Topics and Logs
A topic is a category or feed name to which messages are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it.
For each topic, the Kafka cluster maintains a partitioned log as shown below:
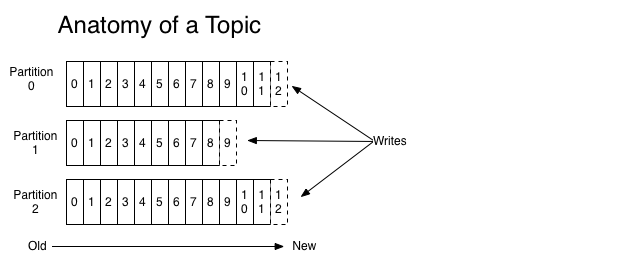
Each partition is an ordered, immutable sequence of records that is continually appended to a structured commit log. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition. The Kafka cluster retains all published records, whether or not they have been consumed using a configurable retention period. For example, if the retention policy is set to two days, then two days after a record is published, it is available for consumption, after which it will be discarded to free up space. Kafka's performance is effectively constant with respect to data size so storing data for a long time is not a problem.
The partitions in the log serve the following purposes:

Allows the log to scale beyond a size that will fit on a single server. Each individual partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data
Act as the unit of parallelism.