Adabas Native SQL is an easy-to-use data manipulation language for accessing and updating information held in an Adabas database. The following example shows a typical Adabas Native SQL statement that selects a record from the database and retrieves the required data:
EXEC ADABAS
SELECT NAME, AGE, SALARY
FROM PERSONNEL
WHERE NUMBER-OF-DEPENDENTS > 4
END-EXEC
This statement selects the data fields NAME, AGE and SALARY from the first record in the PERSONNEL file that satisfies the criterion "NUMBER-OF-DEPENDENTS > 4".
Statements such as this one are embedded into Ada, COBOL, FORTRAN77 or PL/I programs. This means you have the advantage of being able to use a familiar programming language to code the logic of your problem, whilst the Adabas Native SQL statements give you ready access to all the facilities of Adabas, a powerful modern database management system.
Adabas Native SQL incorporates the full power of the Natural userview concept. This means you refer to fields defined in a userview as logical entities without having to concern yourself with the physical details of file structure and record structure. For example, if you specify a group field, Adabas Native SQL automatically creates Ada, COBOL, FORTRAN or PL/I data declarations with the correct:
set of fields (possibly a subset of the fields in the database record; conversely, a field may occur repeatedly in the userview if desired)
field names
field sequence
record structure, including all groups, sub-groups, sub-sub-groups, etc.
field formats (alphanumeric, numeric, packed numeric, etc.)
field lengths.
Adabas Native SQL works in conjunction with Predict, Software AG's data dictionary system. The information about file and record layouts contained in Predict is used to generate the data structures that the generated Ada, COBOL, FORTRAN or PL/I program needs to access the database. As an Adabas Native SQL programmer, you do not need to code detailed data declarations in your program, so you are free to concentrate on the logic of the application.
Conversely, as Adabas Native SQL is processing the program, it records active cross-reference information, or Xref data, in Predict. This Xref data includes the names of the files and fields that the program accesses. Thus it is easy to find out which programs use which data fields, etc., so that the programs that need to be recompiled when data structures are altered can readily be determined.
The interaction between Adabas Native SQL and Predict is illustrated in the following figure.
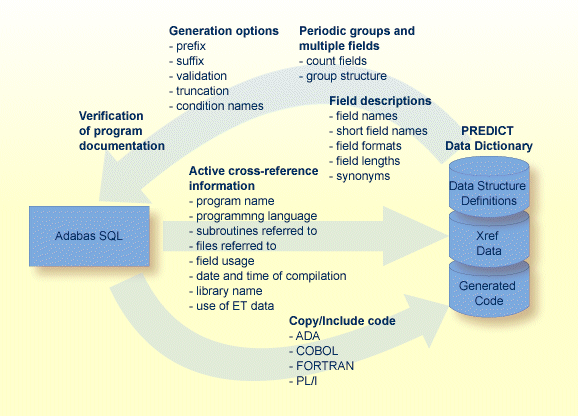
Consistent use of Adabas Native SQL throughout a data processing installation eliminates the risk of writing incorrect data declarations in programs that access the database. It also creates comprehensive records in the data dictionary that show which programs read from the database and which programs update it. This makes programs easier to maintain and provides the DBA with an effective management tool.
After it has been preprocessed by Adabas Native SQL, the program - containing data definitions and executable code generated by Adabas Native SQL as well as the original Ada, COBOL, FORTRAN or PL/I code written by the programmer - is compiled and link-edited in the normal manner.