Partitioning strategies
Using the tools and libraries described in this guide it is possible to configure the arrangement of multiple event correlators within Apama (the engine topology). It is important to understand that the appropriate engine topology for an application is firmly dependent on the partitioning strategy to be employed. In turn, the partitioning strategy is determined by the nature of the application itself, in terms of the event rate that must be supported, the number of monitors and/or spawned monitors expected and the inter-dependencies between monitors and events.
To illustrate this we will consider two examples.
The ‘Stockwatch’ sample application monitors for changes in the values of named stocks and emits an event should a stock of interest fall below a certain value (see samples\monitorscript\stockwatch in the directory where Apama is installed). The stocks to watch for and the prices on which to notify are set up by initialization events, which cause monitors to be spawned, containing the relevant details. In this example we assume the need for partitioning arises from a very high event rate (say hundreds of thousands of stock ticks per second) – too high a rate for a single event correlator to process in a sustainable fashion.
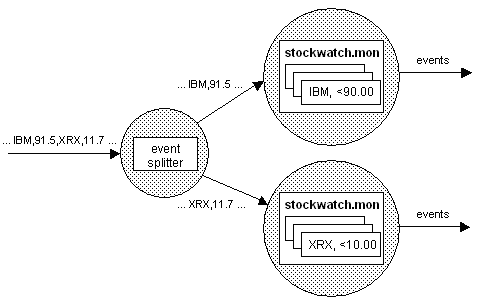
A suitable partitioning scheme here might be to split the event stream, such that a single event correlator processes only subsets of the events. The illustration below shows how this can be achieved, with the event stream split between two event correlators, each of which contains a duplicate of the original stockwatch monitor.
Partitioning strategy for the stockwatch application
The diagram above illustrates partitioning of the event stream on the basis of stock symbol. In this scheme the spawned monitors, which are looking for a specific stock/price combination, reside on the correlator to which events for that stock are sent (else relevant events will be missed).
In the case of Stockwatch, this is achieved by splitting the initialization events that set up the spawned monitors using identical criteria as those used to split the stock tick events themselves, and by duplicating the stockwatch monitor on each of the correlators involved. So in figure 1, the event that causes spawning of a monitor to detect the stock price of IBM falling below $90 is sent to the event correlator that receives IBM stock tick events.
In the second example we will consider a portfolio monitoring application that monitors portfolios of stocks, emitting an event whenever the value of a portfolio (calculated as the sum of stock price * volume held) changes by a percentage. We assume a single spawned monitor manages each portfolio, and any stock can be added to/removed from a portfolio at any time by sending suitable events.
This application potentially calls for significant processing with each stock tick, as values of all portfolios containing that stock must be re-calculated. If the number of portfolios being monitored grows very large, it may not be possible for a single event correlator to perform the necessary recalculations for each stock tick, thus requiring the application to be partitioned across multiple correlators.
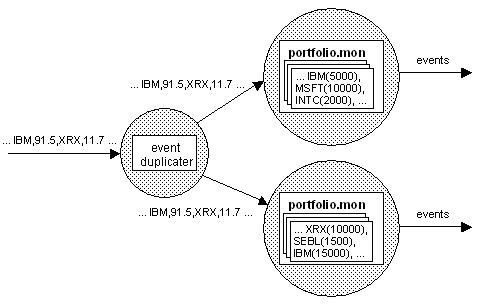
Unlike the stockwatch application, it is not possible to achieve scaling to larger numbers of portfolios by splitting the event stream. Each portfolio can contain any stock, and stocks can be dynamically added and removed, thus it cannot be predicted which events a monitor will need to see during its lifetime. In this case, a suitable partitioning scheme is to partition the monitors across correlators (as with stockwatch) but to duplicate rather than split the event stream to each event correlator. This is illustrated below.
Partitioning strategy for the portfolio monitoring application
In summary, the partitioning strategy can be thought of as a formula for splitting and duplicating monitors and/or events between event correlators whilst preserving the correct behavior of the application. In some circumstances, it may be necessary to re-write monitors which work correctly on a single correlator to allow them to be partitioned across correlators, as the following section describes.
Copyright © 2013
Software AG, Darmstadt, Germany and/or Software AG USA Inc., Reston, VA, USA, and/or Terracotta Inc., San Francisco, CA, USA, and/or Software AG (Canada) Inc., Cambridge, Ontario, Canada, and/or, Software AG (UK) Ltd., Derby, United Kingdom, and/or Software A.G. (Israel) Ltd., Or-Yehuda, Israel and/or their licensors.