This document describes the utility "ADADCU".
The following topics are covered:
The decompression utility ADADCU decompresses records produced by the ADACMP, ADAMUP and ADAULD utilities.
The output of the decompression utility ADADCU can be used as input for a program using standard operating system file access methods.
It can also be used as input for the compression utility ADACMP once any required changes have been made to the data structure or once the data definitions of the file have been changed. A warning message is issued if the decompressed output file (DCUOUT file) created by the utility is empty.
ADADCU also decompresses files produced with the SINGLE option of the utilities ADAULD and ADACMP, but no parameter is required since this can be determined by the utility.
With ADADCU, the following functions are available:
Complete records can be decompressed to the formats and lengths described in the FDT. A one-byte count field precedes each multiple-value field or periodic group in the output record.
LOB field values can also be stored in separate files; the generated file names are put into the decompressed records.
Several fields can be decompressed.
If several fields are decompressed, the fields can be re-arranged within a record, i.e. the record structure may be changed as follows:
Field lengths can be changed;
Field formats can be changed;
Space can be allocated for subsequent addition of new fields using the literal element or blank element.
If the utility writes records to the error file, it will exit with a non-zero status.
This utility is a single-function utility.
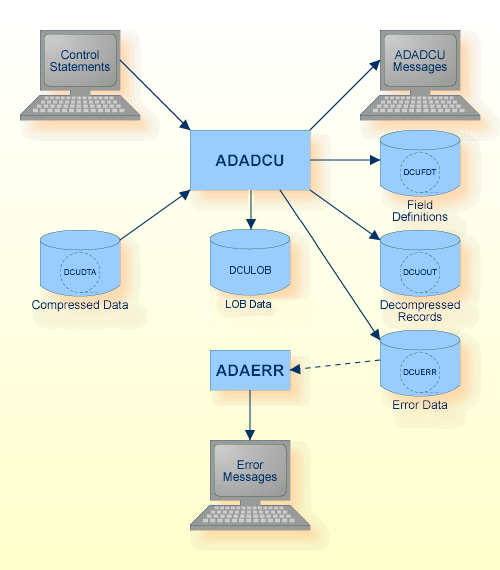
DCULOB is a directory where LOB values are stored in separate files. The sequential files DCUDTA and DCUERR can have multiple extents. .
| Data Set | Environment Variable/ Logical Name |
Storage Medium |
Additional Information |
|---|---|---|---|
| Compressed data records |
DCUDTA | Disk, Tape (* see note) | Output of ADACMP or ADAULD |
| Rejected data | DCUERR | Disk, Tape (* see note) | Output of ADADCU |
| Output data FDT | DCUFDT | Disk, Tape (* see note) | Output of ADADCU Utilities Manual |
| Decompressed records | DCUOUT | Disk, Tape (* see note) | Utilities Manual |
| LOB data | DCULOB | Disk | Utilities Manual |
| Control statements | stdin/ SYS$INPUT |
Utilities Manual | |
| ADADCU messages | stdout/ SYS$OUTPUT |
Messages and Codes |
Note:
(*) A named pipe can be used for this sequential
file.
The utility writes no checkpoints.
The following control parameters are available:
D [NO]DCUFDT D [NO]DST FDT FIELDS {field_specification | FDT},...[END_OF_FIELDS | .] D [NO]LOWER_CASE_FIELD_NAMES D MAX_DECOMPRESSED_SIZE = number [K|M] D MUPE_C_L = {1|2|4} MUPE_OCCURRENCES D [NO]NULL_VALUE D NUMREC = number D RECORD_STRUCTURE = keyword SKIPREC = number D TARGET_ARCHITECTURE = (keyword[,keyword[,keyword]]) D [NO]TRUNCATION TZ {=|:} [timezone] D [NO]USERISN WCHARSET = char_set
[NO]DCUFDT
If this option is set to DCUFDT, the FDT information of the decompressed records is written to the sequential file DCUFDT. The default is NODCUFDT.
If you have used the FIELDS parameter (see below), the fields are written to the sequential file DCUFDT in the order specified in FIELDS. Thus, the fields in DCUFDT might be in a different order to those in the original FDT.
[NO]DST
The parameter DST is required if a daylight saving time indicator is to be provided for date/time fields with the option TZ. The daylight saving time indicator will be appended behind the date/time value as a 2-byte integer value (format F) containing the number of seconds to be added to the standard time to get the actual time (usually 0 or 3600).
This parameter is required if there are records containing date/time values with the option TZ in the hour before the time is switched back to standard time, otherwise these values are written to the error file.
The default is NODST.
Notes:
FDT
This parameter displays the FDT of the file containing the compressed records.
FIELDS {field_specification | FDT},...[END_OF_FIELDS | . ]
This parameter is used to specify a subset of fields given in the FDT and their format and length. This means that the decompressed records created do not have to contain all of the fields given in the FDT, or that fields can be decompressed with a different format or length. The syntax and semantics are the same as for the format buffer, with the exception that you can also specify an R-element (for LOB references) if the decompressed record contains the name of a file containing the LOB value instead of the LOB value itself.
While entering the specification list, the FDT function can be used to display the FDT of the file to be decompressed. The specification list can be terminated or interrupted by entering END_OF_FIELDS or `.'. The `.' option is an implicit END_OF_FIELDS and is compatible with the format buffer syntax. FIELDS or END_OF_FIELDS must always be entered on a line by itself, whereas the `.' may be entered on a line by itself or at the end of the format buffer elements. Processing may be continued after setting any option or parameter by entering FIELDS.
If the field definitions are terminated with the END_OF_FIELDS parameter, this parameter must be specified in upper case when the LOWER_CASE_FIELD_NAMES parameter is used. In addition, the FDT parameter must also be specified in upper case when the LOWER_CASE_FIELD_NAMES parameter is used.
adadcu: fields adadcu: ; This is a comment line adadcu: AA,AB,6,A,AC,P ; - inline comment - adadcu: AD,AF,CBC,CB1-N . ; implicit END_OF_FIELDS
Field AA is output with default length and format, field AB with 6 byte alphanumeric and field AC with default length packed. Fields AD and AF are output in default length and format, followed by the one-byte binary multiple field count of field CB and all its occurrences.
[NO]LOWER_CASE_FIELD_NAMES
If LOWER_CASE_FIELD_NAMES is specified, Adabas field names are not converted to upper case. If NOLOWER_CASE_FIELD_NAMES is specified, Adabas field names are converted to upper case. The default is NOLOWER_CASE_FIELD_NAMES.
This parameter must be specified before the FIELDS parameter.
MAX_DECOMPRESSED_SIZE = number [K|M]
This parameter specifies the maximum size of a decompressed record in bytes, kilobytes or megabytes, depending on the specification of "K" or "M" after the number. This parameter is intended to prevent very large decompressed record files from being created unintentionally (if you didn’t consider that a file contained LOB data).
The default is 65536. This is also the minimum value.
Note:
The exact definition of this parameter is the size of the I/O
buffer required for the largest decompressed record. Only multiples of 256
bytes are used for the I/O buffers, which means that you must specify a value
greater than or equal to the largest decompressed record (including the
preceding length field) rounded up to the next multiple of 256.
MUPE_C_L = {1|2|4}
If the data contain multiple-value fields or periodic groups, they are preceded by a binary count field with the length of MUPE_C_L bytes in the decompressed data.
The default is 1.
MUPE_OCCURRENCES
This parameter is used to print a list of all multiple fields and periodic groups together with their maximum occurrence. Such information is important because the decompressed data can become very large; if the range specified is too large, it is even possible to exceed the limit for the size of a decompressed record.
The FDT of the file containing the compressed records is as follows:
1,AA,4,A,NU 1,PE,PE 2,PA,2,A,NU 2,PB,2,A,NU,MU 1,MM,2,U,NU,MU 1,X1,4,B
MUPE_OCCURRENCES might produce something of the form:
Name Max occurrence --------------------- PE 4 PB 8 MM 12 %ADADCU-I-DCUREC, Number of decompressed records: 5023 %ADADCU-I-DCUIR, Number of incorrect records: 0
The file can then be decompressed as follows:
adadcu fields "AA,PA1-4,PB1-4(1-8),MM1-12,P,X1"
Note:
A record is considered to be incorrect if it has too many
occurrences of a periodic group containing an MU field, and thus causes an
internal overflow. It is not possible to decompress this record including the
periodic group.
[NO]NULL_VALUE
This parameter can be used to decompress records according to the standard FDT if the record contains NC option fields and their status values (S-elements). It is required if one or more fields have the null value, otherwise these records are put in the error file.
If the FDT entry for field AA is: 1, AA, 2, A, NC, the effect of NULL_VALUE is as follows:
NULL_VALUE: 1st output record (in hex) 00004141 (AA has a value), 2nd output record (in hex) FFFF2020 (AA has the null value).
NONULL_VALUE: 1st output record (in hex) 4141 (AA has a value), 2nd output record (in hex) AA is null, therefore the record will be put into the error file.
The default is NONULL_VALUE.
NUMREC = number
This parameter specifies the number of records to be read from the input file and decompressed. If NUMREC is not specified and SKIPREC is also not specified, all records are processed.
adadcu: numrec = 100
100 records are read and decompressed.
RECORD_STRUCTURE = keyword
This parameter specifies the type of record separation used in the output file with the logical name DCUOUT. The following keywords can be used:
| Keyword | Meaning |
|---|---|
| ELENGTH_PREFIX | The records in the DCUOUT file are separated by a two-byte exclusive length field. There is no separator character and the use of this format is not subject to any restrictions. |
| E4LENGTH_PREFIX | The records in the decompressed data file are separated by a 4-byte exclusive length field. |
| ILENGTH_PREFIX | The records in the DCUOUT file are separated by a two-byte inclusive length field. There is no separator character and the use of this format is not subject to any restrictions. |
| I4LENGTH_PREFIX | The records in the decompressed data file are separated by a 4-byte inclusive length field. |
| NEWLINE_SEPARATOR | The records in the DCUOUT file are separated by a
new-line character. If the DCUOUT file is to be used as input for ADACMP, this
keyword can only be specified if the field values of the output do not contain
the new-line character (i.e. if there are only unpacked, alphanumeric and
Unicode fields, and if the alphanumeric and Unicode fields only contain
printable characters). This keyword and the USERISN parameter are mutually exclusive. |
| RDW | The records in the DCUOUT file are formatted such that they can be transferred to an IBM host using the FTP site rdw option. |
| RDW_HEADER | Like RDW, for decompressed records that can be compressed on a mainframe with HEADER=YES. |
| VARIABLE_BLOCKED | The records are stored as blocks. Each record begins with an inclusive four-byte length field. |
The default is ELENGTH_PREFIX.
SKIPREC = number
This parameter specifies the number of records to be skipped before decompression is started.
TARGET_ARCHITECTURE = (keyword[,keyword[,keyword]])
This parameter specifies the format (character set, floating-point format and byte order) of the output data records. The following keywords can be used:
| Keyword Group | Valid Keywords |
|---|---|
| Character set |
ASCII EBCDIC |
| Floating-point format |
IBM_370_FLOATING IEEE_FLOATING VAX_FLOATING |
| Byte order |
HIGH_ORDER_BYTE_FIRST LOW_ORDER_BYTE_FIRST |
If no keyword of a keyword group is specified, the default for this keyword group is the keyword that corresponds to the architecture of the machine on which ADADCU is running.
Note:
The FDT is always output in ASCII format.
If the output records are to be decompressed into IBM format, the user must specify the following:
TARGET_ARCHITECTURE = (EBCDIC, IBM_370_FLOATING, HIGH_ORDER_BYTE_FIRST)
[NO]TRUNCATION
This option enables or disables the truncation of alphanumeric field values.
NOTRUNCATION is the default. In this case, all the records with truncated alphanumeric field values are written to the error file.
Numeric values may not be truncated, and the value must fit into the standard or specified length. If truncated numeric values occur, the records concerned are written to the error file.
TZ {=|:} [timezone]
The specified time zone must be a valid time zone name that is contained in the time zone database known as the Olson database (https://www.iana.org/time-zones). If a time zone has been specified, this time zone is used for time zone conversions of date/time fields with the option TZ.
The default is UTC, which is used internally to store date/time fields with option TZ; no conversion is required.
If you specify an empty value, no checks are made to ensure that date/time fields are correct.
Note:
The time zone names are file names. Depending on the platform,
these file names may or may not be case sensitive. Also, the time zone names,
depending on the platform, may or may not be case sensitive.
tz:Europe/Berlin
This is correct on all platforms.
TZ=Europe/Berlin
With this specification, TZ is converted to upper case EUROPE/BERLIN. This is correct on Windows, because file names are not case sensitive on Windows, but it is not correct on Unix, because Unix file names are case sensitive.
[NO]USERISN
This parameter indicates whether the ISN is to be output together with each decompressed record or not. The user can specify whether the ISN currently assigned to the record is to be output with the decompressed data or whether it is to be omitted. If the user intends to reload the file with the same ISNs, the USERISN option must be set.
This parameter cannot be specified if RECORD_STRUCTURE=NEWLINE_SEPARATOR is specified.
If this parameter is omitted, the ISN is not output with each record.
NOUSERISN is the default.
adadcu: userisn
The ISN is output with each record.
WCHARSET = char_set
This parameter specifies the default encoding used in the decompressed file based on the encoding names listed at http://www.iana.org/assignments/character-sets - most of the character sets listed there are supported by ICU, which is used by Adabas for internationalization support.
The input for ADADCU must be a file containing compressed records such as those output by the unload utility ADAULD or by the compression utility ADACMP.
ADADCU decompresses each input record in accordance with the FIELDS specifications and writes the resulting record to the file with the logical name DCUOUT. The records are written in variable-length format. By default, the records are separated by a two-byte exclusive length field (see the parameter RECORD_STRUCTURE in this section for more detailed information).
If USERISN is specified, the data record is preceded by its ISN in the form of a four-byte binary number.
The sequential file DCUFDT (field definition information of the decompressed records) can be used as input for the file definition utility ADAFDU or for the compression utility ADACMP.
Any records rejected by ADADCU are written to the ADADCU error file. The contents of this error file should be displayed using the ADAERR utility. Do not print the error file using the standard operating system print utilities since the records contain unprintable characters.
ADADCU does not have a restart capability. An interrupted ADADCU run must be re-executed from the beginning.
ADADCU does not update the database, therefore, no considerations regarding the status of the database need to be made before re-executing an interrupted ADADCU execution.