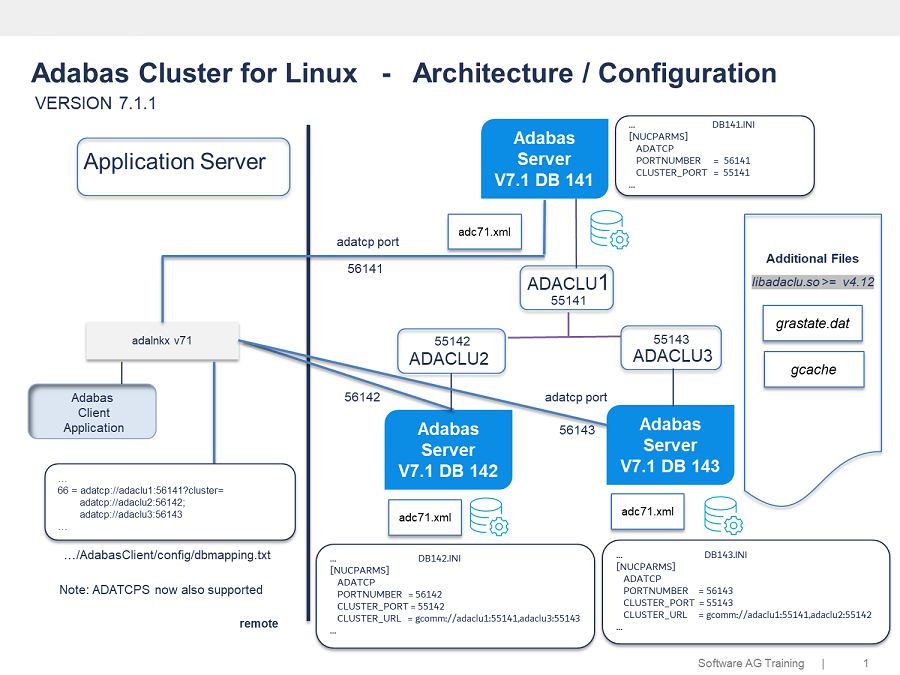
Adabas Cluster Architecture
Adabas Cluster is a cluster solution on Linux focussing on a shared-nothing architecture eliminating of all possible single points of failure.
The Adabas Cluster is based on a cluster framework that supports synchronous replication (changes on one node are guaranteed to be applied on the other nodes). The cluster allows for point-to-point connections between a client application and the Adabas Server using ADATCP(S).
Note:
Data-in-flight between client and primary node can be secured using ADATCP(S). The prerequisite for ADATCP(S) is, along with a licence for Entire Net-Work (WCP) for ADATCP, a valid license for Adabas Encryption for Linux (AEL).
Users who are familiar with Adabas on mainframe will notice that the mainframe solution contrasts in the reliance on high-speed caching, list processing and locking functions provided by the sysplex coupling facility, available on z/OS.
FAQ
 Q
Q: Can I have a cluster with three different nodes, one of which is a primary node and two of which are secondary nodes, all with the same
DBID (eg:
DBID 100) ?
A: Yes, it is possible to use the same database number for primary and all secondary nodes. The only restriction is that on one single host a DBID could not be used twice.
Q: Is there a way to make a secondary node a stand-alone database again? In other words, “remove any cluster footprint" of the database?
A: Yes. First, shutdown the database and execute adadbm db=xxx remove_cluster_file, then start the database without cluster related parameters.
Q: What is stored in a
GCACHE.xxx file whose size can be specified with the additional cluster option
gcache.size? Is size relevant for performance?
A: No, it's not relevant for the performance, gcache.size is intended as the main write-set store to support Incremental State Transfer (IST) by the cluster framework.
On one hand, the more space available, the more write-sets you can store. The more write-sets you can store, the wider the seqno gaps you can close through Incremental State Transfers.
On the other hand, if the write-set cache is much larger than the size of your database state, Incremental State Transfers become less efficient than sending a state snapshot.
Q: What about the new files
grastate.dat and
gvwstate.dat located in the database data directory? What are their role in the cluster?
A: The data in grastate.dat file is used by the cluster framework for their crash recovery procedure. Since grastate.dat is only written if a node is shutdown properly, the cluster uuid and the local seqno is also stored in the database and will be send to the selected donor for requesting an IST.
The cluster framework also creates the gvwstate.dat file and updates this file when the cluster forms or changes the Primary Component. This ensures that the node retains the latest Primary Component state that it was in. If the node loses connectivity, it has the file for reference. If the node shuts down gracefully, it deletes the file.
Q: Is it possible that a secondary node can be used to create another secondary to avoid any additional load on the primary node?
A: Yes, it is possible. Set parameter CLUSTER_DONOR_NAME=<node name of existing secondary> before starting the new secondary node.
Q: What about client behavior in case of a forced primary node switch or an unexpected outage?
A: Session failover is not possible, so the client will receive a nucleus response 9 indicating the end of the former session. The application should implement the required exception handling accordingly (same as a non-cluster mode).
Q: What happens if I accidentally try to re-join a cluster node to nodes of another cluster?
A: When a node attempts to re-join an existing cluster, it compares its own cluster UUID to the existing cluster nodes. If the cluster UUID does not match, the connecting node typically requests a state transfer (ADABCK dump/restore) from the cluster. Adabas protects an existing cluster database so that it is not overwritten by a node with a different cluster UUID.
Following error message is written to the nucleus logfile
... E-ADAADC, UUID mismatch ...