JDBCJobStore
JDBCJobStore keeps all of its data in a database via JDBC. Because it uses a database, it is a bit more complicated to configure than RAMJobStore, and it is not as fast. However, the performance draw-back is not terribly bad, especially if you build the database tables with indexes on the primary keys. On fairly modern set of machines with a decent LAN (between the scheduler and database) the time to retrieve and update a firing trigger will typically be less than 10 milliseconds.
JDBCJobStore works with nearly any database, it has been used widely with Oracle, PostgreSQL, MySQL, MS SQLServer, HSQLDB, and DB2.
To use JDBCJobStore, you must first create a set of database tables for Quartz to use. You can find table-creation SQL scripts in the "docs/dbTables" directory of the Quartz distribution. If there is not already a script for your database type, just look at one of the existing ones, and modify it in any way necessary for your DB.
Note that in the scripts, all the tables start with the prefix "QRTZ_" (such as the tables "QRTZ_TRIGGERS", and "QRTZ_JOB_DETAIL"). This prefix can actually be anything you'd like, as long as you inform JDBCJobStore what the prefix is (in your Quartz properties). Using different prefixes may be useful for creating multiple sets of tables, for multiple scheduler instances, within the same database.
Once you have created the tables, you need to decide what type of transactions your application needs. If you don't need to tie your scheduling commands (such as adding and removing triggers) to other transactions, then you can let Quartz manage the transaction by using JobStoreTX as your JobStore (this is the most common selection).
If you need Quartz to work along with other transactions (for example, within a J2EE application server), you should use JobStoreCMT, which case Quartz will let the app server container manage the transactions.
Lastly, you must set up a DataSource from which JDBCJobStore can get connections to your database. DataSources are defined in your Quartz properties using one of a several approaches. One approach is to have Quartz create and manage the DataSource itself by providing all of the connection information for the database. Another approach is to have Quartz use a DataSource that is managed by the application server within which Quartz is running. You do this by providing JDBCJobStore the JNDI name of the DataSource. For details on the properties, consult the example config files in the "docs/config" folder.
To use JDBCJobStore (and assuming you're using StdSchedulerFactory) you first need to set the JobStore class property of your Quartz configuration to one of the following:
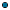 org.quartz.impl.jdbcjobstore.JobStoreTx
org.quartz.impl.jdbcjobstore.JobStoreTxorg.quartz.impl.jdbcjobstore.JobStoreCMT The choice depends on the selection you made based on the explanations in the above paragraphs.
The following example shows how you configure JobStoreTx:
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
Next, you need to select a DriverDelegate for the JobStore to use. The DriverDelegate is responsible for doing any JDBC work that may be needed for your specific database.
StdJDBCDelegate is a delegate that uses "vanilla" JDBC code (and SQL statements) to do its work. If there isn't another delegate made specifically for your database, try using this delegate. Quartz provides database-specific delegates for databases that do not operate well with StdJDBCDelegate. Other delegates can be found in the org.quartz.impl.jdbcjobstore package, or in its sub-packages. Other delegates include DB2v6Delegate (for DB2 version 6 and earlier), HSQLDBDelegate (for HSQLDB), MSSQLDelegate (for Microsoft SQLServer), PostgreSQLDelegate (for PostgreSQL), WeblogicDelegate (for using JDBC drivers made by WebLogic), OracleDelegate (for using Oracle), and others.
Once you've selected your delegate, set its class name as the delegate for JDBCJobStore to use.
The following example shows how you configure JDBCJobStore to use a DriverDelegate:
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
Next, you need to inform the JobStore what table prefix (discussed above) you are using.
The following example shows how you configure JDBCJobStore with the Table Prefix:
org.quartz.jobStore.tablePrefix = QRTZ_
And finally, you need to set which DataSource should be used by the JobStore. The named DataSource must also be defined in your Quartz properties. In this case, we're specifying that Quartz should use the DataSource name "myDS" (that is defined elsewhere in the configuration properties).
org.quartz.jobStore.dataSource = myDS
Tip: | If your Scheduler is busy, meaning that is nearly always executing the same number of jobs as the size of the thread pool, then you should probably set the number of connections in the DataSource to be the about the size of the thread pool + 2. |
Tip: | The org.quartz.jobStore.useProperties config parameter can be set to true (it defaults to false) in order to instruct JDBCJobStore that all values in JobDataMaps will be Strings, and therefore can be stored as name-value pairs, rather than storing more complex objects in their serialized form in the BLOB column. This is much safer in the long term, as you avoid the class versioning issues that come with serializing non-String classes into a BLOB. |
 |
Feedback
|
Feedback