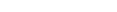
|
|
|
|
|
|
[FILE]
work-file-number [ONCE]
|
||||||||||
|
|
RECORD
operand1
|
|
|||||||||||||
[AND] [SELECT]
|
|
|
|
|
operand2 |
|
|||||||||
[GIVING LENGTH operand3]
|
|||||||||||||||
[AT [END] [OF] [FILE]
statement END-ENDFILE]
|
|||||||||||||||
|
statement
|
|||||||||||||||
END-WORK
|
|||||||||||||||
|
|
|
|
|
|
[FILE] work-file-number [ONCE]
|
||||||
|
|
RECORD
{operand1 [FILLER
nX]}
|
|
|||||||||
[AND]
[SELECT]
|
|
|
|
|
operand2 |
|
|||||
[GIVING
LENGTH operand3]
|
|||||||||||
|
|
AT [END] [OF] [FILE]
|
|
|||||||||
|
statement
|
|||||||||||
LOOP |
|||||||||||
This document covers the following topics:
For an explanation of the symbols used in the syntax diagram, see Syntax Symbols.
Related Statements: CLOSE PC
FILE | DOWNLOAD PC
FILE | READ WORK
FILE
Belongs to Function Group: Control of Work Files / PC Files
The UPLOAD PC FILE statement is used to transfer data from
a PC to a mainframe platform.
See also:
Natural Connection and Entire Connection documentation
READ WORK FILE
statement syntax description
Operand Definition Table:
| Operand | Possible Structure | Possible Formats | Referencing Permitted | Dynamic Definition | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
operand1
|
S | A | G | A | U | N | P | I | F | B | D | T | L | C | yes | yes | ||
operand2
|
S | A | G | A | U | N | P | I | F | B | D | T | L | C | yes | yes | ||
operand3
|
S | I | yes | yes | ||||||||||||||
Format C is not valid for Natural Connection.
Syntax Element Description:
| Syntax Element | Description |
|---|---|
work-file-number
|
Work File Number:
The number of the work file to be used. This number must correspond to one of the work file numbers for the PC as defined to Natural. |
operand1-2
|
Field Specification:
With |
statement
|
Statement(s) to be Executed:
In place of No I/O statement may be placed with the |
ONCE, SELECT, GIVING LENGTH
|
Options:
For a description of the The When uploading data: If you wish to define a filler, you must use a dummy variable instead of the standard filler notation. |
END-WORK |
End of UPLOAD PC FILE Statement:
In structured mode, the Natural reserved keyword
In reporting mode, the Natural statement |
LOOP |
The following program demonstrates the use of the UPLOAD PC
FILE statement. The data is first uploaded from the PC and then
processed on the mainframe.
** Example 'PCUPEX1': UPLOAD PC FILE
**
** NOTE: Example requires that Natural Connection is installed.
** CAUTION: Executing this example will modify the database records!
************************************************************************
DEFINE DATA LOCAL
01 EMPL VIEW OF EMPLOYEES
02 PERSONNEL-ID
02 INCOME
03 SALARY (1)
*
01 #PID (A8) /* Personnel ID on PC
01 #NEW-INCREASE (N4) /* Increase for salary
END-DEFINE
*
UPLOAD PC FILE 7 #PID #NEW-INCREASE /* Data upload
*
FIND EMPL WITH PERSONNEL-ID = #PID /* Data selection
ADD #NEW-INCREASE TO SALARY (1) /* Data update on host
UPDATE
END TRANSACTION
ESCAPE BOTTOM
END-FIND
*
END-WORK
END
When you run the program, a window appears in which you specify the name of the PC file from which the data is to be uploaded. The data is then uploaded from the PC.