This document covers the following topics:
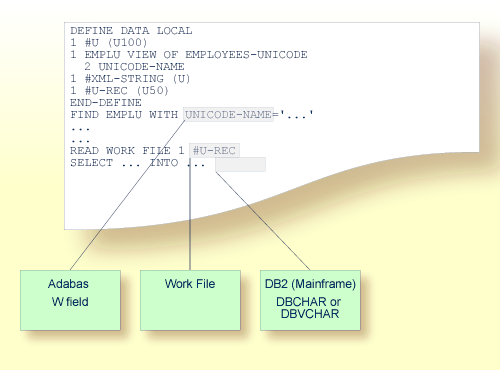
The following graphic shows how Unicode data and parameters are accessed.
The following topics are covered below:
Natural enables users to access wide-character fields (format W) in an Adabas database.
- Data Definition Module
Adabas wide-character fields (W) are mapped to the Natural data format U (Unicode).
- Access Configuration
Natural receives data from Adabas and sends data to Adabas using UTF-16 as common encoding.
This encoding is specified with the
OPRBparameter and is sent to Adabas with the open request. It is used for wide-character fields and applies to the entire Adabas user session.
For detailed information, see Unicode Data in the Accessing Data in an Adabas Database part of the Programming Guide.
Natural enables users to access CHAR and/or
WCHAR fields in a DB2 database as Unicode data.
See also Natural for DB2 in the Database Management System Interfaces documentation.
The following topics are covered below:
No special consideration is given to Unicode data when writing or reading work files. Like all other data types, Unicode data is written and read as is, without conversion.
When sending Unicode data to print files, one or two conversion steps take place.
In a first step, Unicode data contained in a print line is converted to the default code page of the session. As a consequence, all characters which are not contained in this default code page are replaced with the substitution character.
Before passing this converted print line to the actual print access
method, it is additionally checked whether a code page has been specified for
the logical printer. This may have been accomplished with the
CODEPAGE operand of the
DEFINE
PRINTER statement or the CP
subparameter of the PRINT parameter. If such a code page
has been given, the whole print line (not only the Unicode part of it) is
converted accordingly in a second step.
The converted print line is passed to the access method, which means that print access methods do not receive Unicode data.
Example:
DEFINE PRINTER (1) CODEPAGE 'IBM01140' WRITE (1) 'HELLO' U'WORLD' END