This document covers the following topics:
The development environment for Unicode applications is Natural Single Point of Development (SPoD).
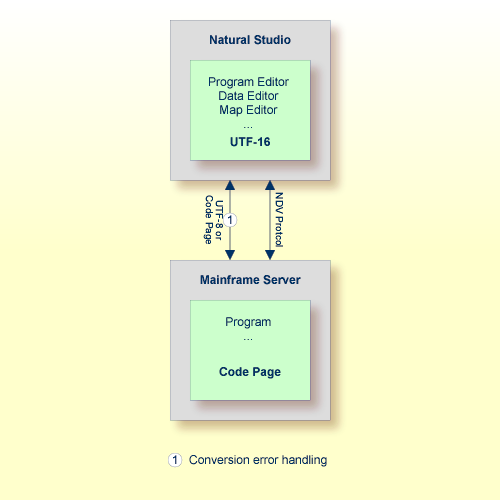
In a SPoD environment, the Natural objects of a Unicode application which are located on a Natural Development Server (NDV) can be modified using Natural Studio. If supported by the server, the sources are exchanged between client and server in UTF-8 format.
On NDV servers, the objects are stored with
the default or their original encoding, depending on the setting of the profile parameter
SRETAIN.
If the parameter SRETAIN is set to OFF, all sources
are saved with the default code page. You have to be careful with this setting because it
may lead to improper code page information if you have sources which were created with an
earlier Natural version. In this case, the encoding information of the source is
unassigned and the source is always opened with the default code page (value of the system
variable *CODEPAGE). This will often work even if the
default code page is not the correct encoding of the source. Some language-specific
characters will be displayed incorrectly in this case. If such a source is opened with the
wrong code page and is saved with SRETAIN being set to
ON, no encoding will be stored for the source; the source can later be
opened correctly if Natural is started with the correct default code page. However, once
you have saved the source with SRETAIN being set to
OFF, the default code page will be saved as the encoding of the source;
from this time on, the source will only be opened with this code page. For this reason,
you should use this setting only if you are certain that all of your Natural sources are
encoded in the default code page.
The Natural for Windows editors are fully Unicode-enabled. Via SPoD they can also be used for mainframe sources. The editors provided with Natural for Mainframes are not Unicode-enabled.
Note
The editors provided with Natural for Mainframes provide code page support.
See Code Page Support for Editors, System
Commands and Utilities on the Mainframe.
When a source is opened with an editor in Natural Studio (Natural for Windows), the content of the source will be converted from the corresponding code page to Unicode before it is loaded into the editor. This will guarantee that all characters can be displayed correctly even if the source contains characters which are not included in the system code page. If the conversion from the source's code page to Unicode fails, an error will be displayed and the editor is not opened. In this case, the user has to define the correct encoding of the source. The source encoding can be changed in the Properties dialog box (see Properties for the Nodes in the Using Natural Studio documentation).
Using the Natural for Windows program editor, you can convert text constants into their hexadecimal Unicode representations (see Converting to Hexadecimal Format in the Program Editor section of the Natural for Windows Editors documentation). If you are developing for a platform where UTF-8 sources are not preferred, you can thus enter all characters for a Unicode constant, select all the characters of the constant, convert them to their hexadecimal representation and then add the "UH" prefix for Unicode hexadecimal constants. Furthermore, when you hover the mouse pointer over a character or a selected character range of a text constant, a tool tip shows the corresponding hexadecimal Unicode representation.
The following topics are covered below:
The program, map and data area editors are not Unicode-enabled. Instead the sources are
stored with code page information. According to the setting of the profile parameter
SRETAIN,
Natural sources with code page information may be converted automatically from the
current code page of the source into the default code page of the current Natural
session (value of the system variable *CODEPAGE) if the source is loaded into the
editor. If there are any characters that cannot be converted, a window displays a code
point conversion error and asks for substitute values for those code points that cannot
be converted. The display of this message is independent from the current setting of the
parameter CPCVERR. In this case, the user can decide to open
the editor with or without converting the source into the default code page. Saving or
stowing a converted source will save the new code page information. Sources without code
page information (for example, sources that have been saved or stowed with previous
Natural versions) are loaded into the editors without any conversion. According to the
setting of the profile parameter SRETAIN, the current code page
information of the source will be retained.
Inserting sources with the .I command or the split screen
function will also convert sources, if necessary, according to the setting of the
profile parameter SRETAIN. If characters cannot be converted, the
defined substitution character will be inserted instead.
The check and conversion of the source is performed when the editor is started, not
when the program is loaded into the source area. If a program is executed via
RUN program-name, a conversion
is not performed. This causes different behavior, depending on whether RUN
program-name is entered on the
NEXT screen or on an editor screen. If RUN
program-name is entered on the
NEXT screen, no conversion follows; if it is entered on an editor screen,
the editor is started right after the execution of the program and a conversion is
performed.
See the table below for the code page that is assigned to an existing Natural source
that is saved or stowed, depending on the values of the profile parameters SRETAIN and CP.
| Original Source Code Page Information | Setting of SRETAIN |
Source Code Page Information after
SAVE or STOW if
CP is Set to a Value other than
OFF |
Source Code Page Information after
SAVE or STOW if
CP is set to OFF |
|---|---|---|---|
| Source without code page information |
SRETAIN=ON SRETAIN=(ON,EXCEPTNEW) |
No code page information | No code page information |
| Source without code page information |
SRETAIN=OFF |
Code page resulting from evaluation of
CP |
No code page information |
| Source is encoded in code page 1 |
SRETAIN=ON SRETAIN=(ON,EXCEPTNEW) |
Original code page (code page 1) | Original code page (code page 1) |
| Source is encoded in code page 1 |
SRETAIN=OFF |
Code page resulting from evaluation of
CP |
Original code page (code page 1) |
The table below shows the code page that is assigned to a new Natural source that is
saved or stowed, depending on the values of the profile parameters SRETAIN and CP.
Setting of SRETAIN |
Source Code Page Information after
SAVE or STOW if
CP is Set to a Value other than
OFF |
Source Code Page Information after
SAVE or STOW if
CP is set to OFF |
|---|---|---|
SRETAIN=ON |
Code page resulting from evaluation of
CP |
No code page information |
SRETAIN=OFF |
Code page resulting from evaluation of
CP |
No code page information |
SRETAIN=(ON,EXCEPTNEW) |
No code page information | No code page information |
By default, the system command LIST displays sources as they are stored in
the system file without any conversions.
The CONVERTED
option of the LIST command converts the source into the
default code page (value of the system variable *CODEPAGE)
if the code page information of the source is provided. All non-convertible characters
are then replaced by the defined substitution character.
The system command LIST DIR shows the used code page
information of a Natural source in the directory window.
Similar to the editors, the system command SCAN converts the sources before executing
the actual SCAN command.
The Object Handler unloads and loads sources with different code page information and preserves the original code page information.
The transfer format option UTF-8 converts sources from any code page to UTF-8 format while unloading, and stores information about the original code page in the work file. The corresponding load function converts the source back to the original code page or to another code page, if specified. This option can also be used to provide code page information for sources which have been saved or stowed with previous Natural versions and which therefore do not contain any code page information.
Unload and load sources in internal format will keep the code page information, if available.
The SYSCP utility can be
used to obtain information on code pages and to check or change the code page
assignment of a source.
The Natural compiler, the editors and the Natural system file do not support object sources that are encoded in Unicode. Unicode constants coded in an object source are saved in the default code page, and the cataloged object contains the Unicode code points. The only way to define Unicode constants which do not have an equivalent in the default code page is to use hexadecimal definitions (UH).
Since Natural sources are not converted to Unicode or UTF-8 before saving, they can still be read by previous Natural versions. Code page information is stored in the header of the source. The code page information in the header is simply ignored if a source is accessed by a Natural version which is not code page enabled.
These object sources are not stored in Unicode format but in the default code page of the current Natural session. The name of the code page is stored in the directory of the source. Therefore, as compared to previous Natural versions, the size of a source remains unchanged. But there is a check by the editor whether the code page of the source is equal to the default code page of the Natural session. If the code pages are different, the source is converted into the default code page with the possibility of conversion errors. If a character of the source is not mapped in the default code page, a window appears in the editor to allow manual conversion of the failed characters. For example, a program which has been created with code page IBM01140 contains the following line:
WRITE '100 €'
If the program is edited again with Natural running with code page IBM037, a conversion error occurs since the character "€" is not mapped in code page IBM037.
Note that the conversion is done when the editor is started and not when the source is loaded.
DDMs are not stored in Unicode format but in the default code page of the current Natural session. The name of the code page is stored in the directory of the DDM. Note that there is no DDM on the system file. As compared to previous Natural versions, the size of a DDM increases slightly. When reading a DDM, there is a check by the editor whether the code page of the DDM is equal to the default code page of the Natural session. If the code pages are different, the DDM is converted into the default code page with the possibility of conversion errors. If a character of the DDM is not mapped in the default code page, a window appears in the editor to allow manual conversion of the failed characters. For example, a DDM which has been created with code page IBM01140 contains the following line:
* 100 €
If the DDM is edited again with Natural running with code page IBM037, a conversion error occurs since the character "€" is not mapped in code page IBM037.
Natural error messages are not stored in Unicode format but in the default code page of
the current Natural session. The name of the code page is stored in an additional Adabas
field on the system file. There is a check by the SYSERR utility and by
user exits whether the code page of the error message is equal to the default code page
of the Natural session. If the code pages are different, the error message is converted
into the default code page. Errors will be ignored - this means, the substitution
character (or if defined, the place holder character) will be used.
Help texts are always maintained with code page IBM01140 (English). They are not stored with a code page definition. If the default code page of the Natural session is not IBM01140, the help text is converted into the default code page. Errors will be ignored - this means, the substitution character (or if defined, the place holder character) will be used.
