About Active/Active Clustering
Introduction
In an active/active cluster, multiple servers are active and working together to publish and subscribe messages. Universal Messaging clients automatically move from one server to another server in a cluster as required or when specific servers within the cluster become unavailable to the client for any reason. The state of all the client operations is maintained in the cluster to enable automatic failover.
To form an active/active cluster, more than 50% of the servers (a quorum) in the cluster must be active and intercommunicating. Quorum is the term used to describe the state of a fully formed cluster with an elected master.
Applications connected to a Universal Messaging cluster can:

Publish and subscribe to channels
Push and pop events from queues
Connect to any Universal Messaging server instance and view the server state
If a cluster node is unavailable, client applications automatically reconnect to any of the other cluster nodes and continue to operate.
What is active/active clustering?
A Universal Messaging active/active cluster has multiple Universal Messaging server nodes (realm servers) running simultaneously. All nodes in the cluster are able to accept connections from publishing and subscribing clients.
Every node in the cluster maintains a separate but identical copy of the entire cluster state, i.e. channels, queues, durable subscribers, in-flight messages, etc. The cluster nodes co-operate continuously to ensure that the replicated state is maintained correctly across the whole cluster. The cluster elects a single node to act as the “master” and co-ordinate the state replication process.
If a cluster node becomes unavailable, e.g. due to a software, hardware or network failure, all clients connected to that node will quickly fail over to another node with minimal interruption to messaging traffic. This typically takes no more than a few seconds and, provided the clients are correctly configured, this process is transparent to the applications and no messages will be lost. If the cluster master node becomes unavailable, the remaining nodes will elect a new master between them. When a failed or disconnected node is able to reconnect to the cluster, it will automatically resynchronize its state and continue operating.
An active/active cluster will continue to process messages as long as more than 50% of the nodes in the cluster are operating and able to communicate with one another. For example, this means that a three-node cluster will continue operating as long as at least two of its nodes are running and able to communicate with each other.
Active/active clustering is an advanced capability offered by Universal Messaging that is not available with the webMethods Broker.
What are the benefits of using active/active clustering?
Active/active clustering provides a high availability resiliency within the messaging software layer as part of a high availability strategy. This is achieved using cheap local disks attached to each node with the messages and events synchronized between the nodes by Universal Messaging. This approach removes the need for expensive network disks (NAS or SAN) as well as the requirement for additional software to manage any failover.
What should you know before using active/active clustering?
The following table provides an initial set of questions you should think about when deciding on whether active/active is suitable as part of your high availability strategy.
What runtime infrastructure will be used - virtual machine or physical? | Ideally nodes should be on physical machines. Virtual machines should have pinned resources to ensure appropriate infrastructure for the cluster to run. Each node virtual machine should be on a separate physical machine. |
What storage will be used – local or SAN? | Local disk should be used. SAN can cause contention when used below a cluster as all realms are saving to the same disk. |
How many nodes in the cluster? | Best practice is 3 nodes, this allows the cluster to keep working if a node drops. |
Are the nodes in the same data center or are they on multiple sites? | If you have a deployment across multiple data centers, we suggest you consider using active/active with sites, but be aware of the restrictions and operational considerations with such a configuration. See the section
Active/Active Clustering with Sites for related information. |
Is this a new deployment or a Broker migration? | While Universal Messaging generally performs better than Broker, a cluster reduces performance of Universal Messaging by approximately 40% . |
What are the availability requirements? | Clusters cannot be updated on a rolling basis. There will be a few seconds if the master node drops for a re-election to happen. |
How does the active/active cluster work?
In an active/active cluster, one of the cluster nodes must be designated as the master node. The master node is selected by the cluster nodes. Each cluster node submits a vote to choose the master node. If the master node exits or goes offline due to power or network failure, the remaining active cluster nodes elect a new master, provided more than 50% of the cluster nodes are available to form the cluster.
Cluster nodes replicate resources amongst themselves, and maintain the state of the resources across all cluster nodes. Operations such as configuration changes, transactions, and client connections go through the master node. The master node broadcasts the requests to the other cluster nodes to ensure that all the servers are in sync. If a cluster node disconnects and reconnects, all the states and data are recovered from the master node.
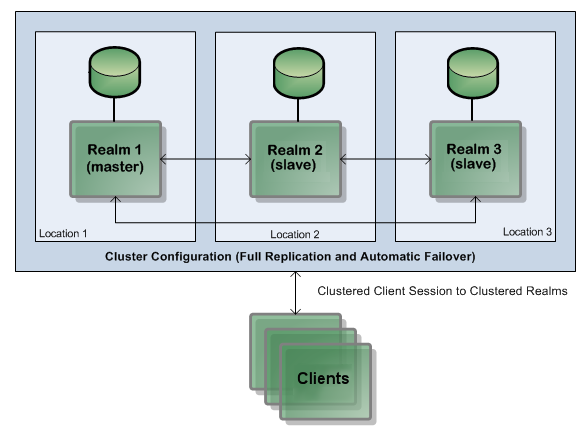
The following diagram represents a typical three-realm active/active cluster distributed across three physical locations:
Typical three-realm active/active cluster distributed across three physical locations
You can connect one cluster to another cluster through remote cluster connections. Remote cluster connections enable bi-directional joins between clusters, therefore joining the resources of both the clusters for publish and subscribe.
How should an active/active cluster be deployed?
It is essential that each node in an active/active cluster is deployed on physically separate hardware, to reduce the risk of a single hardware failure affecting multiple cluster nodes. When virtualization is being used, this means that each node must run on a virtual machine that is pinned to a different physical host. In the case of blade servers, it is recommended that each cluster node runs on a blade in a different chassis.
Ideally, the storage used by each cluster node will be local to the physical hardware that the node is running on, even when the machine and storage are virtualized. Using networked storage will have a performance impact and introduces additional failure modes that the cluster cannot protect against. Simple network accessible storage (NAS) becomes a single point of failure that would prevent the entire cluster from functioning if it failed. A storage area network (SAN), while it might be more resilient to failure, unnecessarily replicates data that is already being replicated by the cluster and can have an extreme negative effect on cluster throughput.
In general, a three node cluster is recommended as the best trade-off between availability and deployment cost, when running the cluster in a single data center. See the description of using “sites” for an alternative approach when multiple geographically separated data centers are used.
An active/active cluster will require more hardware resources (CPU, RAM, I/O bandwidth and network bandwidth) than a single UM server to support the same throughput. These resources are required to physically run the additional servers in the cluster, transfer cluster state across the network, and store multiple copies of the complete cluster state. In high load situations it is recommended to deploy a separate network for intra-cluster traffic, to keep this separated from client (message publishing and subscribing) traffic.
When virtualization is used, it is highly recommended to allocate enough virtual resources to every node to handle the maximum expected load on the cluster, and to ensure these resources are not shared with any other virtual machine. This will help to prevent outages caused by a shortage of shared hardware resources during periods of high load.
Many virtual machine infrastructures have the ability to move virtual machines between physical hosts to automatically load balance (known as VMotion with VMWare). This capability is very attractive, but comes at a cost. While the virtual machine is being moved it will appear to be unavailable for a period of time, the length of which will depend on the network infrastructure and a number of other factors. If that period extends beyond a few seconds that can cause the UM cluster to regard the node as being unavailable and it will therefore be removed from the cluster. When the node then re-joins the cluster it will have to resynchronize with the other nodes, which can be expensive. Therefore if virtual machines are moved around routinely it can have a serious impact on cluster performance and availability.