incoming requests. | Use Readiness Probe. |
For a running instance of an API Gateway or its components, is there an endpoint that returns the metrics about the application and the resource utilization at the level of the container or the virtual machine? | To monitor capacity and performance. | Set up Metrics collection. |
For a running instance of API Gateway or its components, is there an endpoint that indicates the cluster health and the status of the runtime components? | To know the details about where the fault lies when there is a cluster failure, so that the node can be manually restarted. Kubernetes does it automatically. | Use Runtime Service Health Probe and Administration Service Health Probe. |
How do the probes help in node-level monitoring?
| Readiness Probe | Runtime Service Health Probe | Administration Service Health Probe |
What is it? | Indicates if the traffic-serving port of a particular API Gateway node is ready to accept requests. | Reports on the overall cluster health and indicates if the components of a particular API Gateway node are in an operational state. | Indicates if the API Gateway administrator consoles are available and accessible on a particular API Gateway node. |
When is it used? | To check if a particular node of API Gateway can be added to the load balancer. | To check if a node requires a restart or if there is a problem that needs immediate attention. |
How does it help in containerized workloads? | If the Readiness Probe fails, the pod is removed from the endpoints of the service. Hence, traffic is not served until it is ready. The pod is not shutdown or restarted. |
How does it help in non-containerized setup? | If the Readiness Probe fails, the node can be removed from the endpoints of the load balancer. Hence, traffic is not served until it becomes ready. |
Monitoring
The sections in the following diagram are explained in detail as part of monitoring API Gateway components.
Metrics
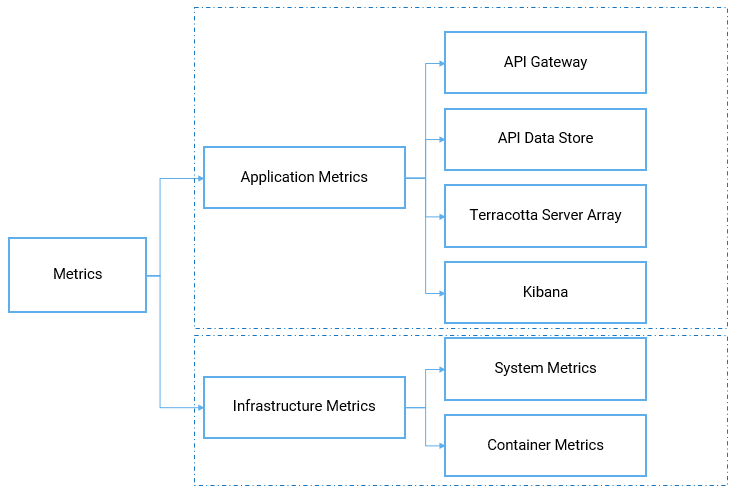
You can monitor the resources of API Gateway server, API Data Store, Terracotta, and Kibana with various metrics. A metric is a measurement related to health, capacity, or performance of a given resource such as CPU, Disk, and so on. Metrics are classified in to two types:
Application metrics. This refers to the metrics related to your API Gateway component.
Infrastructure metrics. This refers to the infrastructure, where the application runs. This is further classified into System metrics and Container Metrics. At the infrastructure level, you can monitor both containerized workloads (Docker containers) with container metrics and non-containerized workloads (Virtual machine installations) with system metrics.
Software AG offers you the capability to monitor both application metrics and infrastructure metrics. You can gain insight into the consumption and availability of resources, which in turn helps you identify and analyze the root cause and debug the issues quickly. This helps you to determine when to scale up the applications. This improves the overall business continuity and reduce the application downtime.
The following diagram explains the different types of metrics.