Partitioning strategies
Using the patterns and tools described in this guide it is possible to configure the arrangement of multiple contexts within a single correlator or multiple event correlators within Apama (the engine topology). It is important to understand that the appropriate engine topology for an application is firmly dependent on the partitioning strategy to be employed. In turn, the partitioning strategy is determined by the nature of the application itself, in terms of the event rate that must be supported, the number of contexts, spawned monitors expected and the inter-dependencies between monitors and events. The following examples illustrate this.
The stockwatch sample application (in the samples\monitorscript folder of your Apama installation directory) monitors for changes in the values of named stocks and emits an event should a stock of interest fall below a certain value. The stocks to watch for and the prices on which to notify are set up by initialization events, which cause monitors that contain the relevant details to be spawned. In this example, the need for partitioning arises from a very high event rate (perhaps hundreds of thousands of stock ticks per second), which is too high a rate for a single context to serially process.
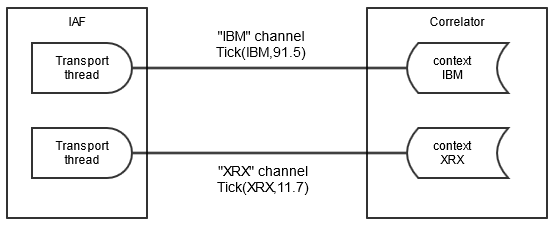
A suitable partitioning scheme here might be to split the event stream in the adapter, such that different event streams are sent on different channels. The illustration below shows how this can be accomplished:
This diagram shows an adapter sending events to different channels based on the symbol of the stock tick. The adapter transport configuration file would specify a transportChannel attribute for the stock event that named a field in the NormalisedEvent that specified the stock symbol. Either a thread per symbol or a single thread (which could become a bottleneck) managed by the transport, depending on what the system the transport is connecting to allows, is used to send NormalisedEvents to the semantic mapper to be processed. The IAF thus sends the events on the channel in the stock symbol value in the NormalisedEvent.
In this example, the stock symbol is either IBM or XRX. The IAF will send events to all sinks (typically one) that are specified in the IAF's configuration file. In the correlator, all monitors interested in events for a given symbol would need to set up listeners in a context where a monitor has subscribed to that symbol. To achieve good scaling, the application is arranged so that each context is subscribed to only one symbol. For the stockwatch application, a separate context per symbol would be created, and the stockwatch monitor spawns a new monitor instance to each context. In each context, the monitor instance would execute monitor.subscribe(stockSymbol); where stockSymbol would have the value "IBM" or "XRX" corresponding to the stock symbol it is interested in. This application will scale well, as each event stream (for the different stock symbols) can run in parallel on the same host; this is referred to as scale-up.
Listeners in each context would listen for events matching a pattern, such as on all Tick(symbol="IBM", price < 90.0) .
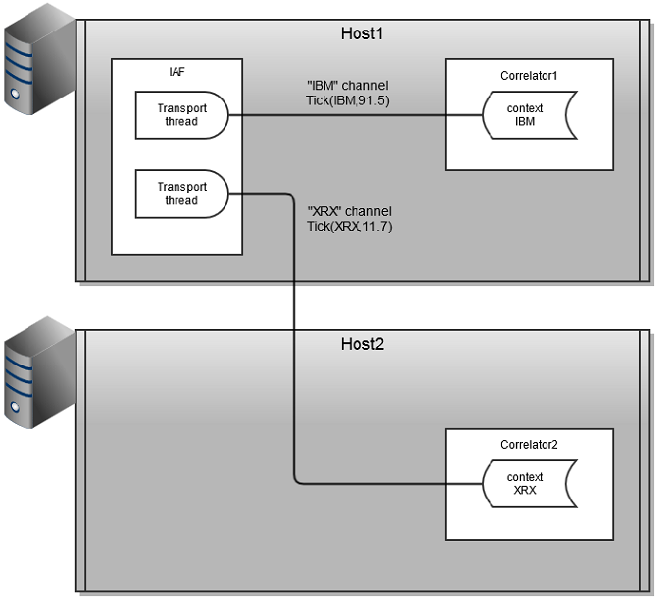
If the number of stock symbols is very large and the amount of processing for each stock symbol is large, then it may be required to run correlators on more than one host to use more hardware resources than are available in a single machine. This is referred to scale-out. To achieve scale-out, connections per channel need to be made between the Apama components using the engine_connect tool (or the equivalent call from Ant macros or the client API). The engine_connect tool can connect any two Apama components, either correlator to correlator, or IAF to correlator. For best scaling, multiple connections are required between components, which engine_connect provides in the parallel mode. The following image shows a scaled out configuration.
This configuration allows many contexts to run on two hosts and requires use of engine_connect to set up the topology.
Now consider a portfolio monitoring application that monitors portfolios of stocks, emitting an event whenever the value of a portfolio (calculated as the sum of stock price * volume held) changes by a percentage. A single spawned monitor manages each portfolio and any stock can be added to/removed from a portfolio at any time by sending suitable events.
This application potentially calls for significant processing with each stock tick, as values of all portfolios containing that stock must be re-calculated. If the number of portfolios being monitored grows very large, it may not be possible for a single context to perform the necessary recalculations for each stock tick, thus requiring the application to be partitioned across multiple contexts.
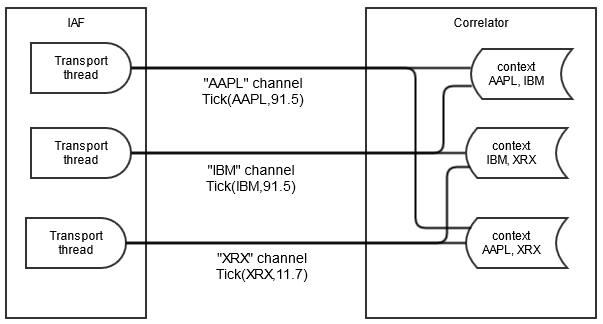
Unlike the stockwatch application, it is not possible to achieve scaling to larger numbers of portfolios by splitting the event stream. Each portfolio can contain multiple stocks, and stocks can be dynamically added and removed, thus one event may be required by multiple contexts. In this case, a suitable partitioning scheme is to partition the monitor instances across contexts (as with stockwatch) but to duplicate as well as split the event stream to each event correlator. The following images shows the partitioning strategy for the portfolio monitoring application.
Again, each monitor instance is spawned to a new context and subscribes to the channels (stock symbols in this application) that it requires data for. Note that while the previous example would scale very well, this will not scale as well. In particular, if one monitor instance requires data from all or the majority of the channels, then it can become a bottleneck. However, there may be multiple such monitor instances running in parallel if they are running in separate contexts.
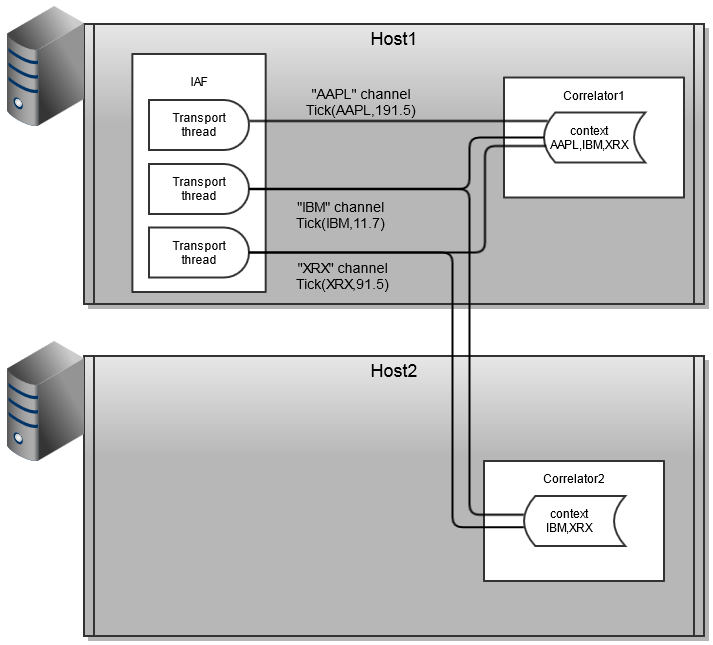
Similar to the stockwatch application, the portfolio monitoring application may require scale-out across multiple hosts, as shown below.
In summary, the partitioning strategy can be thought of as a formula for splitting and duplicating monitors and/or events between event correlators while preserving the correct behavior of the application. In some circumstances, it may be necessary to re-write monitors that work correctly on a single correlator to allow them to be partitioned across correlators, as the following section describes.