概念設計段階で分けたレコードタイプごとに 1 ファイルとした Adabas データベースを設計することができます。 この構成はどんなアプリケーション機能をもサポートし、突発的な要求を扱うのに最も簡単ですが、パフォーマンスという観点からみると必ずしも最良とはいえません。
Adabas ファイルの数が増えるにつれ、Adabas コールの数も増えます。 各 Adabas コールは解釈、整合性チェックが必要であり、マルチユーザーモードではスーパーバイザーコール(SVC)とキューイングのオーバーヘッドが発生します。
1 つ以上のインデックス、アドレスコンバータ、また各ファイルのデータストレージブロックにアクセスするために必要な I/O オペレーションに加えて、レコードタイプあたり 1 ファイルの構造にはバッファプールスペースが必要なので、後で要求に必要なブロックが上書きされる可能性があります。
したがって、クリティカルなプログラムが使用する Adabas ファイルの数を減らした方がよい場合があります。 それには、次のような手法を使用します。
マルチプルバリューフィールドとピリオディックグループを使用します。
Adabas ファイル内に複数のレコードタイプを入れます。
複数の物理ファイルをリンクして 1 つの論理(拡張)ファイルにします。
データの重複を制御します(リソースの使用を少なくします)。
これらの各手法については、後述します。
このドキュメントでは、次のトピックについて説明します。
次の例は、ピリオディックグループの実用的な使い方を示しています。
| 注文番号 | 注文日 | 発送日 | 顧客番号 | 入手日 | 品目コード | 数量 |
|---|---|---|---|---|---|---|
| A1234E | 29MAR | -- | UK432M | 10JUN | 24801K | 200 |
| -- | 15APR | 30419T | 100 | |||
| -- | 01JUN | 273952 | 300 |
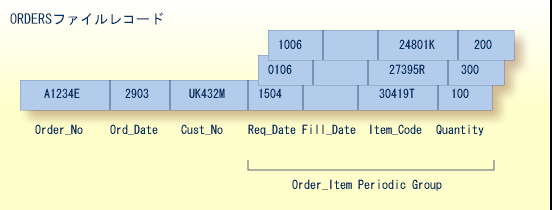
上の例では、表に示されている注文情報が ORDERS という名前の Adabas ファイルのレコードフォーマットに変換されています。 すべての注文レコードにはピリオディックグループが含まれており、注文品の数が可変であることを可能にしています。 この場合、ITEM_CODE フィールド(品目コード)と関連フィールド QUANTITY(数量)、REQ_DATE(入手日)、FILL_DATE(発送日)を含むピリオディックグループ ORDER_ITEM で、1 つのレコードに最大 65,534 個の異なる品目を指定できます。 ORDER_ITEM ピリオディックグループの 1 回ごとの出現をオカレンスといいます。ピリオディックグループあたり最大 65,534 回のオカレンスが可能です。
注意:
ファイル中で 191 個を超える MU フィールドまたは PE グループを使用することは、そのファイルが明示的に許可されている必要があります(デフォルトでは許可されません)。 この場合には、ADADBS MUPEX 機能または ADACMP COMPRESS MUPEX および MUPECOUNT パラメータを使用します。
ピリオディックグループ構造を選択した理由は、ピリオディックグループのユニークな特徴、すなわち、オカレンスの順番を維持する能力のためです。 最初に 3 つのオカレンスが含まれていたピリオディックグループは、第 1 または第 2 オカレンスが削除されると、それらのオカレンスが空値にセットされます。第 3 のオカレンスは、そのまま 3 番目の位置に残されます。 これとは対照的に、マルチプルバリューフィールドは、先行する空値エントリを異なった方法で処理します(下記参照)。
また、ORDERS ファイルのレコードフォーマットは、論理的には必ずしも最適ではありませんが、データベースのスペースを節約するために、空値を含む可能性が高いフィールドはレコードの終わりにまとめておく必要があります。 したがって、ピリオディックグループを構成するフィールドは、レコード内のその他のフィールドの後に結合させます。
ORDERS ファイルのレコード構造は、注文管理に適していますが、在庫管理には適しません。 ORDERS ファイル中の品目の在庫管理アプリケーションは、まったく異なるレコード構造を必要とします。 これらのレコードは、STOCK と呼ばれる異なるデータベースファイルに保持されています(下図参照)。
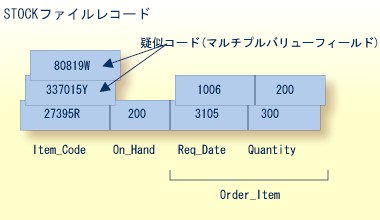
STOCK のレコードフォーマットは、ORDERS ファイルのフォーマットよりも在庫管理アプリケーションに適しています。 このレコード設計は、在庫がなくなった他品目との交換用として品目を指定しています。 ITEM_CODE(品目コード)フィールドにマルチプルバリューを入力できるので、現在の在庫品目は、すでに新しい品目に置き換えられている在庫切れになった品目の番号でも参照できます。つまり、旧品目を参照すると自動的に新しい在庫品目が選択されます。 このためには、ITEM_CODE(品目コード)フィールドをマルチプルバリューフィールドとして定義する必要があります。
例えば、品目 80819W と 337015Y が在庫切れになると、それらの品目コードは品目 27395R の別名となります。 在庫切れになった品目を参照するアプリケーションプログラムは、最初にすべての ITEM_CODE 値から旧コードを探し出した後、マルチプルバリューフィールドの 1 番目の ITEM_CODE 値を参照することで置き換えを識別できます。
ITEM_CODE フィールドには、ファイルの設定によって 1~65,534 の値が含まれます。 しかし、ピリオディックグループとは異なり、値の 1 つが削除された場合、マルチプルバリューフィールド中の個々の値は初期の位置を保持し続けません。 例えば、上記の STOCK レコード中の品目 337015Y が在庫切れになって疑似コードが空値にセットされると、80819W が自動的に ITEM_CODE の第 2 オカレンスになります。
マルチプルバリューフィールドやピリオディックグループの使用法に関しては、次のような制限があります。
マルチプルバリュー(MU)フィールドの値の最大数は 65,534 です。 許可される実際のオカレンス数は、ファイルごとに明示的に設定する必要があります(デフォルトでは許可されていません)。 この場合には、ADADBS MUPEX 機能または ADACMP COMPRESS MUPEX および MUPECOUNT パラメータを使用します。
ピリオディックグループ(PE)のオカレンスの最大数は 65,534 です。 許可される実際のオカレンス数は、ファイルごとに明示的に設定する必要があります(デフォルトでは許可されていません)。 この場合には、ADADBS MUPEX 機能または ADACMP COMPRESS MUPEX および MUPECOUNT パラメータを使用します。
ピリオディックグループの中に別のピリオディックグループを含めることはできません。
1 オカレンスの圧縮後のサイズによっては、Adabas がサポートする最大レコード長より大きなレコード長になることもあります。
ピリオディックグループ内のディスクリプタや、ピリオディックグループ内のフィールドから作られるサブディスクリプタやスーパーディスクリプタは、論理順読み込みの制御や、検索コマンド、ソートコマンドのソートキーとしては使用できません。 さらに、マルチプルバリューフィールドやピリオディックグループ内のフィールドのディスクリプタをいくつか含む検索要求については、特別な規則があります。 これらの規則については、『Adabas ユーティリティマニュアル』の ADACMP ユーティリティのセクションで説明しています。
ファイル数を減らすもう 1 つの方法に、同一 Adabas ファイルに 2 つの論理レコードタイプのデータを格納するという方法があります。 次の例は、顧客ファイルと注文ファイルとを組み合わせる方法を示しています。 この手法は、Adabas の空値省略機能の利点を活用しています。
組み合わせたファイルのフィールド定義テーブルにあるフィールドは次のとおりです。キー、レコードタイプ、注文データ、注文品目データ格納されるレコードは、次のとおりです。キータイプ注文データ*、キータイプ*、注文品目データ *は空値省略を示します。
注文項目レコードのキーは、注文番号とこの注文内のシーケンス番号から構成されます。
この手法では顧客レコードと注文レコードタイプが各種のコントロールブロックと上位レベルのインデックスブロックを共用するので、入出力回数を減らすことができます。 したがって、ファイルの処理を開始するために読み込むブロック数も減り、空きスペースが増えるため、バッファプールには別タイプのブロックを読み込むことができます。
顧客レコードと注文レコードは、データストレージにいっしょにグルーピングされるので、ある顧客に対するすべての注文を検索するとき読むブロックを減らすことができます。 顧客と同時に全注文を追加するときも、必要な入出力回数が少なくなります。 後で注文を追加する場合、このように最初からグルーピングされない可能性もありますが、ADAORD ユーティリティを使用して、後からグルーピングできます。
顧客データと注文データのどちらも効率良くアクセスできるように、キーの設計は注意しなければなりません。 同じ顧客に属する各注文を区別できるように、顧客レコードのキーの接尾語は通常、空値です。例を次に示します。
A00231 000 注文 A00231 の注文ヘッダー、A00231 001 注文品目 1、A00231 002 注文品目 2、A00231 003 注文品目 3、A00232 000 注文 A00232 の注文ヘッダー、A00232 001 注文品目 1
プログラムではキーの接尾語の内容により顧客レコードか注文レコードか区別できるのでレコードタイプフィールドは不要です。 プログラムは付加フィールドを読むためにレコードを読み直すか、あるいはどちらのレコードタイプに関するフィールドすべて返す必要があります。
3 バイト ISN の Adabas ファイルには最大 16,777,215 件までのレコードを収容でき、4 バイト ISN の Adabas ファイルには 4,294,967,294 件までのレコードを収容できます。 同じタイプのレコードが大量に存在する場合は、複数の物理ファイルに分散させる必要があります。
アクセスするファイル数を減らすために、同一フォーマットのレコードをもった複数の物理ファイルをリンクして、1 つの論理ファイルに結合することができます。 このようなファイル構造のことを拡張ファイルと呼び、この拡張ファイルを構成する物理ファイルのことをコンポーネントファイルと呼びます。 拡張ファイルは、それぞれに異なった論理 ISN の範囲を持った 128 までのコンポーネントファイルによって構成されます。 1 つの拡張ファイルのレコード数は、4,294,967,294 までです。
注意:
Adabas バージョン 6 では、より大きいファイルサイズ、より多くの Adabas 物理ファイルやデータベースがサポートされるので、拡張ファイルの必要性はほとんどありません。
アプリケーションプログラムから論理ファイルがアクセスされても(ファイルのアドレスは拡張ファイルの基本コンポーネントの番号、あるいはアンカーファイル)、Adabas では基準フィールドとして定義したフィールドのデータに従って正しいファイルが選択されます。 このフィールドのデータは 1 つのコンポーネントファイル内でのみ、レコードをユニークに識別する特性を持ちます。 アプリケーションが拡張ファイルを更新するとき、Adabas は更新するコンポーネントファイルを決定するために書き込むレコードの基準フィールドのデータを検索します。 拡張ファイルデータを読み込むとき、Adabas は論理 ISN をキーとして使用し、正しいコンポーネントファイルを見つけます。
Adabas ユーティリティは常に拡張ファイルを認識している訳ではありません。つまり、一部のユーティリティオペレーションはすべてのコンポーネントファイルに対してユーティリティ機能を自動的に実行するが、他のユーティリティは各物理ファイルのみを認識します。 詳細については「拡張ファイル」を参照してください。
ディテールレコードをアクセスするたびに、ヘッダーレコード内のいくつかのフィールドが、必要になる場合があります。 例えば、請求書を作成するには、注文項目データと製品レコードの一部である製品の記述が必要です。 この情報がプログラムで迅速に使用できるようにする最も簡単な方法は、注文項目データ内に製品記述情報のコピーを持つことです。 すでに、他(この場合は製品レコード)で物理的に存在するデータを重複して持つので、これを "物理的重複" といいます。 各ディテールレコードのフィールドをいくつかヘッダーレコード内にピリオディックグループとして格納すれば物理的重複は有効です。
物理的重複は、ほとんど更新されないフィールドに限定して使用すれば、滅多に問題にはなりません。 上記の例では、製品記述情報はほとんど変更されません。重複フィールドに対するアクティビティが少ないほど、よい結果になります。
クレジットコントロールルーチンが顧客に送るすべての請求書の合計を必要とすると仮定します。 この情報は関連する請求書を読み合計して求めるので、大量のレコードをランダムにアクセスすることになります。 したがって、この情報が顧客レコード内に常に格納され、正しく更新されていれば、もっと迅速に得ることができます。 これを、論理的重複といい、この情報そのものはすでに他に存在するのではなく別のレコードの内容に暗に含まれています。
物理的または論理的に重複している情報を更新するプログラムでは、重複しているデータの両方を更新しなければならないので処理は遅くなります。 論理的重複では、たいていの場合 1 レコードの変更が他の何レコードかのデータに影響するので、更新も重複して行わねばなりません。 論理的重複は、TP 環境では同一レコードを多くのユーザーが更新しなければならないので、効率が著しく低下します。
Adabas ファイル構造が決まったら、通常、次にはファイルに対するフィールド定義テーブルを定義します。 フィールド定義は、『Adabas ユーティリティマニュアル』で説明しているように、入力ステートメントとして ADACMP ユーティリティの COMPRESS 機能に入力します。このセクションでは、フィールドに対して使用できるオプションとパフォーマンスとの関係について述べます。
ファイルのフィールドは、読み込みや更新の頻度の高い順に先頭から並べる必要があります。 こうすると、スキャンするフィールド数が減るので、データ転送に必要な CPU 時間が少なくてすみます。 読む頻度が低いが主に検索条件として使用するというフィールドは、後の方に置くべきです。
例えば、ディスクリプタフィールドがレコード構造の最初に配列されず、論理的に物理レコードの終了を超えた場合、パフォーマンスの理由から、そのレコードに対するインバーテッドリストエントリが生成されないことに注意してください。 このケースでインバーテッドリストエントリを生成するには、ファイルのアンロード(SHORT モード)、圧縮解除、そして再ロードが必要です。あるいは、アプリケーションプログラムを使用してフィールドをファイルの各レコードの最初に再配列します。
複数フィールドを常に一緒に読み更新するなら、これらを 1 つの Adabas フィールドとして定義すれば CPU 時間を減らすことができます。 このようにフィールドを組み合わせた場合の短所としては、次のものがあります。
フィールドを組み合わせると圧縮の可能性が低くなるので、追加のディスクスペースが必要です。
SQL のような問い合わせ言語プログラムで、このようなフィールドを扱うのは難しくなります。
グループを使用すると、読み込みや更新コマンドの内部処理の効率が良くなります。 つまり、Adabas コントロールブロックのフォーマットバッファが短くなるので、 処理時間が短くなり、内部フォーマットバッファプールが少なくてすみます。
数値フィールドは、最もよく使用するフォーマットを指定する必要があります。 こうすれば、必要になるフォーマット変換が最小限になります。
固定ストレージ(FI)オプションを使用すると、フィールドの処理時間は減りますが、必要なディスクスペースが増え、特にピリオディックグループ内のフィールドのときは著しくなります。 FI フィールドは、NU フィールドと同様に、できるだけまとめる必要があります。