Use an In-Memory Store to Store and Load Datasets for MashZone NextGen Analytics
So far, the examples have actually not used a large dataset that would require significant memory for Business Analytics. The examples have all loaded data directly from original sources without using Terracotta BigMemory or the MashZone NextGen Analytics In-Memory Stores. But this is not realistic in many cases.
The previous figure (in
The Stream/Document Boundary section) also illustrates the basic flow when you do need to store the dataset in memory to handle large amounts of data:
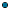
A mashup can stream data from an original source, preprocesses this stream if needed, and then stores the stream in an
In-Memory Store.
Other systems may also store data directly in an
In-Memory Store that has already been declared.
Other mashups can then load data from memory and perform further queries or analysis as needed.
Mashups that store datasets in MashZone NextGen Analytics In-Memory Stores use the <storeto>EMML extension statement. The dataset to store must also be the results of a RAQL query, although the query can simply select the entire dataset.
Each dataset is streamed to one In-Memory Store with a unique name that other mashups can then connect to to load this dataset. This store may already exist or the <storeto> statement may create the In-Memory Store and then store the dataset. With existing stores, the dataset being stored may be appended to the existing data or it may replace all existing data.
The following example mashup retrieves performance data for stocks from a URL using <directinvoke>. It uses a RAQL query to package all the data for storage with <raql> and includes stream='true' to treat the query results as a stream.
<mashup name='storeStockDataset'
xmlns:xsi='http://www.w3.org/2001/XMLSchema-instance'
xsi:schemaLocation='http://www.openmashup.org/schemas/v1.0/EMML/../schemas/EMMLPrestoSpec.xsd'
xmlns='http://www.openmashup.org/schemas/v1.0/EMML'
xmlns:macro='http://www.openmashup.org/schemas/v1.0/EMMLMacro'
xmlns:presto='http://www.jackbe.com/v1.0/EMMLPrestoExtensions'>
<output name='result' type='document' />
<variable name='diResult' type='document'/>
<variable name='stocksDS' type='document' />
<directinvoke method='GET' stream='true' outputvariable='diResult'
endpoint='http://mdc.jackbe.com/prestodocs/data/stocks.xml'
timeout='5' onerror='abort' />
<raql stream='true' outputvariable='stocksDS'>
select * from diResult
</raql>
<storeto cache='stocks2011' key='#unique' variable='stocksDS' version='2.0'/>
</mashup>
The mashup finally stores the data selected in the query in an In-Memory Store named stocks2011. If this store does not already exist, Business Analytics creates this In-Memory Store dynamically when you run the mashup.
Each row of the dataset is assigned a unique key based on the method defined in the key attribute. If the store does already exist and contains data, this dataset is appended to any existing data by default.
This example did not filter or adjust the dataset in any way before storing it. But you can also use a RAQL query to preprocess the data you want to store in MashZone NextGen Analytics In-Memory Stores.
Once you, or an external system, store a dataset, other mashups can use the <loadfrom>EMML extension statement to load this dataset stream for queries and other processing. The following example shows a mashup to retrieve this stock dataset and return just the first 10 rows:
<mashup name='simpleStocksLoad'
xmlns:xsi='http://www.w3.org/2001/XMLSchema-instance'
xsi:schemaLocation='http://www.openmashup.org/schemas/v1.0/EMML/../schemas/EMMLPrestoSpec.xsd'
xmlns='http://www.openmashup.org/schemas/v1.0/EMML'
xmlns:macro='http://www.openmashup.org/schemas/v1.0/EMMLMacro'
xmlns:presto='http://www.jackbe.com/v1.0/EMMLPrestoExtensions'>
<output name='result' type='document' />
<variable name='stocks' type='document' stream='true' />
<loadfrom cache='stocks2011' variable='stocks' version='2.0'/>
<raql outputvariable='result'>
select * from stocks limit 10
</raql>
</mashup>
The stored dataset from these example, shown below, will be used in other examples in Getting Started to discuss Group By and Over query clauses for grouping and analysis:

