dictionary
A dictionary is a means of storing and retrieving data based on an entry key. This enables, for example, a user’s name to be retrieved from a unique user ID.
The syntax of a dictionary definition is:
dictionary < key, item > varname
Dictionaries are dynamic and new entries can be added and existing entries deleted as desired.
The dictionary key must be a comparable type. See
Comparable types.
The item can be any Apama type.
Two dictionaries are equal only if they contain the same keys and the same value for each key. When dictionaries are not equal they are ordered as though they were sequences of key-value pairs, sorted in key order.
Example
// A simple stock dictionary, each stock’s name is gained and
// stored from a numerical key
//
dictionary< integer, string > stockdict;
// A dictionary that can be used to store the number of times
// that a given event is received
//
dictionary< StockChoice, integer > stockCounterDict;
Note that a dictionary of sequences or dictionarys is supported. Care must be taken in how these are specified by separating trailing > characters with whitespace, to distinguish them from the right-shift operator >>. For example:
// A correctly specified dictionary containing sequence elements
dictionary< integer, sequence<float> > willWork;
// An incorrectly specified dictionary containing sequence elements
// dictionary< integer, sequence<float>> willNotWork;
A global variable of type dictionary is initialized by default to an empty instance of the type defined. On the other hand, a local variable must be explicitly initialized using the new operator, as follows:
dictionary<integer, string> stockdict;
stockdict := new dictionary <integer, string>;
It is also possible to both declare and populate a variable of type dictionary as a single statement, regardless of the scope in which the variable is declared, as follows:
dictionary<integer, string> stockdict := {1:"IBM", 2:"MSFT", 3:"ORCL"};
using {} to delimit the dictionary, a comma , to delimit individual entries, and a colon : to separate keys and values.
Dictionary types do not allow duplicate keys. Ensure that you do not specify duplicate keys when initializing a dictionary or in a string that will be parsed to produce a dictionary.
A
dictionary variable can be a potentially cyclic type — a type that directly or indirectly refers to itself. For details about the behavior of such objects, see
Potentially cyclic types.
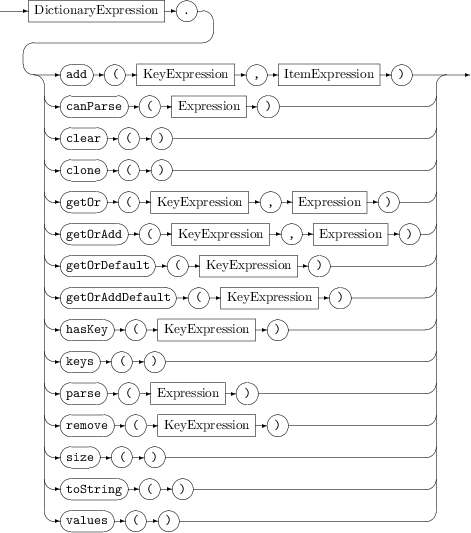
Methods
The methods available on the dictionary data structure are:
DictionaryMethods
 add(key, item)
add(key, item) – add an entry to the dictionary. The first parameter is an expression whose type is the same type as the dictionary’s key type and which becomes the entry’s key. The second parameter is an expression whose type is the same type as the dictionary's item type and whose value becomes the entry’s item value. The key expression is evaluated first, then the item expression. There is no return value. For example:
stockdict.add(71, "ACME");
When you are adding an entry and the key you specify already exists in the dictionary, the correlator replaces the item already in the dictionary with the new item.
canParse() — this method is available only on dictionaries where the item type is parseable. Returns
true if the string argument can be successfully parsed to create a dictionary object. For more information about the parseable type property, see the table in
Type properties summary.
clear() – sets the size of the dictionary to 0, deleting all entries. Takes no parameters. Returns no value.
clone() – returns a new
dictionary that is an exact copy of the
dictionary. All the
dictionary’s contents (both keys and items) are cloned into the new
dictionary, and if the items were complex types themselves, their contents are cloned as well.
When the dictionary you are cloning is a potentially cyclic type, the correlator preserves multiple references, if they exist, to the same object. That is, the correlator does not create a separate copy of the object to correspond to each reference. See also
Potentially cyclic types.
getDefault(key, item) – Before Apama 5.0, the
getOr() method was called
getDefault(). You should not use the
getDefault() method. It remains only for backwards compatibility, it is deprecated, and it will be removed in a future release. Use the
getOr() method instead.
getOr(key, alternative) – returns the item that corresponds to the specified key. If the specified key is not in the dictionary, the
getOr() method returns
alternative. The benefit of calling this method is that if you were to call
dictionary[key] instead of
dictionary.getOr() and the key you were trying to look up did not exist, the correlator would terminate the monitor instance.
The getOr() method lets you avoid a call to the hasKey() method before you look up a key.
For example, suppose you have the following dictionary:
dictionary<integer,string> integerSqrts := {
1:"one", 4:"two", 9:"three", 16:"four", 25:"five", 36:"six",
49:"seven", 64:"eight", 81:"nine", 100:"ten" };
Now suppose you call the following method:
integerSqrts.getOr(key, "irrational")
Assume that you specify a key that is in the range of 1 - 100. If the value of the key is a square of an integer, getOr() returns the written form of the key's square root. For any other key value, getOr() returns "irrational".
getOrDefault(key) – retrieves an existing item by its key or returns a default instance of the dictionary's item type if the dictionary does not contain the specified key.
The getOrDefault() method lets you avoid a call to the hasKey() method before you look up a key.
getOrAdd(key, alternative) – retrieves an existing item by its key or adds the specified key to the dictionary with
alternative as its value if it is not already present and also returns the specified alternative.
The getOrAdd() method lets you avoid a call to the hasKey() method before you look up a key. If the item type is complex, a call to the getOrAdd() method can be more efficient than a call to the getOr() method, because it will not construct a default item unless necessary.
getOrAddDefault(key) – retrieves an existing item by its key or, if it is not already present, adds the specified key with a default instance of the dictionary's item type and returns that instance.
For example, suppose you want to maintain a record of which client companies each sales representative handles. You might write:
dictionary<string, sequence<string> > representing := {};
representing.getOrAddDefault("Sue").append("We-Haul");
representing.getOrAddDefault("Joe").append("McDonuts");
representing.getOrAddDefault("Sue").append("ACME");
The first time getOrAddDefault() is called with key "Sue", that key does not exist yet, so it is added with an empty sequence as the item. That empty sequence is then returned, so "We-Haul" can be appended to it. The second time getOrAddDefault() is called with key "Sue", the existing sequence (containing "We-Haul") is returned, so "ACME" can be appended to it.
This idiom is considerably simpler and more efficient than testing hasKey() and then either adding or retrieving.
hasKey(key) – returns
true if a key exists within the dictionary,
false otherwise. Takes one parameter, which is an expression whose type is the same as the referenced dictionary's key type and whose value is the key value whose presence in the dictionary is tested.
For example: stockdict.hasKey(71)
keys() – returns a
sequence of the dictionary’s keys sorted in ascending order. This will be a
sequence of the same type as the key type of the dictionary. The primary purpose of this method is to enable one to iterate over a dictionary’s contents by looping through the sequence of its keys, as follows;
integer k;
for k in stockdict.keys() {
myString := stockdict[k];
}
The keys() method performs a deep copy (like the clone() method) of the dictionary keys into a sequence; that is by value as opposed to by reference. This behavior ensures that the result of keys() is a consistent view of the dictionary's keys at the time keys() was called, regardless of whether entries were added to or removed from the dictionary while examining the result of keys(). This also ensures that the dictionary keys themselves cannot be modified by changing the sequence.
parse() – this method is available only on dictionaries where the item type is parseable. Returns the
dictionary object represented by the
string argument. For more information about the parseable type property, see the table in
Type properties summary. You can call this method on the
dictionary type or on an instance of a
dictionary type. The more typical use is to call
parse() directly on the
dictionary type.
The
parse() method takes a single string as its argument. This string must be the string form of a
dictionary object. The string must adhere to the format described in
Deploying and Managing Apama Applications,
Event file format. For example:
dictionary<string, integer> d := {};
d := dictionary<string, integer>.parse("{\"foo\":1, \"bar\":2}");
You can specify the parse() method after an expression or type name. If the correlator is unable to parse the string, it is a runtime error and the monitor instance that the EPL is running in terminates.
When a dictionary is a potentially cyclic type , the behavior of the
parse() method is more advanced. See
Potentially cyclic types.
remove(key) – remove an entry by key. Takes one parameter, which is an expression whose type is the same as the referenced dictionary's
key type and whose value is the value of the key of the entry to be removed. The
remove() method does not return a value. If the
key value is not present in the referenced dictionary, a runtime error is raised.
For example: stockdict.remove(71);
size() – returns as an
integer the number of elements in the dictionary. Takes no parameters.
toString() – converts the entire dictionary in ascending order of key values to a
string. This will create a string that contains all the elements enclosed within curly braces,
{ }, separated by commas,
,, with each element consisting of the key followed by an item, the two being separated by a colon,
:.
That is,
{key1:item1, ... ,keyn:<itemn>}
The string is constructed by invoking the toString() method on each of the referenced dictionary's key/value pairs and catenating them into the result.
When a dictionary is a potentially cyclic type, the behavior of the
toString() method is different. See
Potentially cyclic types.
values() – returns a
sequence of the dictionary’s items sorted in ascending order of keys. The order of the items in the returned sequence is the order returned by the dictionary's
keys() method. The
sequence contains items that are the same type as the item type in the dictionary. The primary purpose of this method is to let you iterate over a dictionary’s contents by looping through the sequence of its item values, as follows;
string v;
for v in stockdict.values() {
myString := v;
}
The values() method performs a shallow copy of the dictionary items, that is, if the items are of a reference type the returned sequence contains references to the dictionary’s items rather than clones of them. This behavior ensures that a change to an object in the dictionary is reflected in the returned sequence and a change to an object in the sequence is reflected in the dictionary.
[key]– retrieve or overwrite an existing item by its key, or create a new item.
For example, stockdict[71] := "XRX";
If you are using [key] to write and if an item with the key key does not exist, the correlator creates it. If you are using [key] to retrieve and if an item with the key key does not exist, it is a runtime error.