Structure, Format and Access to Datasets with RAQL
Since data in large datasets may come from many different sources, the data must be in a format and structure that is supported by RAQL. Valid data formats include:
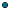
Comma-separated-values (CSV).
XML
JDBC Result Sets (from a database).
Java objects stored in
In-Memory Stores by external systems.
The structure of the dataset must also be flat, like a database table, containing two or more rows (records). Each row must contain at least one column with simple data. Each column must have a unique name.
JDBC result sets from database queries are always in the correct structure. For CSV, XML and Java objects, however, this imposes some specific restrictions. See
Supported Data Formats for
RAQL for details.
You can load large datasets in a mashup from:
Files: using
<variable>. Files must be in the classpath for the
Business Analytics Server.
URLs: using
<directinvoke> . This can be a web service or any hosted resource with an appropriate data format. This supports both GET and POST methods.
Any Business Analytics mashable or mashup: using
<invoke>.
Note: | Currently, <invoke> does not support streaming access to data. Results from <invoke> are documents and thus may have performance issues for large datasets. You can, however, run RAQL queries against result documents as long as some portion of the document matches the required table-like structure. |
Databases: using
<sql>.
Snapshots of Business Analytics Mashables or Mashups: using
<snapshot>.
Datasets Stored in one of the MashZone NextGen Analytics In-Memory Stores in BigMemory: using
<loadfrom>. Datasets may be stored by
Business Analytics, using
<storeto>, or by external systems using
BigMemory APIs.