string
A text string.
Usage
Enclose string literals in double quotes. Values of the string type are sequences of non-null Unicode characters encoded in UTF-8 format. Note that UTF-8 is a variable-width encoding and a character can occupy from 1 to 4 bytes of storage. The characters in the 7-bit ASCII character set are a subset of UTF-8 and occupy a single byte each.
Although string types are discussed as though they are primitive types, they are actually reference types. However, EPL's string objects are immutable. For example, a statement such as s:=s+" suffix"; creates a new string object and changes the variable s to refer to that new string object. Any other references to the old value continue to point to the old value.
Operations that can return a different string value, such as concatenation, case folding, or trimming white space, always create new strings rather than modifying the existing value in place. The previous value's storage is recovered later by the EPL runtime garbage collector.
The length of a string is limited by the memory available at runtime, which can be multiple gigabytes. In practice, you are unlikely to exceed the limit in a single string.
Use the \ to enter special characters in string literals:
To enter this... | Insert this... |
" (double quote) | \" |
\ (backslash) | \\ |
newline character | \n |
tab character | \t |
Operators
The table below lists the EPL operators available for use with string values.
Operator | Description | Result Type |
< | Less-than string comparison | boolean |
<= | Less-than or equal string comparison | boolean |
= | Equal string comparison | boolean |
!= | Not equal string comparison | boolean |
>= | Greater-than or equal string comparison | boolean |
> | Greater-than string comparison | boolean |
+ | String concatenation | string |
When you compare two strings for equality, the result is true if the strings are the same length and each character in one string is identical to the corresponding character at the same position in the other string.
When you compare two strings for less than or greater than, the characters in the strings are compared pairwise according to the numerical values of their Unicode code points. The comparison is case-sensitive so capital letters are not equal to their lowercase equivalents. Characters earlier in the character set sort before characters later in the character set. To order two unequal strings, the earliest difference is considered. For example, "abcXdef" sorts earlier than "abcYdef", "abc" sorts earlier than "abcXYZ"; the empty string sorts earliest of all.
Methods
The following methods may be called on values of string type:
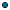 canParse(string)
canParse(string) —
Returns true if the string argument can be successfully parsed.clone(string) —
Returns a reference to the specified string. When called on a
string, the
clone() method does not make a copy of the string since strings are immutable.
find(substring) —
Returns an integer indicating the index position of the substring passed as parameter to the method. If the string parameter does not exist as a substring within the string, the method returns
-1. Note that in EPL string indices (the position of a character within the string) count upwards from
0.
findFrom(substring, fromIndex) —
Behaves like the find() method, but starts searching for the specified substring with the character indicated by fromIndex. For example, if the value of
fromIndex is
7, the search begins with the character that has an index of
7.
intern() —
Marks the string it is called on as interned. Subsequent incoming events that contain a string that is identical to an interned string use the same string object. The
intern() method takes no arguments and returns the interned version of the string it is called on. For example:
print "hello world";
print "hello world".intern();
Both statements print:
hello world
The benefit of using the intern() method is that it reduces the amount of memory used and the amount of work the garbage collector must do. A disadvantage is that you cannot free memory used for an interned string.
If there are a limited number of strings that will be used many times then calling intern() on these strings speeds the handling of events that use them. You might want to call intern() on the names of products or stock symbols, which are all used frequently. For example, invoking "APMA".intern() might make sense if you are expecting a large number of incoming events of the form Tick("APMA", ...). You would not want to call intern() on order IDs, because there are so many and each one is likely to be unique.
Calling intern() on a string is a global operation. That is, all contexts can then use the same string object. Any strings already in use by the correlator are not affected, even if they match the string intern() is called on.
If you use correlator persistence, details of which strings have been interned are not stored in the recovery datastore. If the correlator shuts down and restarts, you must call intern() again on the pertinent strings.
join(sequence<string> s) —
Concatenates the strings in s using the string it is called on as a separator. The single parameter must be a
sequence type that contains strings. You cannot specify a variable number of
string parameters. For example:
sequence<string> s :=
["Something", "Completely", "Different"];
print ", ".join(s);
This prints the following:
Something, Completely, Different
length() —
Returns an integer indicating the length of the string. ltrim() —
Returns a string where all whitespace characters at the beginning have been removed. White space characters are space, new line and tab characters.
parse(string) —
Returns the string value represented by the string argument without enclosing that value in quotation marks. You can call this method on the string type or on an instance of a string type. The more typical use is to call
parse() directly on the
string type.
The
parse() method takes a single string as its argument. The string must adhere to the format described in
Event file format.
Use the following format to specify the string you want to parse:
"your_string_with_escape_characters"
Use a backslash to escape each quotation mark or backslash in your string, including quotation marks that enclose your string. For example, to parse "Hello World", specify it as "\"Hello World\"". In other words, if you are writing literal strings in EPL, you must precede all backslashes and quotation marks with a backslash. For example:
string a := "\".\\\\.\"";
string b := string.parse(a);
print a;
print b;
This prints the following:
".\\."
.\.
The string.parse() method is useful when you have a string that contains backslash escape characters and you want to obtain a string without them.
More examples:
string a := string.parse("\"Hello World\"");
string b := string.parse("\"\\\"\"");
print a;
print b;
This prints the following:
Hello World
"
You can specify the parse() method after an expression or type name. If the correlator is unable to parse the string, it is a runtime error and the monitor instance that the EPL is running in terminates. For example, the following is an error and causes the correlator to terminate:
a := string.parse("Hello World");
The parse() method cannot parse the result of a toString() method. This is because the toString() method does not enclose its result in quotation marks, nor does it escape any special characters. For example, the following is false:
x = string.parse(x.toString())
If a string contains no special characters (for example, " or \) then the following equality does hold true:
x = string.parse("\""+x.toString()+"\"")
replaceAll(string1, string2) —
Makes a copy of the string, replaces instances of string1 with instances of string2 and returns the revised string. For example:
string x := "XYZ";
print x.replaceAll("Y","y");
print x;
This prints the following:
XyZ
XYZ
Notice that x itself is unchanged. If string1 is an empty string then the monitor instance dies. If instances of string1 overlap then the method replaces only the first instance in the overlapping instances.
rtrim() —
Returns a string where all whitespace characters at the end have been removed. Whitespace characters are space, new line and tab characters.
split(string input) —
Returns a sequence of the strings that result from splitting the input string on every occurrence of the delimiter string that the method is called on. The size of the returned sequence is always one more than the total number of occurrences of the delimiter string. Consecutive delimiters in the input string result in empty strings in the returned sequence. The
split() method is useful for separating a string that contains newline characters into individual lines or for dividing comma-separated values in a single string into multiple strings. For example:
Method Call | Returned Sequence |
",".split("x,y,z") | ["x","y","z"] |
",".split("") | [""] |
",".split(",x,,y") | ["","x","","y"] |
"\r\n".split("line1\r\nline2\r\n\r\n") | ["line1","line2", "", ""] |
This method performs the inverse of join(sequence<string>). See also the tokenize(string) method which is related but has slightly different behavior.
substring(integer, integer) —
Returns the substring indicated by the integer parameters. The parameters indicate the position of the first and last characters of the substring, the first being inclusive, while the second is exclusive. If a parameter is a positive value it is taken to be the position of a character going from left to right counting upwards from
0. If a parameter is a negative value it is taken to be the position of a character going from right to left counting downwards from
-1. Therefore if
string s;
s := "goodbye";
then
s.substring(0, 0) is ""
s.substring(0, 2) is "go"
s.substring(2, 4) is "od"
s.substring(0, 7) is "goodbye"
s.substring(0, -1) is "goodby"
s.substring(-4, -1) is "dby"
s.substring(-7, -1) is "goodby"
s.substring(-7, 7) is "goodbye"
tokenize(string input) —
Returns a sequence of all the non-empty strings (tokens) that result from splitting the input string on occurrences of any character from the string that the method is called on. The returned sequence never contains any empty strings, and will have no elements if the input string is empty or contains only delimiters. The
tokenize() method is useful for extracting words from whitespace. For example:
string s := " This is\na test! See? ")
print " ".tokenize(s).toString();
print " .,:;!?\n\t".tokenize(s).toString();
This prints the following:
["This","is\na","test!","See?"]
["This","is","a","test","See"]
See also the split(string) method which is related but has slightly different behavior.
toBoolean() —
Returns true if the string is "true" and false in all other cases. This method is case sensitive.
toDecimal() —
Returns a decimal representation of the string, if the string starts with one or more numeric characters. The numeric characters can optionally have among them a decimal point or mantissa symbol. Returns
0.0 if there are no such characters.
toFloat() —
Returns a float representation of the string, if the string starts with one or more numeric characters. The numeric characters can optionally have among them a decimal point or mantissa symbol. Returns
0.0 if there are no such characters.
toInteger() —
Returns an integer representation of the string, if the string starts with one or more numeric characters. Returns
0 if there are no such characters.
toLower() —
Returns an all-lowercase string representation of the string. toString() —
Returns the contents of the string value, exactly the same as using the string directly. toUpper() —
Returns an all-uppercase string representation of the string. Additional methods which use regular expressions
You can use the following methods to search and replace strings using regular expressions. You call them on values of string type. regex stands for the regular expression pattern against which the string is to be matched.
matches(string regex) —
Returns true if the string matches the specified regular expression. For example:
Method Call | Returned Boolean |
"bit".matches("[a-f]it") | true |
"sit".matches("[^a-f]it") | true |
"Muenchen".matches("M(ü|ue)nchen") | true |
"αθηνα".matches("^[α-ω]+$") | true |
"$12.99".matches("\\$\\d+\\.\\d{2}") | true |
"3,45€".matches("\\d+[\\.\\,]\\d{2}\\s?€") | true |
"xyzqxyzqqyz".matches("(x(yz))q\\1qq\\2") | true |
search(string regex) —
Returns a sequence<string> containing all non-overlapping matches that have been found for the specified regular expression. For example:
Method Call | Returned Sequence |
"The dog plays in the big bad wolf's top yard".search("\\b\\w{3}\\b") | ["The", "dog", "the", "big", "bad", "top"] |
"price=[9.01, 8.73, 8.37, 8.88]".search("\\d+\\.\\d{2}") | [9.01, 8.73, 8.37, 8.88] |
"{data: [-1.60e-19C, 9.1094E-31kg, -1.0011597μB]}".search("[-+]?[1-9]\\.?[0-9]*([eE][-+]?[0-9]+)?kg") | [9.1094E-31kg] |
replace(string regex, string replacement) —
Returns a new string in which the first match that has been found for the specified regular expression has been replaced with the specified replacement string. To replace all matches globally, you have to use (!g) before the regular expression. For example, to globally replace all
A characters and to ignore case at the same time, you specify the following as the
regex string:
(!g)(?i)A
Examples:
Method Call | Returned String |
"string your string okay string".replace("string", "STR") ) | "STR your string okay string" |
"StriNG your string okay string".replace("string", "STR") ) | "StriNG your STR okay string" |
"StriNG your string okay string".replace("(?i)string", "STR") ) | "STR your string okay string" |
"StriNG your string okay string".replace("(!g)string", "STR") ) | "StriNG your STR okay STR" |
"StriNG your string okay string".replace("(!g)(?i)string", "STR") ) | "STR your STR okay STR" |
"convert text message".replace("(!g)a|e|i|o|u", "") | "cnvrt txt mssg" |
"Lässt grössenordnungsmässig grösstmöglich messgerät".replace("(!g)ss", "ß").replace() | "Läßt größenordnungsmäßig größtmöglich meßgerät" |
"capture yz and format".replace("(yz)", "### $1 ###") | capture ### yz ### and format |
All of the above methods throw a runtime exception if the regular expression syntax is invalid.
EPL uses IBM's International Components for Unicode (ICU) to implement regular expressions (see
http://site.icu-project.org/). Thus, you can use all of the regular expressions that are described in the ICU User Guide with the above methods; see
http://userguide.icu-project.org/strings/regexp for detailed information. Other than the ICU regular expression syntax, Apama provides the additional option
(!g) for the
replace method, which allows you to replace all matches rather than just the first one. This option must be the first part of the regular expression.
