Best practices for defining queries
Use values for the length of the window that will not store too much data in the window.
Given the expected incoming event rate, set the within and/ or retain window lengths so that typically less than a hundred events per partition will be within the window. With more than that the cost of executing queries can become excessive and the system will not perform efficiently. There is no limit on the number of events within any partition - if a very small proportion of exceptional partitions has many more, then that is not a problem. The important factor is that if the average number is large, this can affect the performance of executing queries.
Use parameters instead of creating many similar queries.
Rather than write many separate queries which are very similar in structure and differ only in values, it may be easier to write a template query and create multiple parameterizations of it. See also
Parameterized queries as templates.
If a query requires different fields for its keys depending on the query parameters, it should use an action as a query key. See also
Defining actions as query keys.
Use within in input durations if the partition values change over time
In some queries, the key used by the query may correspond to a transient object - that is, any given value for the partition is not permanent. For example, if tracking parcels being delivered, then each consignment ID will be short lived - once a parcel is delivered, there would in most cases be no more events for that consignment ID (and future deliveries may never re-use the same consignment ID). In these cases, over long periods, the number of different key values processed will only increase, as new IDs are generated. Such queries should include a 'within' specification in the inputs for all event types. Otherwise, if inputs only have a retain specification, then the events will be held forever, and more and more storage will be required by the queries system. This is not typically necessary if the key corresponds to more permanent objects - such as ATMs or distribution depots.
Use input within that is larger than the value of all waits, withins in the pattern
If your inputs specify a within and there are wait or withins in the pattern, then the input within should be larger than the longest wait and within in the pattern. If not, the pattern will not have the intended effect, as events will be expired from the input window while a wait or within in the pattern is still active.
Use same set of inputs to allow sharing of data
If you have many queries of different types and they are using a lot of memory or are running slowly, then check if they are using the same inputs definitions (see also
Queries can share windows). Memory usage can be reduced and performance increased by making multiple queries use the same set of input definitions, even if some queries have some event types in their inputs that they are not using.
Understand the difference between filters and where clauses
Filters in the input section filter events before they are stored in the distributed cache. By contrast, the where clause filters events (or combinations of events) after they have been stored in the distributed cache. The where clause is more powerful, but also more expensive, especially if most events do not match the where clause.
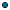
A filter applies before the event window. Thus:
Events not matching the filter are ignored and do not need to be stored anywhere. This makes filtering a very cheap way of reducing the number of events that need to be processed. The retain count only applies to the events that match the filter. For example, this query input:
query Q1 {
inputs {
Event( value = 5) key k retain 2;
}
find Event as e1 -> Event as e2 {
}
}
Will match events where there have been two events with value = 5; it will match if another event for the same k has occurred between them with value not equal to 5. Compare with:
query Q2 {
inputs {
Event() key k retain 2;
}
find Event as e1 -> Event as e2 where e1.value = 5 and e2.value = 5 {
}
}
This only matches if the last two events for a given value of k both have the value 5 - as we only retain 2 events and after retaining 2 events, check that they have value = 5.
A filter applies to all events - note that in query Q2 above we had to repeat the value = 5 check.
A where clause does not affect the definition of the inputs; query Q2 could share window contents with other queries that are concerned with different values of 'value', or don't filter at all.
A filter is restricted to range or equality matches per field of the incoming events. Where clauses can be more complex (e.g.
where e1.field1 + e2.field2 = 10 is valid, as is
e1.isTypeA or e1.isTypeB - but neither could be expressed in a filter)
Avoid changing parameter values used in filters
If using parameters in filters, avoid changing the values of those parameters. As this changes which events should be being stored in the window, this is similar in effect to stopping a query instance and creating a new query instance - it involves creating new tables in the distributed cache and events that are delivered to correlators while a new table is opened will be dropped. It may be more desirable to use a where clause to restrict which events match a pattern.
Use custom aggregates to get data from multiple match sets
As well as the built-in aggregates, it is possible to define new aggregates in EPL to collate information about all events that matched a pattern. For example, it may be desirable to have a list of all events that matched a pattern. This can be achieved by writing a new custom aggregate. For example:
// file MyAggregates.mon:
aggregate CollateEvents(Event e) returns sequence<Event> {
sequence<Event> allEvts;
action add(Event e) {
allEvts.append(e);
}
action value() returns sequence<Event> {
return allEvts;
}
}
// file PrintAllEvents.qry:
query PrintAllEvents {
inputs {
Event() within 2 hours;
}
find every Event as e1 select CollateEvents(e1) as c1 {
Event e;
for e in c1 {
print e.toString();
}
}
}
