Executing HTTP requests concurrently
Enabling concurrency
By default, the HTTP client executes requests serially and in order. As a result, the maximum throughput that can be achieved is limited by the latency of the round-trip to the server. In order to achieve higher throughput if the request processing time cannot be reduced, the HTTP client can start multiple simultaneous connections to the server. These multiple connections can overlap processing of multiple requests, which gives higher throughput.
To enable multiple connections, you must set the numClients configuration option on the HTTP transport. If you are writing your own chain, you would set it as follows in the YAML configuration file:
- HTTPClientTransport:
host: "hostname"
numClients: 3
If you are using the generic event definitions, then you can pass the number of clients as an option to getOrCreateWithConfigurations:
HttpTransport transport :=
HttpTransport.getOrCreateWithConfigurations("www.example.com", 80,
{ HttpTransport.CONFIG_NUM_CLIENTS: "3" });
This causes the HTTP transport to create three threads and three persistent connections to the target server. Any idle connection can execute the next request, unless specified otherwise (see below).
Controlling concurrency
Having requests processed concurrently means that responses to those requests may not come back in order. It also means that a later request can begin before an earlier request is complete. This is necessary to get the improved throughput, however, it may be that not all requests are eligible to be processed in any order with respect to each other. For example, two updates to the same entity in a REST API may need to be processed in the correct order to have the correct value afterwards. Alternatively, creating an entity followed by searching for all entities of that type should return the just-created entity.
To allow applications to get the behavior they expect, they can also specify a key on each request called the concurrency control key. A concurrency control key serializes all requests with the given key. If set, a request with a concurrency control key waits until any earlier requests with the same key have completed and causes any later requests with the same key to wait until it has completed. This means that only one request can be in-progress at a time for a given concurrency control key. Requests with different keys or no key can be processed concurrently to this request.
For example, in a REST API, the concurrency control key could be set to the item ID when doing a create/read/update/delete on a specific item, to prevent multiple operations on the same item from racing with each other.
Note:
Although any value is permitted here, we recommend using strings or integers to avoid equality issues with special values in other types.
In addition, there is a second option called concurrency control flush that can be set on each request. This is a Boolean flag that delays this request from starting until all earlier requests have completed (regardless of the concurrency control key). Note that later requests are permitted to start while the flush-enabled request is still executing.
For example, in a REST API, you might set flush on a request that lists or queries multiple items, since you would not want such an operation to start until all earlier create/update/delete operations affecting individual items had completed.
In general, when performing operations on multiple items, flush on the first get after a create/delete/update and vice-versa.
See also the description of the fields
metadata.concurrencyControlKey and
metadata.concurrencyControlFlush in
Mapping events between EPL and HTTP client requests.
These two metadata items can be used together as follows:
Metadata | concurrencyControlKey is empty, unset or the empty string ("") | concurrencyControlKey is set to any other value |
concurrencyControlFlush is false | Do not wait for any requests. This request can be executed concurrently with any other request. | Wait for all prior requests with the same concurrencyControlKey to complete before starting this request. This request can be executed concurrently with other requests which do not have the same concurrencyControlKey value. |
concurrencyControlFlush is true | Wait for all prior requests to complete before starting this request. This request can be executed concurrently with any subsequent request. | Wait for all prior requests to complete before starting this request. This request can be executed concurrently with subsequent requests which do not have the same concurrencyControlKey value. |
concurrencyControlFlush evaluates to true or false, but does not necessarily have to be a Boolean type:

false (or empty, unset, empty string (
""),
"false" string) evaluates to false.
Any other value evaluates to true.
For best performance, we recommend one of the following options:
The number of distinct concurrency control keys used in the system is much larger than the number of clients.
Or there is a much larger proportion of requests without
concurrencyControlKey set than with it.
To set the concurrencyControlKey via the YAML configuration file, you typically need to map it from a field in your event. For example:
- mapperCodec:
HTTPRequest:
towardsTransport:
copyFrom:
- metadata.concurrencyControlKey: payload.id
Alternatively, if you are using the generic event definitions:
Request req:= transport.createGETRequest("/geo/");
req.setConcurrencyControlKey("geo");
req.setConcurrencyControlFlush(true);
req.execute(handleResponse);
Example of controlling concurrency
Below is an example of when it may be appropriate to use concurrencyControlKey and concurrencyControlFlush in a simplified sequence for demonstration purpose.
This is using the following custom connectivity YAML file with an event MyHTTPRequestWithKeyAndFlush to map to the HTTP request:
startChains:
http:
- mapperCodec:
MyHTTPRequestWithKeyAndFlush:
towardsTransport:
mapFrom:
- metadata.requestId: payload.requestId
- metadata.http.path: payload.path
- metadata.http.method: payload.method
- metadata.concurrencyControlKey: payload.concurrencyControlKey
- metadata.concurrencyControlFlush: payload.concurrencyControlFlush
- payload: payload.data
The monitor file used in this example uses a custom event to map to the HTTP request API:
event MyHTTPRequestWithKeyAndFlush
{
// Standard HTTP request payload fields
integer requestId;
string path;
string data;
string method;
// Fields for concurrency control
any concurrencyControlKey;
boolean concurrencyControlFlush;
}
You can then proceed as described in the following steps.
Step 1: Create two devices using the device name as the concurrency control key:
send MyHTTPRequestWithKeyAndFlush(0, "/devices/myDevice1", "example data",
"POST", "myDevice1", false) to chain;
send MyHTTPRequestWithKeyAndFlush(1, "/devices/myDevice2", "example data",
"POST", "myDevice2", false) to chain;
Step 2: Get myDevice1 information, synchronized on the concurrency control key to ensure that the device has already been created before GET is processed:
send MyHTTPRequestWithKeyAndFlush(2, "/devices", "=myDevice1",
"GET", "myDevice1", false) to chain;
Step 3: Create two further devices:
send MyHTTPRequestWithKeyAndFlush(3, "/devices/myDevice3", "example data",
"POST", "myDevice3", false) to chain;
send MyHTTPRequestWithKeyAndFlush(4, "/devices/myDevice4", "example data",
"POST", "myDevice4", false) to chain;
Step 4: Get information for all existing devices, set concurrency control flush to true to ensure that all prior requests have been processed and recently created devices are returned.
send MyHTTPRequestWithKeyAndFlush(5, "/devices", "=*", "GET", "", true) to chain;
Step 5: Create multiple devices later. This does not depend on anything prior, so no concurrency control flush or concurrency control key is required.
send MyHTTPRequestWithKeyAndFlush(6, "/devices/myDevice[5,6,7,8]",
"example data", "POST", "", false) to chain;
Step 6: A concurrency control key was not specified in the prior POST, but you may want to act on the result of the next query. Find myDevice5 and then update it. Send with concurrency control flush set to true to ensure that the device is created, and set the concurrency control key to the expected name to ensure that the PUT occurs serially.
send MyHTTPRequestWithKeyAndFlush(7, "/devices", "=myDevice6", "GET",
"myDevice6", true) to chain;
send MyHTTPRequestWithKeyAndFlush(8, "/devices/myDevice6", "example data", "PUT",
"myDevice6", false) to chain;
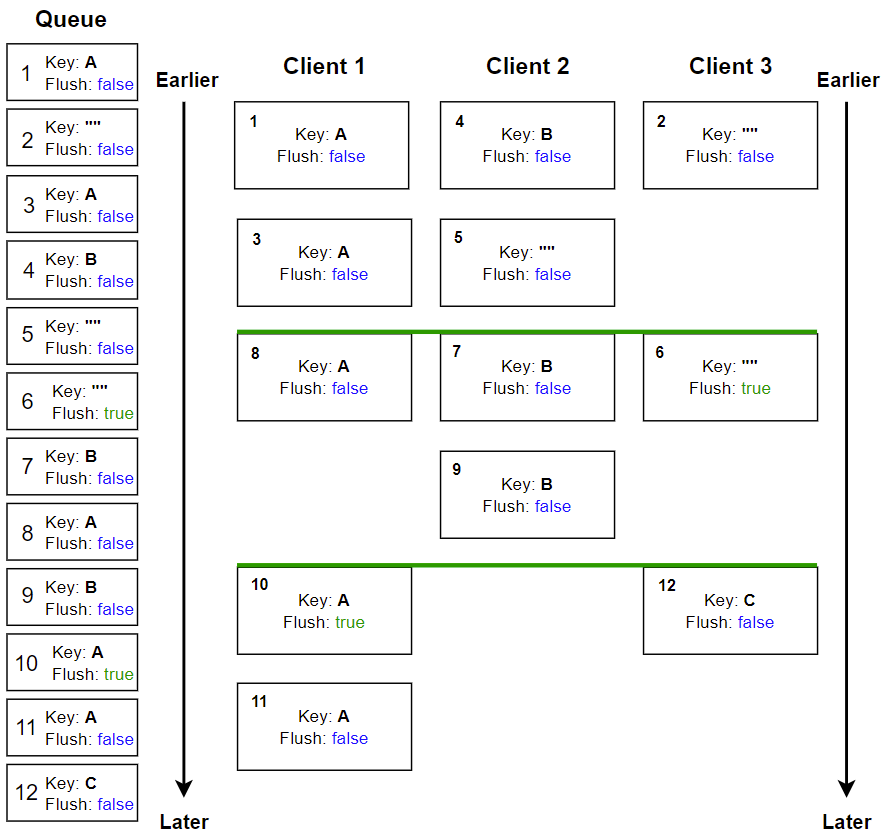
Example of incoming requests
The diagram below shows an example of incoming requests added to the queue as seen on the left, ordered from top to bottom, and one possible example of how the requests may be handled on the three available clients top to bottom.
The numbers represent the order in which the requests were sent.
The solid green line indicates a flush, ensuring all prior events complete before proceeding.
Notice how all requests with the same key are handled in order, requests with a different key are handled concurrently on another client, and requests with no key (empty string "") are handled concurrently on any available client.
The example shown in the above diagram runs as follows:
1. Requests 1 to 12 are sent.
2. Requests 1 and 3 have the same key, therefore they must be handled in order (for example, an updated measurement on a device where key A represents a device A). Requests 2 and 4 can be handled concurrently to request 1 in the meantime, since they do not affect the device A.
3. Request 6 has flush set to true, also indicated by the solid green line. This means that requests 1 to 5 must finish before any further requests can be processed (for example, requesting current measurement values for all devices). Without the flush, there is no guarantee that any of the prior requests have already completed. For example, if the application sent batch 1 to 5, you can query with request 6 whether these return the expected values; without flush, any number of the prior requests might be excluded.
4. Once the queue has flushed, requests 6, 7 and 8 can be processed concurrently.
5. Request 10 has flush set to true and the key set to A. This flushes the queue and ensures that the next request with the key set to A is processed after this one. You may want to update device A, but ensure to have known state before proceeding (for example, that any existing queries have completed).
Monitoring concurrency
The HTTP client publishes the following concurrency-related status items:
numClients serializedRequests concurrencyUtilizationPercent For more information on these metrics, see
Monitoring status for the HTTP client.