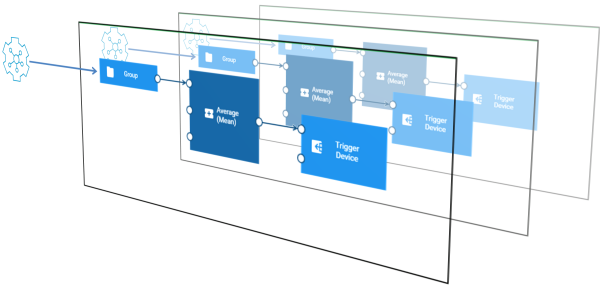
Model execution for different devices
Models are executed independently of each other. That is, models for specific devices can execute in parallel, making use of hardware parallelism where possible, if models are processing data (such as Measurement, Event, or Operation objects) for a different set of devices. When defining a model, you can configure it to use data from a set of specific devices, or from a group of devices, with each device being handled independently.
Each model must either:

receive input from a set of specific devices and send output to a set of specific devices, or
receive input from each device within device groups and send output to the trigger device.
A device group is a means of organizing devices. A device group can contain any number of devices or other device groups. When a model uses a device group, the model will act on all devices referred to by the device group, either directly or indirectly through members of the device group that are themselves device groups and have device members (or even
grand-children device group members). A device can be a member of zero, one or many device groups. See also the information on the Device Management application and grouping devices in the
User guide at
https://www.cumulocity.com/guides/.
Note:
A model that acts on a device group only determines the device group membership when the model is activated. If the membership of a device group changes while a model is running, the model will not behave any differently for any new or removed members of the group. If a device group membership is changed, then models that refer to that device group should be de-activated and re-activated.
It is not possible to mix the two types of input blocks above (but see
Broadcast devices). However, data from a model processing specific devices can be sent to and received from other models, including models for device groups, and vice versa (see
Connections between models).
When a model consumes data from groups, the model behaves as if multiple instances of the model are running, as illustrated below, each one processing data from each device independently. Each instance processes data for a different device, but all share the same blocks and block parameters. The values of the wires will be independent for different instances. Any blocks that are stateful, such as the Average (Mean) block, will operate independently of the data from other devices. As with models using specific devices, if any block causes a runtime error or exception, then the entire model will go into a failed state - it will stop processing data for all devices.
Typically, when using device groups for inputs, all input blocks would use the same group. It is possible to use different device groups. If there are devices in one group but not in another, those blocks will never generate a signal for devices that are not in that group. For some blocks, such as the Expression block, this is not useful - an Expression block will only generate an output if all of the required inputs have received a value, but it may be useful for pulse inputs of a Gate block.
When a model has inputs that are consuming data from specific devices, then the output blocks generating outputs can specify the same or different specific devices.
When a model has inputs that are consuming data from a device group, all synchronous output blocks must specify the Trigger Device, a special device in the Output category of the palette. The trigger device generates data (Measurement, Event or Operation) for whichever device that instance applies to - or whichever device sent the data to trigger that instance. Asynchronous output blocks in such models can specify the trigger device or any other specific device.
When a template parameter is used for an output block, then if the parameter's value is a device group, then this is treated the same as if it were set to the trigger device. The output will go to whichever device triggered the model's evaluation, with each device within a group being treated independently. Typically, the same template parameter will be used for both input and output, so these will refer to the same group, and each device is processed independently.
You can use the model editor to change input and output blocks from one device or device group to another. When changing between a device group and a device, output blocks will switch between the trigger device and the device specified, so that the model is kept in a usable state. See also
Replacing devices, device groups and assets.
The test and simulation modes are only permitted for models using specific devices. If you wish to test or simulate a model using a device group, then use the model editor to modify it to apply to a single device within the device group, and then activate the model in test or simulation mode. See
Deploying a model for more information on these modes.
Configuring the concurrency level
By default, the
Analytics Builder runtime uses 1 CPU core to execute models. If you want to change the number of CPU cores, send a
POST request to
Cumulocity IoT that changes the value for the
numWorkerThreads key. See
Configuration for detailed information.
Typically, this configuration value would be set to the number of CPU cores available for the system, but it may be useful to configure this either higher or lower according to what resources are available. It does not need to scale to the number of devices (that is, it is quite reasonable to have 4 worker threads with hundreds of devices, assuming a moderate event rate per device).
With the concurrency level set to 1, it is still possible to create models which use device groups as inputs, but these continue to operate independently for each device within the device group, and it is still not possible to mix device group and single device input or output.
Note:
Using multiple specific devices in a model with the concurrency level set to more than 1 can lead to connections between models which are deployed across multiple workers. Chains of models using multiple specific devices with high throughput usually scale less well than chains of models all using a single specific device.
Support for multiple devices in a single model with the concurrency level set to more than 1 is disabled if any input or output blocks written using the version 1 API of the
Analytics Builder Block SDK are added as extensions. See the documentation at
https://github.com/SoftwareAG/apama-analytics-builder-block-sdk for information on how to migrate the blocks to the version 2 API.