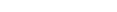
This document covers the following topics:
The Natural buffer pool is used to share Natural objects between several Natural processes that access objects on the same computer. It is a storage area into which compiled Natural programs are placed in preparation for their execution. Programs are moved into and out of the buffer pool as Natural users request Natural objects.
Since Natural generates reentrant Natural object code, it is possible that a single copy of a Natural program can be executed by more than one user at the same time. For this purpose, each object is loaded only once from the system file into the Natural buffer pool, instead of being loaded by every caller of the object.
The following topics are covered below:
Objects in the buffer pool can be any executable objects such as programs and maps. The following executable objects are only placed in the buffer pool for compilation purposes: local data areas, parameter data areas and copycodes.
When a Natural object is loaded into the buffer pool, a control block called a directory entry is allocated for that object. This control block contains information such as the name of the object, to which library or application the object belongs, from which database ID and Natural system file number the object was retrieved, and certain statistical information (for example, the number of users who are concurrently executing a program).
Resource sharing requires that access to the buffer pool be coordinated among all users. Several system resources are necessary to accomplish this. For example, shared memory on the Linux operating system is used to store the objects and their administrative information. To synchronize access to these objects, a set of semaphores is used. The amount of available shared memory and the number of semaphores is configured statically in the operating system, and as a result, it may be necessary to change system parameters and to recreate the operating system kernel for your installation. Further information about these topics is system-dependent and is described in the installation documentation for your Linux computer.
Depending on the individual requirements, it is possible to run different buffer pools of the same Natural version simultaneously on the same computer.
When a user executes a program, a call is made to the buffer pool manager. The directory entries are searched to determine whether the program has already been loaded into the buffer pool. If it does not yet exist in the buffer pool, a copy is retrieved from the appropriate library and loaded into the buffer pool.
When a Natural object is being loaded into the buffer pool, a new directory entry is defined to identify this program, and one or more other Natural objects which are currently not being executed may be deleted from the buffer pool to make room for the newly loaded object.
For this purpose, the buffer pool maintains a record of which user is currently using which object, and it detects situations in which a user exits Natural without releasing all its objects. It dynamically deletes unused or out-of-date objects to accommodate new objects belonging to other applications.
When a Natural object is executed, the Natural runtime system remembers the object name, the library (name, database ID and file number) and the address of the corresponding buffer pool directory entry. This data is referred to as "fast locate information".
When a Natural object is executed again, the Natural runtime system passes the fast locate information to the buffer pool manager and performs a time-saving fast locate call. A fast locate call bypasses the normal locate procedure including the steplib search and the search in the buffer pool. It is therefore the most efficient way to locate an object. It provides significantly better performance of subsequent program loads especially when steplib libraries are involved in multi-user environments.
The address of an object saved as fast locate information is no longer valid once the object is removed from the buffer pool, overwritten by another object or reloaded to another buffer pool location. If the fast locate call does not find the object at the given address, the object is searched in the buffer pool. If not found in the buffer pool, the object is reloaded from the system file.
This section covers the following topics:
Fast locate calls are issued when an object is accessed or resumed. An object
resume operation is performed, for example, when an object continues to execute
after a CALLNAT statement. For object resume operations, the Natural
runtime system keeps fast locate information of the calling object for each program
level on the internal stack.
The Natural runtime system keeps fast locate information about each accessed object in the internal fast locate table. The fast locate table also contains information about all libraries in which an object was searched. For a subsequent call, a fast locate is issued if the current library and associated steplibs are still the same.
The fast locate table is a hash table. The entries can be directly accessed without searching for an object name. The hash value is calculated from the object name. It determines the slot index number for the object. If another object has the same hash value (hash collision), a normal locate call is performed and the entry in the fast locate table is overwritten.
If an object for the library given in the fast locate table is neither found in the buffer pool nor in the system file (which means that the object has been deleted or moved to another library), a normal locate call with the full steplib search is scheduled automatically.
The Locate Statistics of the buffer pool monitor shows how many locate attempts were made and how many of these attempts were fast locate calls (see Statistical Information About the Buffer Pool). These values can be used to review the efficiency of the fast locate table. If the fast locate table is activated for an application that calls the same objects many times, and if these objects are contained in a steplib library, the following applies:
The number of locate attempts should decrease significantly (compared with a deactivated fast locate table).
The number of fast locate attempts should be close to the number of locate attempts.
If the BPSFI
(Object Search First in Buffer Pool) profile parameter is set to ON,
the fast locate table is activated by default. It is initialized at the start of the
Natural session and it is not cleared implicitly during the running session. It can
be deactivated or cleared with the application programming interface USR3004N as
described in the section Maintaining the Fast Locate Table.
In the following example, a subprogram is called 3,000,000 times. In the first test, the subprogram is found in the current library, then in Steplib 1, Steplib 2, and so on. The red line shows the elapsed time needed for the program load with a deactivated fast locate table, the green line with an activated fast locate table.
The diagram above shows that there is no performance improvement if the object is found in the current library. The more steplibs there are involved in object search operations, the higher is the performance improvement. For five steplibs, the program loads require less than half the time.
If the BPSFI
profile parameter is set to OFF, the fast locate table is deactivated
by default. It can be activated or cleared with the application programming
interface USR3004N as described in the section Maintaining the Fast Locate
Table. It is initialized at the start of the Natural
session and it is implicitly cleared when the application is back on Program Level 0
(NEXT prompt).
Activation of the fast locate table for BPSFI=OFF can lead to
unexpected results in the following scenario:
The list of steplibs contains the libraries S1 and S2 whereby S1 is searched before S2.
An object from S2 is accessed during the current Natural session.
Another Natural session copies a new version of this object into S1.
If the application is still running (not back on Program Level 0 in between) and the object is accessed again, the new version of the object will not be used.
If you want to activate the fast locate table when BPSFI=OFF is set,
make sure that the scenario described above cannot occur.
If BPSFI=ON is set, object names should always be unique across all
libraries involved in object search operations. This also guarantees that such
scenarios do not occur.
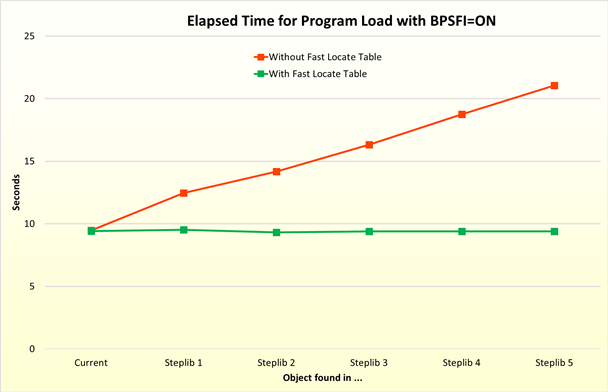
In the following example, a subprogram is called 3,000,000 times. In the first test, the subprogram is found in the current library, then in Steplib 1, Steplib 2, and so on. The red line shows the elapsed time needed for the program load with a deactivated fast locate table, the green line with an activated fast locate table.
The diagram above shows that there is no performance improvement if the object is
found in the current library. The more steplibs there are involved in object search
operations, the higher is the performance improvement. Since the search operation on
the system file is considerably slower than the search in the buffer pool, the
improvement is much higher than the corresponding improvement when
BPSFI=ON set. For five steplibs, the program load is about 20 times
faster. If the fast locate table is activated, in general, the time needed for
subsequent program loads for BPSFI=OFF is about the same as for
BPSFI=ON, and it is always about the time needed to search for an
object in the current library only.
If an object is searched in a (read/write) buffer pool or on the system file, lock operations are issued to ensure that no other session performs changes concurrently. The lock operations serialize the access to the buffer pool, one session is processed after the other.
The fast locate table reduces the number of locate calls if steplibs are involved. Therefore, less lock operations are required, and overall performance of the buffer pool is improved.
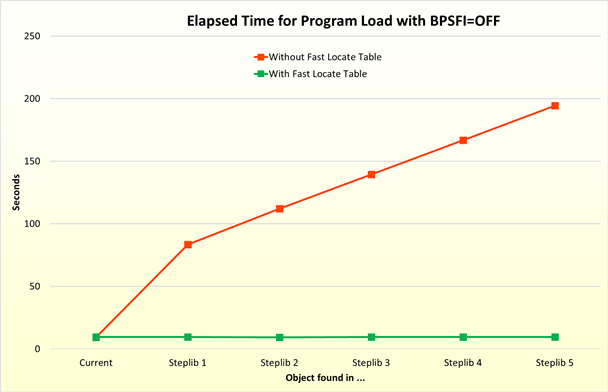
In the following example, a subprogram is called 3,000,000 times, and the subprogram is always found in Steplib 5. In the first test, only one session is active. In the second test, two sessions execute the same application simultaneously, then three sessions, and so on. The red line shows the elapsed time needed for the program load with a deactivated fast locate table, the green line with an activated fast locate table.
As indicated in Performance with
BPSFI=ON, the program load with a single session is more
than 2 times faster if the object is found in Steplib 5 with BPSFI=ON
set. If multiple sessions access the buffer pool simultaneously, the tests show that
the performance can be 3 to 5 times faster.
Usage of the fast locate table can be activated and deactivated by calling the application programming interface (API) USR3004N. The API can also be used to get the current state of the fast locate table, to clear the fast locate table and to receive statistical data. The API is delivered in the SYSEXT library. For more information on using APIs, see the section SYSEXT Utility - Natural Application Programming Interfaces in the Utilities documentation.
 To use API USR3004N
To use API USR3004N
Copy the USR3004N subprogram to the SYSTEM library, to the appropriate steplib library, or to the required library.
The function to be performed by USR3004N requires that the respective
parameter value (ON, OFF, STATE,
CLEAR or COUNT) is specified first in the
CALLNAT statement. The parameter values can be specified in
uppercase or lowercase. On return, P-RETURN contains the return
code, whereby Return Code 0 indicates that the function performed
successfully. All parameters are optional for compatibility with previous
versions of the API on the mainframe.
To activate the fast locate table
Call USR3004N with the following CALLNAT statement:
CALLNAT 'USR3004N' 'ON' P-STATE 2X P-RETURN-CODE
To deactivate the fast locate table
Call USR3004N with the following CALLNAT statement:
CALLNAT 'USR3004N' 'OFF' P-STATE 2X P-RETURN-CODE
To retrieve the current state of fast locate table usage
Call USR3004N with the following CALLNAT statement:
CALLNAT 'USR3004N' 'STATE' P-STATE 2X P-RETURN-CODE
If the P-STATE state field is TRUE, the fast locate
table is used. The state field is returned for each API function.
To clear the fast locate table
Call USR3004N with the following CALLNAT statement:
CALLNAT 'USR3004N' 'CLEAR' P-STATE 2X P-RETURN-CODE
As described in Fast
Locate Table with BPSFI=OFF, unexpected results can
be encountered if the fast locate table is used with BPSFI=OFF.
For BPSFI=OFF, the fast locate table is cleared when the
application is back on Program Level 0 (NEXT prompt). A restart
of the application therefore ensures that the latest version of the object is
found.
Since a server in a client/server environment never reaches Program Level 0,
you can clear the fast locate table by using the CLEAR function
of USR3004N to ensure that the latest version of the object is found.
To receive slot counts of the fast locate table
Call USR3004N with the following CALLNAT statement:
CALLNAT 'USR3004N' 'COUNT' P-STATE P-SLOTS-USED P-SLOTS-TOTAL P-RETURN-CODE
The counters indicate how well the hash function operates. The hash function is used to calculate the slot index number in the fast locate table.
| Field | Description |
|---|---|
P-SLOTS-USED |
Shows the number of slots in the fast locate table
that are currently occupied.
The hash function operates well if this number increases with the number of objects accessed until close to the total number of slots. |
P-SLOTS-TOTAL |
Shows the total number of slots available in the
fast locate table.
The used hash function requires that the total number is a prime number. There are 593 slots available in the fast locate table. |
A read-only buffer pool is a special buffer pool that only allows read access. If an object is not found in the read-only buffer pool, Natural issues error 82 (object not found). As no attempt is made to retrieve the missing object in the system files, all lock operations on the system file as well as on the buffer pool are skipped. Account data are gathered.
A read-only buffer pool is defined in the Configuration Utility (see also Setting up a Buffer Pool below).
The utility NATBPSRV
expects a preload list in a file named
<bufferpool-name>.PRL at the location of the Natural
parameter files, which is defined in the local configuration file (installation
assignments). For example, if the name of the read-only buffer pool is
"ROBP", the file name must be
ROBP.PRL.
A preload list can be generated using the Natural utility CRTPRL. This utility extracts
the contents of a buffer pool and merges it with the existing preload data of a buffer
pool.
The preload list in the PRL file contains records with comma-separated data in the following form:
database-ID,file-number,library,object-name,kind,type
The keywords in the file have the same meaning as the keywords shown by the DIR command of the NATBPMON utility.
With the exception of directory-describing records (the kind of object is
D, which means the object is part of FILEDIR.SAG),
a value must be assigned to all keywords. Examples:
| Keywords | NATBPSRV loads the following into the buffer
pool
|
|---|---|
222,111,MY_LIB,PGM1,G,P |
Object code of program PGM1 from library
MY_LIB which is located on database 222 and file number
111.
|
222,113,*,*,D |
LIBDIR.SAG which is located on
FNAT=222,113.
|
222,111,MY_LIB,*,D |
FILEDIR.SAG from library
MY_LIB which is located on FUSER=222,111 .
|
Using a read-only buffer pool has the disadvantage that the application must be known in detail (as missing objects cannot be loaded). This means that all objects needed by an application must be specified in the preload list. In seldom cases, the complete set of objects needed by an application can be determined in advance.
Natural can run with a read-only buffer pool as the primary buffer pool. Such a
buffer pool is not modifiable. Objects missing in the read-only buffer pool cannot
be loaded. If an object is not found in the read-only buffer pool, Natural issues
error 82 (object not found). To avoid this, Natural can attach during execution to a
secondary standard buffer pool (which allows read/write access) and activate the
missing objects there. If a call to locate an object in the primary buffer pool
fails, the secondary buffer pool operates as a backup buffer pool. The dynamic
parameter BPID2
identifies the secondary buffer pool.
Other than for the read-only buffer pool, object locking through semaphores takes place each time the secondary buffer pool is accessed.
The preload list of the read-only buffer pool can be updated/enhanced by merging
the contents of the secondary read/write buffer pool with the preload list of a
read-only buffer pool using the utility CRTPRL.
For a read-only buffer pool, it is possible to define the name of an alternate buffer pool in the Configuration Utility (see also Setting up a Buffer Pool below).
Using the SWAP command of the NATBPMON
utility, which is only available for a read-only buffer pool, you can tag a
read-only buffer pool as "obsolete". All Natural sessions attached to
an obsolete buffer pool will detach from this buffer pool and will attach to the
alternate buffer pool - but only if the alternate buffer pool is also a read-only
buffer pool. The swap from one buffer pool to the other occurs either when Natural
tries to load a new object (for example, when executing a CALLNAT or
RETURN statement) or when Natural tries to interpret a command which
has been put on the stack. The IPC resources (that is, the shared memory segment) of
a buffer pool tagged as obsolete can be removed after issuing the
SWAP command of the NATBPMON utility. This
feature allows exchanging a buffer and its contents by another read-only buffer pool
with updated contents without stopping Natural sessions.
Known issues: The IPCRM command of the NATBPMON
utility will report an error trying to delete the semaphores associated to a
read-only buffer pool.
The Natural utility CRTPRL, which is located in the library
SYSBPM, is used to create a preload list for a read-only buffer pool.
The utility uses the content of a source buffer pool as the basis for the preload list and checks whether the preload list already exists for a read-only (target) buffer pool:
If the preload list exists, the existing data in the preload list is merged with the data from the source buffer pool, and the preload list is saved with the new content.
If the preload list does not yet exist, it is created using the content from the source buffer pool.
The content of the resulting preload list determines the content of the read-only
buffer pool. The preload list is read by the utility NATBPSRV which loads the
corresponding objects into the read-only buffer pool.
A buffer pool with enhanced performance is a read/write buffer pool that is optimized for performance and scalability. The enhanced performance features are enabled automatically when you start a read/write buffer pool, unless only a runtime license is installed.
The buffer pool with enhanced performance combines the advantages of a read-only and read/write buffer pool.
Like the read-only buffer pool, the buffer pool with enhanced performance does not use locks if only read operations are performed, and read operations do not use locks and read operations from multiple user sessions can be executed concurrently. Therefore, single-session performance matches that of a read-only buffer pool and exceeds that of the traditional read/write buffer pool, due to the reduced number of system calls.
The buffer pool with enhanced performance scales better than the read-only buffer pool and traditional read/write buffer pool. The performance advantage of the buffer pool with enhanced performance increases monotonically with increasing number of concurrent sessions actively using it.
The buffer pool with enhanced performance supports read and update operations. Thus,
although a preload list can be used to seed the buffer pool on startup, its usage is
optional, and even if specified, any objects missing from the list can be loaded later
on demand without having to set up and maintain a secondary buffer pool for this
purpose. Likewise, objects in the buffer pool with enhanced performance can be
directly replaced, implying that application updates can be applied without having to
switch to an alternate buffer pool with the SWAP command,
as is the case with the read-only buffer pool.
The buffer pool with enhanced performance performs fewer update operations on internal data structures due to deferred structural updates that are combined and applied in a later consolidation operation. Furthermore, it only uses locks in conjunction with update operations. This enhances robustness by reducing the risk of a process dying in the middle of updating its data structures and/or while owning the lock.
The buffer pool with enhanced performance supports exclusive access for operations
that need it unlike the read-only buffer pool. The operations that are not
performance-critical, such as attaching to and detaching from the buffer pool, can be
performed on their own, without interference from other users, thus further enhancing
robustness. This function of the buffer pool with enhanced performance depends on the
availability of the exclusive access, which is why it performs and scales better than
the read-only buffer pool. Exclusive access also allows a true snapshot of the buffer
pool status to be obtained via the STATUS command of the
NATBPMON utility. The
displayed statistical information is not modified as they it is gathered. In addition,
the exclusive access is necessary for the VERIFY command,
which is not available for the read-only buffer pool.
The extent to which the performance improvements shown in synthetic benchmarks apply to real-world applications depends on the number of concurrent sessions actively using the buffer pool and the frequency of buffer pool operations. For example, the longer the time spent in a called object (for example a subprogram, external subroutine, or function), the lower the impact of the buffer pool operations on overall performance.
When a buffer pool with enhanced performance is started, the NATBPSRV utility outputs the
information Enhanced performance cache created, for example:
NATURAL/C Buffer Pool 9.3(932) of 07/18/2024 started (internal version 2). Existing shared memory will be deleted. Creation of shared memory completed. Enhanced performance cache created. Existing semaphores will be deleted. Creation of semaphores completed. Permanent IPC resources created. Buffer pool is ready to run. The server process completed successfully.
To check whether an existing buffer pool is a buffer pool with enhanced performance,
attach to it with the NATBPMON utility and issue the
STATUS command. If the output shows information about the
operation type (Read operations, Sync read operations,
Update operations, and Consolidations), the buffer pool is
a buffer pool with enhanced performance. Otherwise, it is a buffer pool that was
started with NATBPSRV utility version 9.3.1 or lower, a read-only buffer
pool, or a standard Natural license could not be found. A standard Natural license
allows installation of the extended environment with additional functionality, while a
runtime license only enables a runtime environment.
When using the Natural buffer pool, only minimum restrictions must be considered:
When a Natural session hangs up, do not initially terminate it by using the
Linux command
kill -KILL (also kill
-9), the terminal command break or the
interrupt key.
If this session is currently performing changes to the buffer pool internal data structures, an interruption may occur at a stage where the update is not fully completed. If the buffer pool internal data structures are inconsistent, this could have negative effects.
Instead, use the Linux command kill -TERM
(also kill -15) to terminate the hung-up session.
Note
This can only happen when the Natural nucleus is executing buffer pool
routines.
All resources must be shared among all users of one Natural buffer pool. Group membership of a process is used to give access rights for the buffer pool. This means that the shared memory can be changed by all group members, but not by anyone else. The same applies to the semaphores.
Note
All users of the same Natural buffer pool must belong to the same user
group on the Linux operating system.
The buffer pool assignments are stored in the local configuration file. To set up a buffer pool, you have to specify specific values in the local configuration file using the Configuration Utility. For a list of these values, see Buffer Pool Assignments in the Configuration Utility documentation.
The buffer pool is created using the utility NATBPSRV.
Note
The utility NATBPSRV should not be accessible to all Natural users,
because it can cause damage to the work of other buffer pool users.
NATBPSRV allocates the resources required by the buffer pool and creates
the permanent communication facilities (that is, shared memory and semaphores) used for
the buffer pool. The necessary specifications for the resources and facilities are made
with the Configuration Utility (see Setting
up a Buffer Pool).
The NATBPSRV utility should only be used during system startup,
from within the startup procedure natstart.bsh.
By default, the buffer pool NATBP is started.
If another buffer pool is to be started, you specify its name with the
following NATBPSRV command line option:
NATBPSRV BP = buffer-pool-name
If NATBPSRV discovers in the process of creating a buffer pool
that a buffer pool of the same name is already active, it deletes the already active
buffer pool. If the deletion fails, NATBPSRV terminates with an appropriate
error message.
NATBPSRV can issue the following error messages if the buffer pool that is
to be created is meant to be a read-only buffer pool:
| Unable to attach to buffer pool. Return code ... received from bp_init. | |
| Explanation |
To load the objects described in the preload list, |
| Action |
Contact Software AG Technical Support. |
| Unable to get parameter path. | |
| Explanation |
The path defined in the local configuration file identifying Natural's parameter files could not be established. |
| Action |
Contact Software AG Technical Support. |
| File ... is not accessible. | |
| Explanation |
The preload list is not accessible or not present. |
| Action |
Revise access rights or create a preload list. |
| Unable to open file ... | |
| Explanation |
The preload list cannot be read. |
| Action |
Re-create preload list. |
| Skipped erroneous record: '...'. Buffer pool may not operate correctly. | |
| Explanation |
An invalid record was found in the preload list. The record is skipped and the load process is continued. There may arise errors in your application due to missing objects. |
| Action |
Correct the record if it has been created manually, or contact Software AG Technical Support. |
| Unable to retrieve LIBDIR.SAG in FNAT(...,...). Application will not run. | |
| Explanation |
LIBDIR.SAG was not found. An application depending on
|
| Action |
Correct the record if it has been created manually, or contact Software AG Technical Support. |
| Buffer pool manager returned with error code ... . Buffer pool is not operational. | |
| Explanation |
FILEDIR.SAG could not be loaded into the buffer pool. The buffer pool is either too small to hold FILEDIR.SAG or FILEDIR.SAG is damaged. The previously listed message tells which FILEDIR.SAG is causing the trouble. |
| Action |
Correct the record if it has been created manually, or contact Software AG Technical Support. |
| Buffer pool manager returned with error code ... . Error ... occurred. | |
| Explanation |
An error occurred loading an object into the buffer pool. |
| Action |
Normally, the size of the buffer pool is too small. Increase its size and repeat the operation. If the problem remains, contact Software AG Technical Support. |
| Object ... in library ... on system file (...,...) not found. Application may not run. | |
| Explanation |
The preload record processed pointed to an object that was not found. This normally happens if an application is modified and the corresponding preload list is not updated. |
| Action |
Remove/revise preload record in question |
| Preload executed. Buffer pool is ready to run. | |
| Explanation |
All preload records were processed. The buffer pool is unlocked and Natural can access that buffer pool. |
The Buffer Pool Monitor is used to oversee the buffer pool's activity during its operation. The Buffer Pool Monitor can also be used to shut down the buffer pool when Natural must be stopped on a computer.
The Buffer Pool Monitor collects information on the current state of your Natural buffer pool.
If multiple buffer pools are active on the same computer and an object that is loaded to more than one buffer pool is modified by a Natural process, the object will only be removed from the buffer pool to which the modifying Natural process is attached.
For detailed information for how to use the Buffer Pool Monitor, see
Using the Buffer Pool Monitor
(NATBPMON).
This section describes problems that may occur when using the Natural buffer pool and how to solve them.
It is assumed that you are familiar with the Linux commands
ipcs and adb.
The following are typical command output examples, with an explanation of what went wrong during execution.
Either Natural or the Natural Buffer Pool Monitor (NATBPMON utility) cannot be started.
The following examples describe the most typical problems you are likely to encounter as a Natural administrator or user. These problems occur when you start Natural or the Natural Buffer Pool Monitor, and the buffer pool is not active.
You try to start Natural with the following command:
natural bp = sag
The following message appears:
Natural Startup Error: 16 Unable to open Buffer Pool, Buffer Pool error: "unexpected system call error occurred " (20) Global shared memory could not be attached.: shmkey = 11111111 Operating System Error 2 - No such file or directory
You try to start the Natural Buffer Pool Monitor with the following command:
natbpmon bp = sag
When you enter the WHO command at the
NATBPMON prompt, the following message appears:
Buffer Pool error: unexpected system call error occurred (20) Global shared memory could not be attached.: shmkey = 11111111 Operating System Error 2 - No such file or directory
Start the buffer pool service as described in Using the Utility NATBPSRV for Creating the Buffer Pool.
Use the Linux command ipcs to verify the existence of
the necessary semaphores and the shared memory:
ipcs -m -s
This results in the following output:
IPC status from /dev/kmem as of Mon 23-MAY-2005 12:03:24.30 T ID KEY MODE OWNER GROUP Shared Memory: m 807 0x4e425031 --rw-rw---- sag natural Semaphores: s 85 0x4e425031 --ra-ra---- sag natural
Note
The above output was edited to exclude memory segments and semaphores that do
not belong to the Natural buffer pool.
If you cannot find a shared memory segment or a set of semaphores with the key you assigned them, the buffer pool was not started.
The Natural buffer pool and a Natural utility are not of the same Natural version.
If a utility tries to use the buffer pool, the utility and buffer pool versions are checked for equality. If they differ, the access is denied and an error message is output.
You try to start Natural and the following message appears:
Natural Startup Error 16: Unable to open buffer pool. Buffer pool error: "Buffer pool does not correspond with your version of Natural"(25). Internal version of buffer pool is 0 but requested internal version is 1.
You try to start the Natural Buffer Pool Monitor and the following message appears:
Buffer pool error: Buffer pool does not correspond with your version of Natural (25). Internal version of buffer pool is 0 but requested internal version is 1.
Verify that your Natural version corresponds to your buffer pool version number and that the internal buffer pool version (BP version) is also correct. Restart the buffer pool with the same version as Natural but make sure that no other users are active.
Important
The internal buffer pool version
number (BP version) can vary in between service pack releases (third
digit of the product version number). For example, a buffer pool that has been
initiated using Natural Version
vrs cannot be used with Natural Version
vr(s+1) and vice versa.
Usually it should not be necessary to shut down and restart the buffer pool. This may only be necessary if the buffer pool should become unusable due to serious internal errors in the buffer pool, which is extremely unlikely to occur, or because the parameters defining the buffer pool structure became obsolete.
If the NATBPMON utility is
still able to access the buffer pool, proceed as follows:
Shut down the buffer pool with the SHUTDOWN command of
the NATBPMON utility.
Once the SHUTDOWN command is executed, new users are
denied access to the buffer pool.
Tip
Active buffer pool users can be monitored by issuing the
WHO and STATUS commands of
the NATBPMON utility.
After the last user has stopped accessing the buffer pool, buffer pool resources
can be deleted by issuing the IPCRM command of the
NATBPMON utility.
To restart the buffer pool, call the file natstart.bsh from a sufficiently privileged account.
If you have super user rights, you can use the
FORCE option of the SHUTDOWN command:
Shut down the buffer pool with the SHUTDOWN FORCE
grace-period command of the
NATBPMON utility.
This command - like the SHUTDOWN command without options
- denies new users access the buffer pool. However, the terminate signal
SIGTERM is sent to all active Natural sessions, forcing them to log
off from the buffer pool.
If the optional parameter grace-period is omitted, this
command waits until all active sessions have performed their shutdown processing and
then executes the IPCRM command of the
NATBPMON utility .
If the optional parameter grace-period has been
specified, NATBPMON waits the specified number of seconds before it
executes its IPCRM command - regardless of the closedown
status of the sessions logged on to the buffer pool. Therefore, the value defined
for the grace period should be sufficiently large to allow the sessions to terminate
in time.
NoteSHUTDOWN FORCE 0 is the same as SHUTDOWN
FORCE (without the parameter
grace-period).
To restart the buffer pool after successful execution of the SHUTDOWN
FORCE command, call the file natstart.bsh from a sufficiently privileged
account.
If the NATBPMON utility is not able to perform a clean shutdown of the
buffer pool, the buffer pool must be deleted by using operating system commands:
Use the Linux command ipcs to find out the status of the
buffer pool's shared memory and semaphores:
ipcs -a -m
In the column NATTCH of the output of an ipcs -m
-a command, you can see the number of processes currently attached
to a shared memory segment. For example:
IPC status from /dev/kmem as of Mon May 23 12:15:38.39 2002 T ID KEY ... OWNER GROUP ... NATTCH SEGSZ Shared Memory: m 707 0x4e425031 ... sag natural ... 7 153600
It is highly probable that the number of processes attached to shared memory
incorporates a Natural nucleus or the NATBPMON utility currently
running. Inform the users who run these processes and ask them to terminate their
sessions or terminate them yourself by using the Linux command
kill once you have found out their process IDs using
the ps command.
Once you are sure that no one is using the buffer pool for important work, its
resources can be deleted by using the Linux command
ipcrm. For example:
ipcrm -M 0x4e425031 -S 0x4e425031
The values specified for the -M and -S options must be
those that were specified inside the parameter file used to start the buffer pool.
Be careful when you delete shared memory and semaphores using the Linux command
ipcrm. If you accidentally delete the wrong resource,
this might have a serious impact on other software products running on your
computer.
The result of deletion can be verified by using the Linux command
ipcs again.
If there are still some memory segments or message queues displayed, they could belong to other software, or they are marked for deletion because some other process is still attached to them.
If the buffer pool cannot be started after removing the shared memory and semaphores, you should consider either rebooting your computer or contacting Software AG Support.
