Modellausführung für verschiedene Geräte
Modelle werden für verschiedene Geräte unabhängig ausgeführt. Das heißt, die Modelle für ein Gerät können parallel ausgeführt werden, wenn möglich unter Verwendung von Hardware-Parallelität, wenn die Modelle Daten (wie zum Beispiel Measurement-, Event- oder Operation-Objekte) für verschiedene Geräte verarbeiten. Wenn Sie ein Modell definieren, dann können Sie es so konfigurieren, dass nur Daten von einem Gerät oder von mehreren Geräten verwendet werden, wobei jedes Gerät unabhängig behandelt wird.
Jedes Modell muss entweder:

Eingaben von einem einzigen Gerät empfangen oder
Eingaben für jedes Gerät innerhalb von Gerätegruppen empfangen.
Eine Gerätegruppe ist ein Mittel zum Organisieren von Geräten. Eine Gerätegruppe kann beliebig viele Geräte oder auch weitere Gerätegruppen enthalten. Wenn ein Modell eine Gerätegruppe verwendet, dann wirkt sich das Modell auf alle Geräte in dieser Gerätegruppe aus, entweder direkt oder indirekt über Mitglieder der Gerätegruppe, die selbst Gerätegruppen sind und Gerätemitglieder haben (oder sogar "Enkelkinder"-Gerätegruppenmitglieder). Ein Gerät kann Mitglied von keiner, einer oder mehreren Gerätegruppen sein.
Siehe auch die Informationen zur Device Management-Anwendung und dem Gruppieren von Geräten im User guide (hiervon gibt es auch eine deutsche Version) unter https://www.cumulocity.com/guides/.Note: Ein Modell ermittelt die Mitglieder einer Gerätegruppe nur beim Aktivieren des Modells. Wenn sich die Mitglieder einer Gerätegruppe während der Ausführung des Modells ändern, dann hat dies keinen Einfluss auf das Modellverhalten; neu hinzugefügte oder entfernte Mitglieder werden bei der Ausführung nicht berücksichtigt. Wenn Sie die Mitglieder einer Gerätegruppe ändern, dann sollten Sie alle Modelle, die diese Gerätegruppe benutzen, deaktivieren und anschließend wieder aktivieren.
Es ist nicht möglich, die beiden oben genannten Eingabeblocktypen zu kombinieren (siehe jedoch
Broadcast-Geräte). Daten von einem Modell, das einzelne Geräte verarbeitet, können jedoch an andere Modelle gesendet und von diesen empfangen werden, einschließlich Modellen für Gerätegruppen, und umgekehrt (siehe
Verbindungen zwischen Modellen).
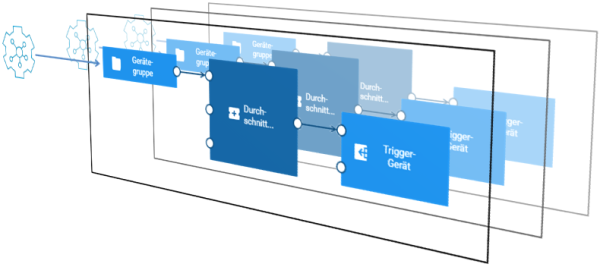
Wenn ein Modell Daten aus Gerätegruppen verwendet, dann verhält sich das Modell so, als würden mehrere Instanzen dieses Modells ausgeführt (wie unten veranschaulicht), wobei jede Instanz die Daten von jedem Gerät unabhängig verarbeitet. Jede Instanz verarbeitet Daten für ein anderes Gerät, aber alle haben die gleichen Blöcke und Blockparameter. Die Werte auf den Verbindungen sind bei den verschiedenen Instanzen unabhängig. Alle zustandsorientierten Blöcke, wie zum Beispiel der Durchschnitt (Mittelwert)-Block, arbeiten unabhängig von den Daten anderer Geräte. Wenn ein Block (wie bei Modellen mit einzelnen Geräten) einen Laufzeitfehler oder eine Ausnahme verursacht, dann wird das gesamte Modell in einen fehlerhaften Zustand versetzt und die Verarbeitung der Daten wird für alle Geräte gestoppt.
Wenn für die Eingaben Gerätegruppen verwendet werden, dann benutzen alle Eingabeblöcke normalerweise dieselbe Gruppe. Es ist möglich, verschiedene Gerätegruppen zu verwenden. Wenn sich Geräte in einer Gruppe befinden, jedoch nicht in einer anderen, dann generieren diese Blöcke niemals ein Signal für die Geräte, die nicht in dieser Gruppe sind. Bei einigen Blöcken, wie zum Beispiel dem Ausdruck-Block, ist dies nicht hilfreich. Ein Ausdruck-Block generiert nur dann eine Ausgabe, wenn alle erforderlichen Eingänge einen Wert erhalten haben. Für die pulse-Eingänge eines Gate-Blocks kann dies jedoch hilfreich sein.
Wenn ein Modell Eingänge hat, die Daten von einem einzelnen Gerät verwenden, dann müssen die Ausgabeblöcke, welche die synchrone Ausgaben erzeugen, dasselbe Gerät angeben. Ein Modell kann eine beliebige Anzahl von Ausgabeblöcken verwenden, die asynchrone Ausgabe generieren und alle dasselbe Gerät oder verschiedene Geräte als Eingabegerät angeben. Asynchrone Ausgabeblöcke können auch mit synchronen Ausgabeblöcken kombiniert werden.
Wenn ein Modell Eingänge hat, die Daten aus einer Gerätegruppe verwenden, dann müssen alle synchronen Ausgabeblöcke das Trigger-Gerät angeben. Dies ist ein spezieller Block, den Sie in der Ausgabe-Kategorie der Palette finden. Der Block Trigger-Gerät generiert Daten (Measurement, Event oder Operation) für jedes Gerät, für das die Modellinstanz gilt - oder für jedes Gerät, das die Daten gesendet hat, um diese Modellinstanz auszulösen. Asynchrone Ausgabeblöcke in solchen Modellen können das Trigger-Gerät oder ein spezielles Gerät angeben.
Mit dem Modelleditor können Sie die Geräte oder Gerätegruppen in den Eingabe- und Ausgabeblöcken durch andere ersetzen. Wenn Sie eine Gerätegruppe durch ein Gerät ersetzen, dann schalten die Ausgabeblöcke zwischen dem Trigger-Gerät und dem angegebenen Gerät um, sodass das Modell in einem einsatzfähigen Zustand bleibt. Siehe auch
Geräte, Gerätegruppen und Assets ersetzen.
Die Test- und Simulationsmodi sind nur für Modelle mit einem einzigen Gerät zulässig. Wenn Sie ein Modell mit einer Gerätegruppe testen oder simulieren möchten, dann sollten Sie es mit dem Modelleditor so abändern, dass es für ein einzelnes Gerät innerhalb der Gerätegruppe gilt und aktivieren Sie das Modell anschließend im Test- oder Simulationsmodus. Weitere Informationen zu diesen Modi finden Sie unter
Ein Modell aktivieren.
Den Gleichzeitigkeitsgrad definieren
Standardmäßig verwendet die
Apama Analytics Builder-Laufzeit 1 CPU-Kern zur Ausführung von Modellen. Sie können die Anzahl der CPU-Kerne ändern, indem Sie eine
POST-Anfrage an
Cumulocity IoT senden, die den Wert des Keys
numWorkerThreads ändert. Ausführliche Informationen finden Sie unter
Konfiguration.
Normalerweise wird dieser Konfigurationswert auf die Anzahl der für das System verfügbaren CPU-Kerne gesetzt. Es kann jedoch nützlich sein, diesen Wert je nach den verfügbaren Ressourcen höher oder niedriger zu konfigurieren. Er muss nicht auf die Anzahl der Geräte skaliert werden (das heißt, es ist durchaus sinnvoll, 4 Worker-Threads mit Hunderten von Geräten zu haben, wenn man von einer moderaten Ereignisrate pro Gerät ausgeht).
Modelle, die Daten von mehr als einem Gerät verwenden
Da jedes Gerät, wie oben erwähnt, unabhängig verarbeitet wird, ist es in einem Modell nur möglich, Daten von einem einzelnen Gerät zu verwenden oder Daten für ein einzelnes Gerät zu generieren. Es ist jedoch möglich, den Gleichzeitigkeitsgrad auf 1 zu setzen. Dann ist es möglich, Modelle zu aktivieren, die Daten von verschiedenen Geräten verwenden und generieren können. Da der Wert für den Gleichzeitigkeitsgrad (numWorkerThreads) eine globale Einstellung ist, bedeutet dies, dass bei einer gegebenen Apama Analytics Builder-Umgebung entweder nur Skalierungen oder geräteübergreifende Modelle möglich sind.
Mit einem Gleichzeitigkeitsgrad von 1 ist es immer noch möglich, Modelle zu erstellen, die Gerätegruppen als Eingaben verwenden. Diese funktionieren jedoch weiterhin unabhängig für jedes Gerät innerhalb der Gerätegruppe, und es ist noch immer nicht möglich, die Eingaben oder Ausgaben von Gerätegruppen und einzelnen Geräten zu kombinieren.