このドキュメントで説明されるアドオン製品は、機能または製品に対する個別の購入契約を交わした Adabas のお客様が使用できます。
このドキュメントでは、次のトピックについて説明します。
Adabas Bridge テクノロジにより、DL/I(および IMS/DB)および VSAM アプリケーション開発環境への効果的なアクセスが可能になります。 エミュレーションは、アプリケーションプログラムの修正が必要なく、従来の変換に付随する遅延や労力を避けることができます。
注意:
ソリューションは、TOTAL および SESAM でも使用できます。
Adabas Bridge テクノロジには次の特徴があります。
ユーザーアプリケーションの透過性。既存のアプリケーションプログラムを変更したり、ネイティブの VSAM または DL/I コールを使用するサードパーティ製アプリケーションソフトウェアを変更したりする必要はありません。
バッチおよびオンライン処理環境、RPG、COBOL、PL/I、FORTRAN、およびアセンブラプログラム言語のサポート
データおよびアプリケーションの保全性
Adabas Bridge for VSAM(AVB)により、VSAM 環境内のデータにアクセスするために作成されたアプリケーションソフトウェアで、Adabas 環境のデータにアクセスできるようになります。 AVB はバッチモードでもオンライン(CICS 配下)でも動作し、z/OS および VSE オペレーティング環境で使用できます。
また、AVB は Adabas ファイルのみ、VSAM ファイルのみ、または Adabas および VSAM ファイル両方(混合環境)の環境で実行可能です。 混合環境で動作可能であるということは、必要性およびリソースに合わせて移行計画を調整できることを意味します。 必要に応じて VSAM から Adabas にファイルを移行できます。1 つのアプリケーション、1 つのファイルを個別に移行することも可能です。
AVB は、透過テーブルを使用して、VSAM ファイルの名前および構造を対応する Adabas ファイルの番号および構造とマッピングします。 VSAM ファイルが Adabas に移行されて AVB 透過テーブルで定義されると、Adabas へのブリッジが可能となります。 VSAM ファイルがブリッジされると、AVB は VSAM ファイルへの各要求を Adabas コールに変換して、VSAM ファイルの代わりに Adabas ファイルがアクセスされます。
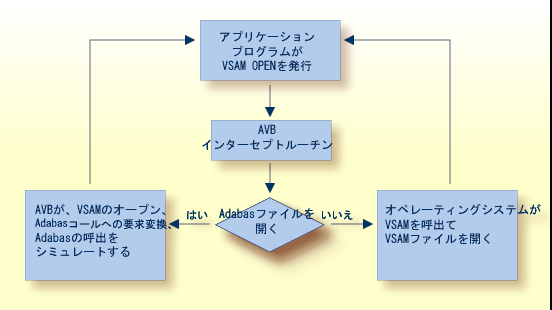
AVB がアクティブな場合、各ファイルの OPEN および CLOSE 要求をインターセプトして、Adabas ファイルに対する要求を処理するかどうかを判定する一連のチェックを実行します。 Adabas ファイルに対する要求を処理しない場合、AVB は、参照する VSAM ファイルを開くことができるように、要求をオペレーティングシステムに渡します。
AVB が、ブリッジされたファイルに対する OPEN または CLOSE 要求を検出した場合、この要求を Adabas コマンドに変換して Adabas をコールし、対応する Adabas ファイルを開いたり閉じたりします。 OPEN の実行後は、VSAM ファイルに対するすべての読み込みおよび更新要求は、直接 AVB に渡されます。
AVB は、VSAM コントロールブロックを割り当てて、標準の VSAM ファイル要求から結果が返されたときと同様に、アプリケーションが結果を処理できるように必要な情報を挿入します。 Adabas コールの後で、AVB は標準の VSAM コントロールブロックおよびワークエリアを使用して、結果をアプリケーションに返します。
以前に VSAM ファイル構造のみが使用されていた環境で Adabas を使用できるようになると、次の利点を得ることができます。
Adabas の強力なインデックス機能により、アプリケーションを拡張できます。 効果的なビューやパスを使用した、データの問い合わせ、取得および操作が可能になります。
Natural や SQL などのプログラミング言語を使用してアプリケーションを拡張できます。
アプリケーションプログラムがデータ構造から独立しているため、メンテナンスのコスト削減、プログラマの生産性の向上が図れます。
自動再スタート/リカバリにより、ハードウェアまたはソフトウェアの障害時に、データベースの物理的な保全性を確保できます。
データの圧縮により、必要なオンラインストレージの容量が飛躍的に削減され、また 1 回の物理 I/O で多くの情報を転送できるようになります。
パスワード保護と、ファイルおよびフィールドレベル、さらにデータ値に基づくレコードレベルの保護によりセキュリティが向上します。
ユーザー指定の暗号化処理用キーなどの暗号化オプションを利用できます。
移行後は、使用しているアプリケーションプログラムのデータの見え方は以前と変わりませんが、新しい Adabas ファイルを構成して上記で要約した利点を最大限に活用できます。
Adabas にファイルを認識させるテーブルはアプリケーションの外部にあり、アプリケーションプログラムを再リンクすることなく変更できます。 このような特性があるため、ファイルまたはセキュリティ情報を変更するとき、またはアプリケーションのステータスをテストから実稼動に移行するときに特に便利です。
Adabas Bridge for DL/I(ADL)は、DL/I または IMS/DB データベースを Adabas へ移行するためのツールです。 DL/I という用語は、IMS/VS および DL/I DOS/VS を示す一般的な名称として使用されています。 ADL はバッチモードでもオンライン(CICS または IMS/DC 配下)でも動作し、z/OS および VSE オペレーティング環境で使用できます。
DL/I アプリケーションは変更せずに続けて実行できます。Adabas SQL Gateway が使用可能な場合、移行されたデータには Natural および SQL アプリケーションによりアクセスできます。 ADL は、Adabas データベースに対して標準の DL/I アプリケーションを実行するために使用できます。
ADL は次の 6 個の主要な機能で構成されます。
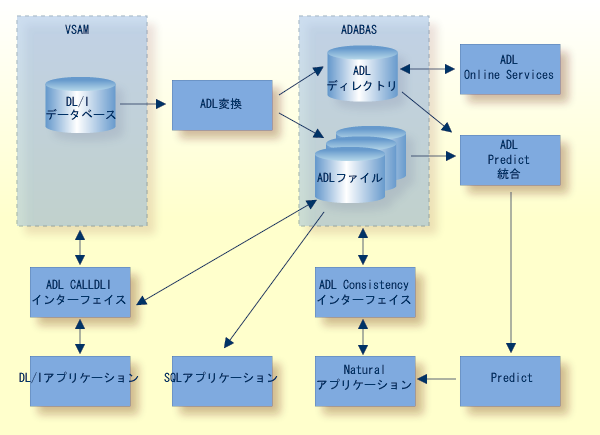
DL/I データベースを ADL ファイルと呼ばれる Adabas ファイルに自動的に変換する変換ユーティリティの集合。ADL ファイルは、ネイティブの Adabas ファイルにはないこれらのファイルの性質が特徴付けられています。
変換処理の結果として、DL/I データベース定義(DBD)および関連する Adabas ファイルレイアウトが、ADL ディレクトリと呼ばれる Adabas ファイルに格納されます。ADL ディレクトリには、ADL エラーメッセージやその他の情報も格納されます。
ADL ディレクトリの内容のレポートなどの、多くのオンラインサービスを提供する Natural で記述されたメニュー型のアプリケーション。
ADL ディレクトリのデータを使用して ADL ファイルの Predict 定義を生成する、特別な一連の統合プログラム。Predict 定義は、Natural ビューを生成するために使用されます。
DL/I アプリケーションが、元の DL/I データベースへのアクセスと同じ方法で ADL ファイルにアクセスする(および混在モードで両方のデータベースに同時にアクセスする)ためのコールインターフェイス。 このインターフェイスは、アセンブラ、COBOL、PL/I、RPG、FORTRAN、および DL/I 用の Natural をサポートします。 EXEC DLI インターフェイスを使用するプログラム用に、特別なプリコンパイラが用意されています。
Natural アプリケーションまたは Adabas ダイレクトコールを使用しているプログラム用の ADL ファイルへのアクセスを可能にする整合インターフェイス。 このインターフェイスは、現行の DL/I アプリケーションにとって重要なデータの階層構造を維持します。
以前に DL/I ファイル構造のみが使用されていた環境で Adabas を使用できるようになると、次の利点を得ることができます。
データは、Software AG の第 4 世代言語、Natural で操作できるようになります。
データは、Adabas によりフィールドレベルで自動的に圧縮されます。
削除されたデータレコードは、すぐにストレージから解放されます。 これは、削除されたデータレコードにフラグを立てるだけで、そのレコードが使用しているストレージが解放されない DL/I とは対照的です。 Adabas では、解放されたスペースは、新しいレコードによってすぐに再使用が可能です。削除としてマークされたレコードの維持は不要です。また、データベースの再構成の必要性が少なくなります。
元のアクセスメソッドに関係なく、すべての変換された DBD は完全な HIDAM 機能を備えています。
データのアンロードおよび再ロードをせずに、フィールド長を長くすることができます。
DBD をアンロードおよび再ロードせずに、DBD の最後にセグメントを追加できます。
オンラインおよびバッチモードでトレース機能を使用できます。
バッチモードの CALLDLI テストプログラムを使用できます。
DL/I とは異なり Adabas は CICS リージョン/パーティション内で実行しないため、オンラインのシステムリソースを削減できます。
VSE 配下で、シンボリックチェックポイント機能を使用できます。
HD データベースを z/OS 上で使用できます。
Adabas Caching Facility は、システムパフォーマンスの向上を支援し、拡張メモリ、データスペース、ハイパースペース、z/OS バージョン 1.2 以降の環境の 64 ビット仮想ストレージ内の Adabas バッファプールを増強して ESA 機能を完全に使用できるようにします。
Adabas Caching Facility は、データベースへのチャネル実行プログラム(EXCP、BS2000 では UPAM SVC)の読み込み回数を削減することにより、Adabas バッファマネージャを増強します。 これにより、貴重な仮想メモリリソースを独占することなく、オペレーティングシステムに存在する機能を使用できるようになります。
注意:
データベースの保全性を維持するために、常に書き込み EXCP が発行されます。
Adabas Caching Facility は機能的には Adabas バッファマネージャと同等ですが、次の機能が追加されています。
必要性が生じたときにすぐにアクセスできるように、ユーザー指定の RABN(ブロック)をキャッシュまたは確保することが可能です。これは、アクティブなバッファプール内に RABN を保持するだけのアクティビティがない場合でも可能です。 RABN を確保しておくと、Adabas ニュークリアスがこれらの RABN を再読み込みする必要が生じた場合でも、それにかかる I/O レスポンスタイムを削減できます。
Adabas WORK データセットパート 2 および 3 をキャッシュして、大量の複雑な問い合わせを処理する環境におけるパフォーマンスを向上できます。 Adabas WORK パート 2 および 3 は、複雑な問い合わせの ISN リストの解決および維持に使用される中間ワークエリアとして機能します。 これらの複雑な問い合わせに使用する WORK パート 2 および 3 への EXCP の読み取りと書き込みの回数を減らすことにより、飛躍的に処理時間を短縮して、パフォーマンスを大幅に向上できます。
ファイルまたはファイルの範囲を指定して、すべての関連する RABN をキャッシュできます。 必要に応じて、アソシエータまたはデータストレージブロックのみをキャッシュすることも可能です。 ファイルは、サービスのクラスを割り当てて優先順位をつけることができます。サービスのクラスによって、使用可能最大キャッシュスペースのうち、指定されたファイルが使用できる割合と、いつファイルの RABN ブロックをキャッシュから削除するかが決まります。
次に示す内容を変更すると、オペレータコマンドを使用して、変化するデータベース環境に対してダイナミックに対応させることができます。
RABN 範囲、ファイル、またはファイル範囲ごとにキャッシュする RABN
RABN 範囲、ファイル、またはファイル範囲ごとに有効化または無効化する RABN
Adabas Caching Facility により使用されるシステムリソースを確保および解放するタイミング
先読みキャッシングオプションを使用して、連続する Adabas コマンド(例えば、論理的読み込み、物理的読み込み、ヒストグラム、非ディスクリプタを使用した検索)を処理する場合、1 つの EXCP が発行され、ディスクデバイスの単一トラックに存在するすべての連続する ASSO または DATA ブロック、またはその両方が読み込みまれます。 ブロックはキャッシュに保持されて、ニュークリアスが次のブロックを順次要求するときに、すぐに利用できます。 この機能により、3380 の ASSO の物理読み込み I/O の数を最大 1/18 まで削減して、パフォーマンスを向上させることができます。
Adabas RABN は、Adabas バッファプールとキャッシュの両方に同じものが保持されるわけではないので、データベースの保全性は維持されます。 Adabas RABN は、Adabas バッファプールまたはキャッシュエリアのどちらかに存在することはありますが、両方に存在することはありません。 すべてのデータベース更新、およびその結果のすべてのバッファフラッシュは、Adabas バッファプールから行われます。 他のキャッシュシステムとは異なり、この非冗長キャッシュメカニズムは、貴重なシステムリソースの使用を節約します。
オンラインのキャッシュメンテナンスアプリケーションである Cache Services を使用するには、Adabas Online System のデモ版またはフル機能版が必要です。 詳細は、Adabas Caching Facility のドキュメントを参照してください。
Adabas Cluster Services により、マルチニュークリアス、マルチスレッド並列処理が実装され、IBM 並列シスプレックス(systems complex)環境の Adabas を最適化します。 シスプレックスクラスタ内の Adabas ニュークリアスは、Sysplex Timer� (IBM)により同期された複数の z/OS イメージに分散させることができます。 1 つ以上の Adabas ニュークリアスを 1 つの z/OS イメージ内で実行できます。
Adabas Cluster Services は、z/OS イメージ間および各シスプレックスニュークリアスクラスタ内の関連する Adabas ニュークリアス間の相互コミュニケーション能力およびデータ保全性を保証するソフトウェアコンポーネントで構成されています。 最大 32 個のクラスタ化されたニュークリアスでそれぞれ構成されるシスプレックスクラスタの数は、シスプレックス内の複数の z/OS イメージでは制限がありません。
並列処理によりスループットが向上するだけでなく、Adabas Cluster Services では、意図的であれ突発的であれシステムが停止状態になっても、データベースの可用性が高くなります。特定のオペレーティングシステムイメージまたはクラスタニュークリアスにメンテナンスが必要になった場合、またはこれらが予期せずにダウンした場合でも、データベースは引き続き利用可能な状態が維持されます。
1 つ以上のオペレーティングシステムイメージが含まれるクラスタ環境をサポートするため、限られた Software AG Entire Net-Work ライブラリが Adabas Cluster Services の一部として含まれています(「Entire Net-Work マルチシステム処理ツール」を参照)。 Entire Net-Work は、Adabas および Adabas Cluster Services のコマンドを、z/OS イメージ間で相互に送信するために使用されます。 このプログラムは、シスプレックスクラスタ内のニュークリアス間のコミュニケーションメカニズムを提供します。 Adabas Cluster Services に対応するために、Entire Net-Work には変更が加えられていません。
クラスタ化されたニュークリアスを監視および制御するために、ADACOM モジュールが使用されます。 各クラスタについて、そのクラスタに参加しているニュークリアスを含む各 z/OS イメージ、またはクラスタデータベースにアクセスするユーザーを含む各 z/OS イメージ内で ADACOM モジュールを実行する必要があります。
Adabas Cluster Services SVC コンポーネントの SVCCLU は、Adabas SVC にあらかじめリンクされ、ローカルおよびリモートのニュークリアスにコマンドをルーティングするために使用されます。 CSA スペースは、ローカルおよびリモートのアクティブなニュークリアス、および現在アクティブなユーザーの情報を維持するために使用されます。
シスプレックスキャッシュ構造は、セッション中に更新された ASSO/DATA ブロックを保持するために使用されます。 このキャッシュ構造により、ニュークリアス、ユーザー、および z/OS イメージが同期され、データの保全性が確保されます。また、複数のニュークリアスの再スタートおよびリカバリが処理されます。
Adabas Online System は、シスプレックスクラスタ内のすべてのニュークリアスと通信します。
Adabas Caching Facility は、クラスタ化されたニュークリアスをサポートし、そのクラスタのパフォーマンスを向上させます。
Adabas Cluster Services 環境では、さまざまなネットワークノード上のユーザーは、Entire Net-Work により複数の z/OS イメージにまたがる論理データベースの問い合わせが可能になります。 ユーザーは、従来の単一ノードデータベースにアクセスするように、クラスタデータベースにアクセスします。
既存のアプリケーションを変更しなくても、Adabas に要求を送ることができます。 要求はシステムにより自動的に処理されます。処理の流れはアプリケーションに対して透過的です。
Entire Net-Work は、オペレーティングシステムインターフェイス用、およびリージョン間コミュニケーション用の Adabas に依存するサービスルーチンを使用して互換性を維持します。 Entire Net-Work を実行するためのジョブ制御ステートメントは、Adabas を実行するためのジョブ制御ステートメントと非常に似ています。 例えば、EXEC ステートメントは Entire Net-Work 用の ADARUN プログラムを実行します。これは、Adabas においても同様です。また、Entire Net-Work 用の ADARUN パラメータは、Adabas パラメータのサブセットです。
ターゲットまたはサービスがネットワークとのコミュニケーションを確立していても、またはコミュニケーションが終了していても、ステータス情報はすべてのノードにブロードキャストされるため、一元的な場所でデータベースまたはターゲットのパラメータファイルを維持したり、それらのファイルを参照する必要はありません。
各ノードでは単一の Entire Net-Work タスクのみが許可されているため、すべての必要な情報を 1 か所で維持することによるネットワークトポロジーに対する制御が行われます。 これにより、ネットワークの運用およびメンテナンスの混乱が回避できます。 ただし、追加のルーターをインストールすることにより、必要に応じて複数の Entire Net-Work タスクを実行することもできます。
各 Entire Net-Work ノードは、要求キューとアタッチドバッファプールのみを 1 つずつ維持するため、バッファストレージの使用を節約できます。 特定のコマンドに不要なすべてのバッファは、転送から除外されます。 さらに、レコードバッファおよび ISN バッファの中で、実際にデータが存在する部分のみが、データベース応答でユーザーに返されます。
Entire Net-Work のバッファサイズのサポートは、Adabas のバッファサイズサポートに相当するため、Adabas で有効なすべてのサイズのバッファをリモートノードに転送できます。
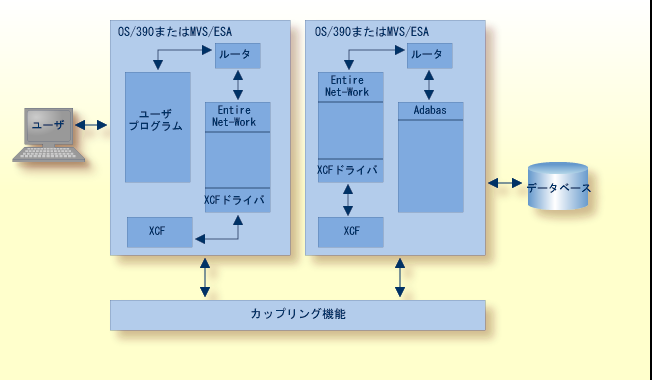
実際のネットワークデータトラフィックは、IBM のシステム間カップリング機能(XCF)へのインターフェイスである Entire Net-Work XCF Option により制御されます。XCF は、システム上の認証済みアプリケーションが同一のシステムまたは他のシステム上のアプリケーションと通信できるようにします。 XCF は、シスプレックス内の 1 つまたは複数の z/OS イメージに存在するグループのメンバ間でデータおよびステータス情報を送信します。
各 Entire Net-Work ノードに Entire Net-Work XCF Option をインストールすると、パフォーマンスが高くなり、シスプレックス内の異なる CPU 上の z/OS イメージ間の透過的なコミュニケーションを可能にします。 他のノードへの複数接続がサポートされ、ラインドライバのモジュラー設計により、新しいアクセスメソッドのサポートをシステムに簡単に追加できます。
メンバは、マルチシステムアプリケーションの特定の機能(1 つ以上のモジュール/ルーチン)です。メンバは XCF に定義され、マルチシステムアプリケーションによりグループに割り当てられます。 メンバは、シスプレックス内の z/OS イメージ上に存在し、XCF サービスを使用して、同一グループ内の他のメンバと通信(データの送受信)できます。 XCF ラインドライバを実行している各 Entire Net-Work ノードは、Entire Net-Work 接続用に特別にセットアップされたグループ内の異なるメンバとして認識されます。
Adabas Delta Save(DSF)は、Adabas データベースの変更部分(デルタ)のみをバックアップすることにより、ADASAV ユーティリティの処理を著しく向上させます。 作成される保存出力の量を削減し、保存操作の時間を短縮します。これにより、データベースの可用性が向上します。 より頻繁に保存操作を実行できるため、データベースのリカバリに要する時間も削減できます。
Adabas Delta Save の特徴は次のとおりです。
データベースの可用性を低下させることなく、頻繁な保存が可能
24 時間無休のオペレーションの強化
データベースをアクティブに保ちながら、完全にオフラインで保存
リカバリにおける REGENERATE 時間の短縮
Adabas Delta Save は、最後の保存操作以降に変更された(デルタ部分)アソシエータおよびデータストレージブロックのみを保存することにより、上記の目的を達成しました。 この操作の出力先は、デルタセーブテープと呼ばれます。 より少ない量の出力がデルタセーブテープに書き込まれるため、セカンダリ(テープ、カセットなど)ストレージへの接続の必要性が減少します。
Adabas Delta Save には、次の機能が備わっています。
変更されたデータベースブロック(RABN)のログの保持
データベースのオンライン中における、必要に応じた中間デルタセーブテープの作成およびマージ
最新のデータベースセーブテープとデルタセーブテープの統合による、最新のフルセーブテープの作成
最新のフルセーブテープおよびその後のデルタセーブテープからのデータベースのリストア
Adabas Delta Save は、高い可用性が求められる 1 つ以上の大容量で頻繁に更新されるデータベースを持つ Adabas サイト用に設計されています。 1 日に変更されるデータ量がデータベースの合計サイズと比較して非常に少ない場合、特に有益です。
DSF を使用するには、デモ版またはフル機能版の Adabas Online System が必要です。 詳細については、『Adabas Delta Save Facility マニュアル』を参照してください。
Adabas Fastpath では、レスポンスタイムの迅速化と、リソース使用量の節約が実現されています。これは、参照データの場所をできるだけユーザーに近い場所に設定すること、オーバーヘッドを減らすこと、さらには要求をローカル(同一のリージョンまたはパーティション内)で処理することによって達成しています。
FASTPATH は、アプリケーション処理内で Adabas の問い合わせを解決できるため、データベースとの問い合わせの送受信に必要なオペレーティングシステムのオーバーヘッドを回避できます。 コマンドキュー処理、フォーマットプール処理、バッファプールスキャン、および圧縮解除などのデータベースアクティビティも回避できます。
FASTPATH は、問い合わせサンプラを使用して、次の問い合わせを効果的に識別します。
最も多く発行される共通のダイレクトアクセスの問い合わせ。この問い合わせでは、クライアントは ISN、検索値などの検索対象データを識別します。
順次アクセスの問い合わせ。この問い合わせでは、クライアントは、シーケンスまたは検索条件に関連した、一連のデータ項目を識別します。
問い合わせサンプラは、シャットダウン時にインタラクティブに、最適化可能な問い合わせの正確なタイプおよび相対的な使用頻度をレポートします。
問い合わせの各タイプに対して、FASTPATH は最も頻繁に使用されるデータを認識および保持しするアルゴリズムを使用して、あまり使用されないデータを破棄または上書きします。 オペレーティングシステム内のすべてのクライアントが使用できる使用量に制限がある場合は、FASTPATH は頻繁に使用されるデータ問い合わせの結果を保持して、その問い合わせが繰り返された場合は、クライアントの処理内で解決できるようにします。 保持された結果は、過去の問い合わせの実績から得られた結果を反映した共通知識ベースとして蓄積されます。 知識ベースは継続的に更新され、保持されている最も使用頻度が低いデータが破棄または上書きされる点で、ダイナミックです。
DBMS に付属の FASTPATH コンポーネントは、使用頻度の高いデータが変更されると、知識ベースに返される結果に反映します。 FASTPATH のデータは常に DBMS のデータと一致しています。
問い合わせが DBMS に渡される前に、FASTPATH の最適化機能は知識ベース内で問い合わせを解決しようとします。 知識ベース内で問い合わせが解決する場合には、問い合わせは処理間コミュニケーションまたは DBMS のアクティビティは発生しないため、処理は高速になります。 FASTPATH は、Adabas プリフェッチ先読みロジックをダイナミックに適用することにより、シーケンスを最適化して、DBMS アクティビティを削減します。 1 回の DBMS へのアクセスで、最大 256 個のデータ項目を取得できます。
FASTPATH による最適化はクライアント処理で発生しますが、アプリケーションシステムの変更は不要です。 異なる最適化プロファイルを、1 日の異なる時刻に自動的に適用することができます。 FASTPATH バッファは、一度起動すると、特に操作することなくアクティブな状態が保持されます。FASTPATH は、DBMS の起動およびシャットダウンに自動的に対処します。
詳細については、Adabas Fastpath のドキュメントを参照してください。
Adabas Native SQL は、Software AG の高水準の記述式データ操作言語(DML)です。Ada、COBOL、FORTRAN、および PL/I で記述されたアプリケーションから Adabas ファイルにアクセスするために使用します。
データベースへのアクセスは、アプリケーションプログラム内に組み込まれた SQL と似た構文で指定します。 Adabas Native SQL プリコンパイラは、次に SQL ステートメントを透過的な Adabas ネイティブコールに変換します。
Software AG の Adabas、Natural、Predict、および Software AG Editor は、Adabas Native SQL の前提条件です。Adabas Native SQL は、Natural ユーザービューの概念と Predict データディクショナリシステムを全面的に活用し、すべての Adabas の機能を利用します。
Natural フィールド指定を使用すると、Adabas Native SQL は、自動的に正しいフィールドセット、フィールド名、フィールドシーケンス、レコード構造、フィールドフィーマットおよび長さを持った Ada、COBOL、FORTRAN、または PL/I データ宣言を作成します。
Adabas Native SQL は、Predict に含まれているファイルおよびレコードレイアウトの情報を使用して、生成された Ada、COBOL、FORTRAN、または PL/I プログラムがデータベースにアクセスするために必要なデータ構造を作成します。 次に、Adabas Native SQL がプログラムを処理する過程で、プログラムがアクセスするファイルやフィールドの名前などのアクティブなクロスリファレンス(Xref)情報を Predict 内に記録します。
これらの機能は、データベースにアクセスするプログラム内に正しくないデータ宣言を書き込むリスクを排除するのに役立ちます。 さらに、これらの機能は、どのプログラムがデータベースから読み取るか、どのプログラムがデータベースを更新するかを示す総合的な記録をデータディクショナリ内に作成し、DBA に効果的な管理ツールを提供します。
詳細は、Adabas Native SQL のドキュメントを参照してください。
注意:
Adabas には、デモバージョンの Adabas Online System
が収録されており、その機能を実行することができます。また、限られた他のサービスにアクセスできます。
Adabas Online System(AOS)は、Adabas に対するオンラインのデータベース管理ツールとして使用します。 同様な機能は、バッチ方式のユーティリティのセットを使用して実現できます。
AOS は、オンラインの Adabas データベースの解析および制御に使用する一連のサービスを提供するインタラクティブなメニュー型のシステムです。 これらのサービスにより、データベース管理者(DBA)は次の操作が可能になります。
Adabas ユーザー統計の表示、特定ユーザーまたは全ユーザーのアクセスおよび操作の監視および制御
Adabas フィールドおよびファイルの表示および変更、フィールドの追加、ファイルスペースの割り当ておよび割り当て解除、ファイルおよびデータベースレイアウトの変更、フィールドディスクリプタの表示および削除
ユーティリティユーザーのみへのファイル使用の制限、ファイルアクセスの完全なロックおよびロック解除
ニュークリアスクラスタ環境および SAF Security もサポートされます。 さらに、AOS は、ADARUN パラメータをダイナミックに変更する機能も備えています。
AOS は、Software AG の第 4 世代アプリケーション開発言語である Natural で記述されています。 AOS セキュリティ機能は、Software AG の Natural Security がインストールされている場合のみ使用できます。
AOS には、Adabas オペレータコマンドおよびユーティリティに相当する機能が含まれています。
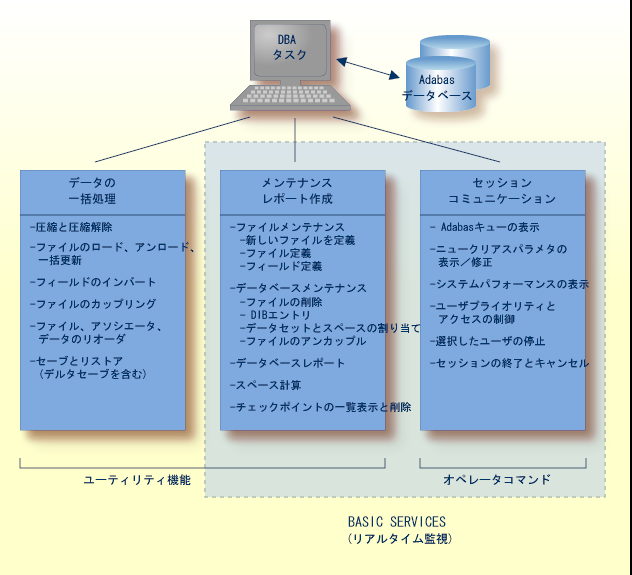
基本サービスにより、DBA は Adabas セッションがアクティブなときに、Adabas データベースのさまざまな局面をインタラクティブに監視および変更できます。 メニューオプションまたはダイレクトコマンドを使用すると、DBA はリソースのステータスおよびユーザーキューの表示、スペース割り当ての表示および変更、ファイルおよびデータベースパラメータの変更、オンラインでの新規ファイルの定義、および選択したユーザーまたは現在の Adabas セッションの停止が可能です。
AOS は、Adabas からの個別のデータセット/ライブラリとして提供されます。 Adabas から受け取った配布セットの中に最初から、AOS 機能がデモ版として収録されています。 フル機能版にするには、AOS ロードライブラリの内容を Adabas ロードライブラリにコピーするか、AOS ロードライブラリを Adabas ニュークリアス JCL の STEPLIB 内で連結させる必要があります。 さらに、AOS ユーザー(デモ版またはフル機能版)および Predict ユーザーは、Adabas ロードライブラリにあるロードモジュール AOSASM を Natural ニュークリアスにリンクしてください。
詳細は、Adabas Online System のドキュメントを参照してください。
Adabas Parallel Services(旧バージョンの ADASMP)は、マルチニュークリアス、マルチスレッド並行処理を実装し、単一オペレーティングシステムイメージ上の複数エンジンプロセッサ環境の Adabas を最適化します。
Adabas Parallel Services クラスタ内の最大 31 個の Adabas ニュークリアスが、オペレーティングシステムにより同期している複数のエンジンに分散されます。
注意:
以前の製品である Adabas support for
Multiprocessing(ADASMP)は、単一のニュークリアスの更新、およびマルチニュークリアスの読み込み機能を提供してきました。 Adabas
Parallel Services から、マルチニュークリアスの更新機能もサポートされるようになりました。
クラスタ内のすべてのニュークリアスは、1 つの物理データベースに同時にアクセスします。 物理データベースは、1 セットのアソシエータとデータストレージのデータセットから成り、単一のデータベース ID 番号(DBID)で識別されます。
ニュークリアスはお互いに通信や協調を行い、ユーザーの業務を処理します。 圧縮、圧縮解除、フォーマットバッファの変換、ソート、取得、検索、および更新操作は、すべて並行して行うことができます。
並列処理によりスループットが向上するだけでなく、Adabas Parallel Services では、意図的であれ突発的であれシステムが停止状態になっても、データベースの可用性が高くなります。特定のクラスタニュークリアスにメンテナンスが必要になった場合、またはこれらが予期せずにダウンした場合でも、データベースは引き続き利用可能な状態が維持されます。
同一または異なるルーターまたは SVC 配下の同一のオペレーティングシステムで操作できる Adabas Parallel Services クラスタの数は無制限です。つまり、個別に処理可能なデータベースの数には制限がありませんが、それぞれのデータベースの Adabas Parallel Services クラスタのニュークリアスは最大 31 個までです。
アプリケーションから参照するデータベースターゲットは 1 つだけなので、インターフェイスの変更は不要です。 アプリケーションは、変わらずに目的のデータベースと通信して、変更せずに Adabas Parallel Services クラスタのニュークリアスと通信します。
詳細は、Adabas Parallel Services のドキュメントを参照してください。
Adabas Review(旧バージョンの Review Database)は、Adabas 環境およびその環境内で実行しているアプリケーションのパフォーマンスの監視を可能にする一連の監視、計算、およびレポートツールを提供します。
Adabas の使用に関して得られた情報は、最小のリソースで最大のパフォーマンスを得るためのアプリケーションプログラムの調整に役立ちます。
Adabas アドレススペースで Adabas Review が実行しているローカルモードに加え、Adabas Review はハブモードを提供します。このモードでは、クライアント/サーバー型のアプローチを使用して、Adabas のパフォーマンス情報を収集します。
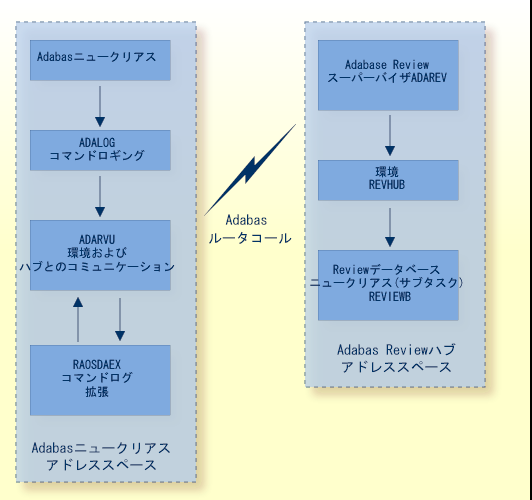
Adabas Review インターフェイス(クライアント)は、各 Adabas ニュークリアス内に存在します。
Adabas Review ハブ(サーバー)は、それ自身のアドレススペース、パーティションまたはリージョン内に存在します。
Cluster Services 統計の収集がサポートされています。 ファイルレベル(CF)のキャッシング統計および Cluster Services のロックが、ユーザー定義の間隔で長期間にわたって監視されます。 統計は、Review History ファイルに書き出され、Review のレポート機能を使用して取得または表示できます。
詳細は、Adabas Review のマニュアルを参照してください。
Adabas Review ハブは、ユーザーに対するデータ収集機能およびレポートインターフェイスです。 ハブは、Adabas データベースを監視するためのデータ集積およびレポート機能を担当します。監視するデータには、アプリケーションに関連する使用情報、コマンド、最小コマンドレスポンスタイム(CMDRESP)、I/O のアクティビティ、およびバッファ効率が含まれます。
インタラクティブなレポート機能により、問題を迅速に特定することができます。レポートには、Adabas のアクティビティの詳細および概要データが含まれます。 各データベースに特有な情報も入手できます。
実績のある Adabas および Review コンポーネントは、一元的なサーバー(ハブ)として組み合わされることにより、次の利点を得ることができます。
単一のハブは、複数の Adabas ニュークリアスおよび Adabas Parallel Services または Adabas Cluster Services により管理される Adabas ニュークリアスクラスタから情報を収集できます。 つまり、企業全体に分散した Adabas ニュークリアスをサポートするために必要な Adabas Review ニュークリアスの数を最小限に抑えることができ、リソース要件を最低限に抑えることができるため、パフォーマンスを向上できます。
各 Adabas ニュークリアスのアドレススペース、パーティション、またはリージョンを Review サブタスクの監視対象から除外することにより、Adabas メインタスクのパフォーマンスが向上します。 また、将来の Adabas のリリースが Adabas Review の機能に与える影響を最小限に抑えることができます。
ハブの構成要素は次のとおりです。
ADAREV。受信 Review データコールおよび要求を管理統括する論理モジュールです。
REVHUB。Adabas Review の環境を確立および維持するモジュールです。
RAOSAUTO などの Review ニュークリアスおよびサブシステム、自動起動レポートパラメータ生成ルーチン、および履歴データ保存ルーチンである RAOSHIST。
Adabas Review インターフェイスは、Review データを構築し、そのデータを Adabas ニュークリアスから Adabas Review ハブに送信します。 監視対象の各 Adabas ニュークリアスと、1 つの Adabas Review インターフェイスが統合されます。
インターフェイスは、既存のリージョン間コミュニケーション処理(ADALNK、ADASVC、および ADAMPM)を利用します。 このコミュニケーション処理は、サポートされる複数のプラットフォーム全体にわたって整合性が保たれています。
すべてのサポートされるプラットフォームおよびシステムが正しくネットワーク化されていれば、Adabas Review は、マルチプラットフォーム、マルチオペレーティングシステムの Adabas データベース環境をサポートします。
インターフェイスの構成要素は次のとおりです。
ADALOG。Adabas コマンドロギングモジュールです。
RAOSDAEX。Adabas コマンドログレコードに存在しない追加情報を取得する Adabas Review コマンドログ拡張モジュールです。
ADARVU。RAOSDAEX の環境の調節、および Review データを Adabas Review ハブに送信するための Adabas API 要件を処理します。
ADARVU モジュールは、Adabas ニュークリアスからのコールを Adabas Review ハブに発行しますが、パフォーマンスを落とさないために、ハブの処理の完了やハブからの応答を待機しません。これは、ADARVU からハブに渡される Review データが常に正しいことを前提にしているからです。
ただし、ADARVU は初期化ステップを実行して、Adabas ニュークリアスによるコマンド処理に先立ってハブが必ずアクティブであるようにします。 ハブがアクティブではない場合、ADARVU は、WTO またはユーザー出口、またはその両方を使用してユーザーに通知します。 ユーザー出口が使用されている場合、ハブがアクティブになるまで待機することも可能です。または、初期化を続行して、ハブがアクティブであるときのみ、ハブをコールすることもできます。
コールのハブ側では、クロスメモリポストコールが除外されるため、Adabas クライアントとのアクティブなコミュニケーションのオーバーヘッドが削減され、パフォーマンスが向上します。 これにより、ハブは受動的なデータ収集機能の状態を保ちます。
次の図は、 クライアント/サーバーアーキテクチャにおける Adabas Review インターフェイスの主なコンポーネント(Adabas ニュークリアスアドレススペース)、および Adabas Review ハブ(Adabas Review ハブアドレススペース)を示しています。
Adabas SQL Gateway は、CONNX のサブセットです。独特のクライアント/サーバー接続プログラムツールセットであり、コンピュータを使って、リアルタイムでインタラクティブに多くのデータベースを操作できるようになります。 CONNX データアクセスエンジンは、データベースへのアクセスを提供するだけではなく、複数のデータベースを企業全体にわたるリレーショナルデータソースとして表現するという点で独特です。 CONNX は、ODBC SQL Level 2 との互換性、強化されたセキュリティ、メタデータ管理、強化された SQL 機能、ビュー、異種データベース間の結合、双方向のデータ変換の各機能を提供し、データの読み込み/書き込みアクセスを可能にします。 このようなテクノロジは、データウェアハウス、データの統合、アプリケーションの統合、電子商取引、データの移行に使用され、また、レポートの目的でも使用されます。 このテクノロジは、異なる種類のデータソースを使用している企業内でも利用されています。このような企業では、Web 上でのデータの利用を必要としているか、古いアプリケーションでミッションクリティカルな情報を格納しています。
CONNX には次のコンポーネントが含まれます。
CONNX Data Dictionary(CDD)
CONNX ODBC Driver
CONNX OLE RPC Server(CONNX および VSAM には実装されない)
CONNX Host Data Server(RMS、VSAM[CICS/C++ TCP/IP リスナ/サーバーとして実装]、C-ISAM、Rdb、および DBMS)
CONNX JDBC Driver(シンクライアント)
CONNX JDBC Server
CONNX JDBC Router
多くの種類のデータベースに加え、CONNX は、IBM z/OS、Windows 2000/XP/2003、AIX、Solaris、Linux、HP-UX などのプラットフォーム上で動作する Adabas をサポートします。
Adabas SQL Gateway の詳細については、Adabas SQL Gateway のドキュメントを参照してください。
Software AG は、標準データベース問い合わせ言語の SQL に ANSI/ISO 規格を実装して、Adabas SQL Server を実現しました。 Adabas SQL Server には、Adabas への SQL インターフェイスや、および SQL ステートメントをダイナミックに実行したり、カタログから情報を取得するインタラクティブ機能が装備されています。
このサーバーは、組み込み済みのスタティックおよびダイナミックな SQL、およびインタラクティブな SQL や SQL2 拡張をサポートします。 複雑な Adabas データ構造が、標準 SQL で処理が可能な一連の 2 次元データビューに自動的に正規化されます。
Adabas SQL Server は、次のステートメントを実行して Adabas データにアクセスし、データを操作します。
Natural アプリケーションプログラムに組み込まれたステートメント。
第 3 世代ホスト言語の C、COBOL、または PL/I に組み込まれたステートメント。
直接的でインタラクティブなインターフェイスを使用したステートメント。
現在、Adabas SQL Server には、C、COBOL、PL/I に組み込まれた SQL ステートメント用のプリコンパイラが装備されています。 プリコンパイラは、プログラムソースをスキャンして、SQL ステートメントをホスト言語ステートメントに置き換えます。 Adabas SQL Server のモジュラー設計により、どのホスト言語を選択しても、機能が変わることはありません。
標準の SQL で搭載されていない特定の拡張機能を使用すると Adabas の機能を最大限に利用できるので、アプリケーションプログラムのコンパイル時には、ANSI 互換モード、DB2 互換モード、または Adabas SQL Server モードの 3 つの SQL モードから 1 つを選択する必要があります。
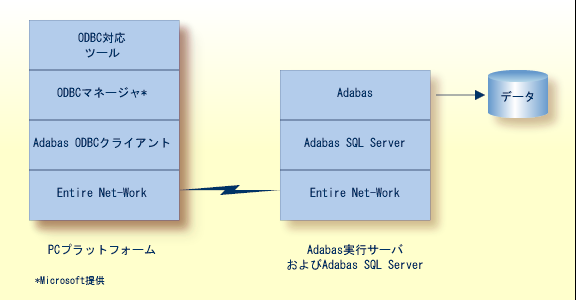
リモートおよびローカルのクライアントは、Entire Net-Work をクライアント/サーバー要求の転送プロトコルとして使用して、サーバーと通信します。 Adabas ODBC Client を使用すると、ODBC ドライバにより、ODBC 互換のデスクトップツールを使用した Adabas SQL Server へのアクセスが可能になります。 同じく ODBC 互換の Entire Access には、SQL 対応の共通のアプリケーションプログラミングインターフェイス(API)が装備されています。この API は、Adabas SQL Server のクライアント/サーバーソリューションに相当する、ローカルおよびリモートのデータベースへのアクセスに使用されます。
Adabas SQL Server は、Adabas 自身が利用可能な大部分のハードウェアおよびオペレーティングシステム環境で使用できます。 Adabas SQL Server の主要な機能は、プラットフォームが異なっても同一になります。
詳細は、Adabas SQL Server のドキュメントを参照してください。
データベース管理者(DBA)は、定期的にデータベースの状態(ディスクおよびメモリの利用率など)をチェックして、現状の傾向に基づいて、今後のディスクスペース要件をどのように確保するのかなどの長期計画を立てます。
Adabas に対して、DBA は ADAREP(データベースレポート)ユーティリティ、ニュークリアスエンドセッションプロトコル、および Adabas Online System を使用して作成されたアドホック問い合わせを使用して、個別のデータベースおよびファイルのチェックが可能です。 通常、このチェックには長時間の処理を必要とします。
Adabas Statistics Facility(ASF)は、次のプログラムよって構成される自動化環境を提供します。
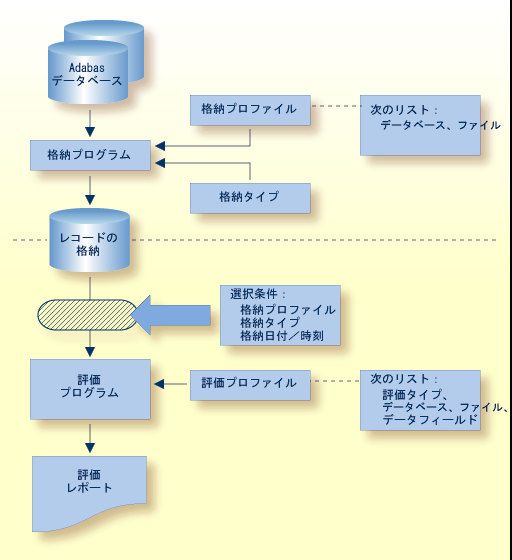
アクティブなニュークリアスセッション中にデータベースステータス情報を収集する格納プログラム。 このプログラムは通常、数週間または数ヵ月の長期間にわたって定期的な間隔(例えば 1 日に 1 回)で実行するようにスケジュールされ、統計的な評価が可能なデータを収集します。 格納プログラムは、ASF オンラインメニューシステム内のコマンドを使用して、DBA によりアドホックベースで開始できます。
格納プログラムにより収集された統計情報を解釈し、概要評価レポートを画面またはハードコピープリンタに出力する評価プログラム。 レポートは、Entire Connection を使用して PC にダウンロードすることも可能です。
データベース情報は、ニュークリアスセッションの開始時、終了時、および途中に収集できます。 数週間または数ヵ月にわたり蓄積されるニュークリアスの開始および終了データにより、長期的なデータベース規模の推移を知ることができ、将来のデータベース要件を予測することが可能です。 メインメモリやプールの使用率などのニュークリアスのパフォーマンスデータにより、DBA は Adabas ニュークリアスのパラメータを分析および調節できます。
詳細は、Adabas Statistics Facility のドキュメントを参照してください。
ASF は、格納プログラムと呼ばれるデータ収集プログラムを使用して、アクティブなニュークリアスセッションの開始時、終了時、および途中でデータベースステータス情報を収集します。 このプログラムは通常、数週間または数ヵ月の長期間にわたって定期的な間隔(1 日に 1 回など)でバッチプログラムとして実行するようにスケジュールされ、統計的に評価が可能なデータを収集します。 格納プログラムは、ASF 内のコマンドを使用して、DBA によりアドホックベースで開始できます。 オンラインメニューシステム
DBA は、それぞれ監視するデータベースおよびファイルのセットごとに異なる格納プロファイルを定義します。各プロファイルは、格納プログラムの実行時に入力として指定されます。 異なる格納プロファイルを持つ複数の格納プロファイルを同時に実行できます。
Adabas データベースおよびファイルの監視には、条件によりコールされる約 170 個のデータフィールドが使用されます。 データフィールドは、ディスクおよびバッファの使用率、スレッドの使用率、データベース負荷、ADARUN パラメータ、プールの使用率、および特定の Adabas コマンドの使用頻度などの Adabas データベースの状態を表します。 すべてのデータフィールドは、格納プロファイルで指定された各データベースおよびファイルに対して格納されます。
数週間または数ヵ月にわたり蓄積されるニュークリアスの開始および終了データにより、長期的なデータベース規模の推移を知ることができ、将来のデータベース要件を予測することが可能です。 メインメモリの使用率やプール使用率などのニュークリアスパフォーマンスデータは、Adabas ニュークリアスのパラメータを調節する際の参考になります。
ASF は、評価プログラムと呼ばれる一連のプログラムを使用して、格納プログラムにより収集された統計を評価し、評価レポートと呼ばれるサマリレポートを作成します。評価レポートは、オンラインでの表示、出力、および PC へのダウンロードが可能です。
各評価レポートに対して、DBA はオンラインメニューシステムを使用して、次の項目を指定する評価プロファイルを定義します。
データを評価するデータベースおよびファイル(これらに対するデータは格納プログラムで収集されます)
指定されたデータベースおよびファイルに対して、レポートの分析対象となる 1 つ以上のデータフィールド
指定されたデータフィールドの計測単位
指定されたデータフィールドのクリティカルレベルを表す、上限および下限値
レポートの見出しのフォーマットを決定する、レポートタイプ(01~10 の 1 つ)
主なレポートタイプは次のとおりです。
全般的な評価:過去および現在のデータベースステータスの分析 生成される統計テーブルは、さまざまなデータベースおよびファイルのステータスの概要を提供します。 出力テーブルの各列で、最大値および最小値が表示されます。また、値の合計や平均値などの統計量も表示されます。
クリティカルレポート:指定されたデータフィールドが指定されたクリティカル限界値に達したか限界値を超えたデータベースおよびファイルのレポートです。
クリティカルトレンドレポート:一定の期間内に、指定されたデータフィールドがクリティカル限界値に達するか限界値を超えることが予想されるデータベースおよびファイルのレポートです。予測は現在のトレンドに基づいています。
Adabas Text Retrieval は、フォーマット付き、およびフォーマットなし(テキスト)データの両方に同時にアクセスするアプリケーションの開発を可能にする Adabas の拡張機能です。 Adabas Text Retrieval は、インデックス情報を管理しますが、データの内容は管理しないため、ドキュメントの内容は、Adabas、シーケンシャルファイル、CD-ROM、PC など、どこにでも格納できます。Adabas Text Retrieval のコールインターフェイスは、Software AG の第 4 世代アプリケーション開発環境 Natural、または COBOL や PL/I などのすべての第 3 世代言語内に組み込むことができます。
ドキュメントは、Adabas Text Retrieval により管理されるフォーマットなしテキスト、または Adabas 自身により管理されるフォーマット付きフィールドとして指定された章で構成されます。 フォーマットなしの章は、パラグラフおよび文章で構成されていて、個別に検索することが可能です。
入力されたテキストの文字列の一部分は、Adabas Text Retrieval 文字テーブルで定義された文字と照合することにより、認識またはトークン化されます。この認識またはトークン化には、文字列の文脈に基づく文字認識アルゴリズムが使用されるか、以前に認識された文字をソートまたは制限する変換テーブルが使用されます。
ドキュメントのインデックスエントリは、フォーマットなしのデータがインバートされるときに作成されます。 テキスト全体をインバートできますが、インバートは、制御されているシソーラス、または禁止ワードリスト上の語句を無視することにより制限することもできます。
検索は、語句、語句の一部(左右または中の省略が可能)、発音、同義語、統合シソーラス関係(下位語/上位語)、近接演算子(語順指定近接、語順不同近接、文内、パラグラフ内)、関係演算子、ブール演算子、以前の問い合わせの参照(絞り込み)、またはソート(昇順または降順)を基準に実行できます。 検索処理は構造には依存しません。つまり、フォーマットなしテキストとフォーマット付きフィールドのどのような組み合わせも検索可能です。 検索結果を強調表示させることができます。
Natural のユーザーは、完全なドキュメント管理サービスを提供する Natural Document Management を使用して Adabas Text Retrieval の機能を拡張することができます。
Adabas Transaction Manager は、Adabas に分散トランザクションのサポートを導入します。 トランザクションは、1 つ以上のオペレーティングシステム(Entire Net-Work で接続)上の複数の Adabas データベースに分散させることが可能です。 トランザクションは、DB2、IMS などの Adabas 以外の DBMS にも分散させることができます。 トランザクションが Adabas 以外の DBMS に分散されている場合、Adabas Transaction Manager は、IBM の CICS Syncpoint Manager や IBM の Recoverable Resource Management Services などの、他のトランザクション調整ツールと相互運用するように構成する必要があります。 Adabas Transaction Manager はいつでも実行中のトランザクション、状態が不明なトランザクション、参加中のデータベースなどを明らかにできます。
Adabas Transaction Manager(ATM)は、次の役割を担う Adabas のアドオン製品です。
グローバルトランザクションに参加している Adabas データベースへの変更を調整する。
トランザクションマネージャからの 2 フェーズコミット指示を処理する(最初のリリースではこの機能は利用できません)。このトランザクションマネージャは、IBM の RRMS や CICS Syncpoint Manager などのグローバルトランザクションの調整処理を上位レベルで制御し、単一のオペレーティングシステムイメージで、トランザクションがデータベース(Adabas と Adabas 以外のものを含む)を包括的に処理できるようにします。
1 つ以上のシステムイメージ上の Adabas データベースを変更するグローバルトランザクションの調整における主要な役割を担う。 この役割とは、Entire Net-Work 内の複数のシステムイメージのコンポーネント間のコミュニケーションを行うことです。
各 Adabas Transaction Manager インスタンス(オペレーティングシステムイメージごとに 1 つ)は、特別な Adabas ニュークリアスとして、そのアドレススペース内で実行します。 各 Adabas Transaction Manager は、分散システム内および調整対象データベース内の他の ATM を認識しており、連携して動作しています。 Adabas Transaction Manager は、いつでも調整しているグローバルトランザクションのステータスを明らかにできます。
Adabas Transaction Manager は、企業目標に対するな基本的な 2 つのニーズに対応します。
主幹のクリティカルなビジネスシステム内で、幅広い商業用途向けの業務に耐える強固な企業目標を実現するニーズ
大量のデータを複数のコンピュータおよび組織全体に分散させて、Adabas ユーザーがより均等に管理できるようにするニーズ
Adabas Transaction Manager には、Natural に基いた、Adabas Online System から利用できるオンライン管理システムが含まれます。
詳細については、Adabas Transaction Manager のドキュメントを参照してください。
Adabas Vista により、ビジネスアプリケーションを再構築することなく、データを個別に管理されるファイルに分割できます。物理データモデルが分割されて、幅広く多くのコンピュータに分散されても、ビジネスアプリケーションは引き続き 1 つの(単純な)Adabas ファイルエンティティを参照します。
データは、複数の Adabas データベースサービスにわたって分割できます。 大容量のファイルが複数のデータベースに分割された場合、処理負荷は、実質的に各コンピュータサービスに分散されます。 コンピュータに複数の CPU エンジンが搭載されている場合、CPU エンジンの並行処理機能をより一層活用できます。
Adabas Vista パーティションは、完全に独立した Adabas ファイルです。
複数のパーティションを同一にする必要はありません。 すべてのパーティションが、Adabas Vista で使用されるすべてのビューをサポートしている場合、異なる複数の物理レイアウト(FDT)を持つファイルを操作できます。 もちろん、すべてのパーティションに共通な Adabas ソースフィールドは、各 FDT で同一に定義する必要があります。
パーティションは個別にメンテナンスできます。 パーティションは、必要に応じて個別にサイズの変更、整理、およびリストアが可能です。 すべてのパーティションを、同一の物理的な制約上で操作する必要はありません。 例えば、一部の選択したパーティションを大きくして、他のパーティションを中サイズにすることができます。また、パーティションに応じて ASSO スペースを調節することも可能です。
Adabas Vista がすべてのパーティションに対して単一ファイルイメージを提供するアプリケーションを選択できます。 また、アプリケーションを混合アクセスモードに設定して、プログラムが単一ファイルイメージを使用していても、実際のファイル番号を使用して直接パーティションにアクセスできるようにすることも可能です。
ファイルは通常、場所や日付などの全体的な情報となるキーフィールド(分割条件)に基づいて、分割されます。 ただし、分割条件を使用しないでファイルを分割することも可能です。
アプリケーションは通常、いくつかのキーフィールドに基づいた検索データを使用してファイルにアクセスします。 Adabas Vista は、明示的あるいは黙示的に、アクセスが分割条件に基づいていることを検出し、検索引数を検証して、特定の必要なパーティションにアクセスを限定することにより、処理オーバーヘッドを最小化します。 これは、集中アクセスと呼ばれます。
Adabas Vista のパーティション停止対応機能により、パーティションが使用不能になった場合の対処方法を制御できます。 パーティションの停止を検知するように設定でき、ビジネスアプリケーションは、ユーザーに基づいて停止したパーティションを無視することができます。 例えば、分割条件が場所であり、特定の場所のデータのみがその場所のユーザーにとって重要な場合、ユーザー自身の場所でパーティションを停止すると、ユーザーは操作が中断され、他の場所ではパーティションが停止しても操作を続行できるように、パーティション停止を設定できます。 これにより、データに対する全体的な可用性が大幅に向上し、ビジネスの効率を飛躍的に強化することができます。
Adabas Vista パーティション制限機能により、パーティションを意識せずにデータを利用できます。 この機能を使用して、安全上またはパフォーマンス上の理由から、役割、場所またはその他の業務上の定義に応じて特定のユーザーのみにデータの使用を制限することが可能です。
Adabas Vista の統合機能により、単一のファイルイメージを、以前は無関係だった複数のファイルと強制的に関連付けることができます。 このファイルは、個別のファイルのままですが、統一されたビューをサポートします。
Adabas Vista は、サポートされるバージョンの Adabas とともに、IBM メインフレーム環境(z/OS、z/VM、VSE)で使用できます。
Adabas Vista は、第 3 世代言語プログラムおよび Natural からの Adabas コールをサポートします。 Natural 環境では、オンラインサービスオプションを使用できます。
Adabas Vista は、スタブ(クライアント)部分とサーバー部分で構成されています。 大部分の処理は、次の目的のためにサーバーではなくクライアント処理内で行われます
CPU 使用率の最小化
データベースサービス上でのパーティション化に関連するオーバーヘッドの影響の最小化
できる限り多くの並行処理 CPU エンジンまたは複数のコンピュータへの負荷の分散
詳細については、Adabas Vista のドキュメントを参照してください。
Event Replicator for Adabas は、Software AG の製品ファミリで構成されています。 基本的な製品は、Adabas データベース内のデータの変更の監視、および別のアプリケーションへの変更済みデータのレプリケートを行うために使用されます。 詳細は、次のトピックを参照してください。
Event Replicator for Adabas の詳細については、Event Replicator for Adabas のドキュメントを参照してください。
Software AG の Event Replicator for Adabas は、特定の Adabas ファイルに対してデータの変更状況を監視することができます。 監視対象ファイルの 1 つが変更(削除、格納、または更新)された場合は、Event Replicator は常に変更されたすべてのレコードを抽出して、メッセージングシステム(EntireX Communicator または IBM MQSeries など)を介して 1 つ以上のターゲットアプリケーションに渡します。 レプリケートされる一連のファイルは、1 つ以上のサブスクリプション内で定義されます。
注意:
このドキュメントで使用されている MQSeries という用語は、WebSphere MQ
という製品と同じものを指します。
Event Replicator は、通常の Adabas の処理に与える影響を最小限に抑えながら、Adabas データの変更をターゲットアプリケーションに渡すことが必要な組織には欠かすことができないツールです。 Event Replicator には、次の基本的な機能が含まれます。
ほぼリアルタイムのレプリケーション
非同期レプリケーション
渡されるデータの整合性および順序を保証
コミットされた更新のみのレプリケーション
Event Replicator を使用すると、1 つ以上のサブスクリプション内の定義に従って、Adabas ファイル全体または特定のレコードのセットを目的の場所にレプリケートできます。 データのレプリケーションは非同期で行われるため、Adabas データベースは、レプリケーションの実行中も通常に動作できます。 事前定義されたレプリケート対象ファイルの、コミットされた Adabas の変更点のみがトランザクションレベルでレプリケートされます。
Event Replicator for Adabas の詳細については、Event Replicator for Adabas のドキュメントを参照してください。
Event Replicator Target Adapter は、レプリケートされたデータを変換し、リレーショナルデータベース(Oracle、DB2、Microsoft SQL Server、MySQL、Sybase など)に適用するために使用します。
Event Replicator Target Adapter は、次のものを使用する必要があります。
グローバルフォーマットバッファフィールドテーブルが生成されている Event Replicator for Adabas サブスクリプション。 フィールドテーブルが生成されていない場合、Event Replicator Target Adapter は動作しません。
"SAGTARG "クラスタイプが指定されている、少なくとも 1 つの Event Replicator for Adabas 宛先定義。 この宛先は、サブスクリプションにより使用されなければなりません。
この要件を満たして、サブスクリプション定義および 1 つ以上の関連する宛先定義が作成されていて、これらがアクティブな場合、Event Replicator for Adabas は、レプリケートされたデータをマッピングするスキーマを自動的に作成します。 Event Replicator Target Adapter は、スキーマを使用してレプリケートされたデータを変換し、リレーショナルデータベースに適用します。 Event Replicator Target Adapter は、テーブルが存在しない場合は、ダイナミックにテーブルを作成して、挿入、更新および削除処理を使用して、Adabas データが含まれたテーブルをデータベースに追加します。これらの処理は、Adabas ファイルがレプリケートされたときに、ほぼリアルタイムで行われます。
Event Replicator for Adabas および Event Replicator Target Adapter の高レベルな処理を次の図に示します。
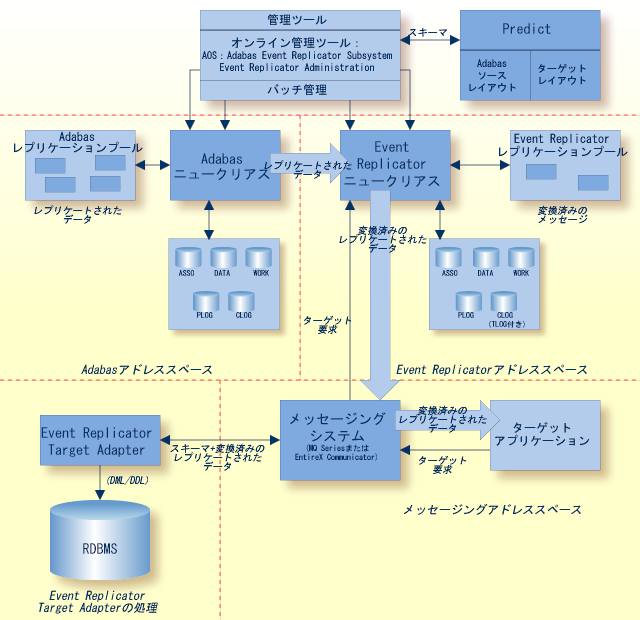
適切な Event Replicator サブスクリプションおよび宛先定義がアクティブになり、Event Replicator Target Adapter が起動すると、Event Replicator Target Adapter の通常の処理により、サブスクリプションに従ってデータが処理され、レプリケートされたデータが変換されてリレーショナルデータベースに適用されます。 また、手動で次の要求を Event Replicator Target Adapter に送ることができます。
リレーショナルデータベーステーブルを追加するための初期状態要求の開始
リレーショナルデータベーステーブル内のデータのクリア
リレーショナルデータベーステーブルおよびそのデータの削除
Event Replicator Target Adapter の詳細については、Event Replicator for Adabas のドキュメントを参照してください。
Event Replicator Administration は、Web ベースのグラフィカルユーザーインターフェイス(GUI)です。Event Replicator の管理タスクを実行する際に使用します。 この GUI は、Software AG の製品を集中的に管理する System Management Hub(SMH)と通信する標準の Web ブラウザを使用します。 SMH はユーザーセッションを処理して、ユーザーとブラウザの相互作用を、Event Replicator 管理タスクを実装した Event Replicator 用に作成された特定のエージェントへの要求に変換します。 次に、SMH はエージェントの応答を HTML ページとしてブラウザに転送します。
注意:
System Management Hub を実行しているブラウザのウィンドウを閉じるか、別の URL に移動すると、Event Replicator Administration
とのセッションが終了します。
System Management Hub の Event Replicator Administration エリアには、次の 2 種類の管理が含まれています。
Adabas データベース管理
Event Replicator データベース管理
これらの管理エリアを使用して、Event Replicator for Adabas が使用している Adabas および Event Replicator データベースを管理できます。
| エリア | 説明 |
|---|---|
| Adabas データベース | このエリアを使用して、Event Replicator for Adabas が使用する Adabas データベースの登録および登録解除を行います。 |
| Replicator | このエリアを使用して Event Replicator for Adabas が使用する、Event Replicator データベースの登録および登録解除を行います。また、各 Event Replicator データベースに関連付けられた Replicator システムファイル内のレプリケーション定義のメンテナンスを行います。 |
Event Replicator Administration の詳細については、Event Replicator for Adabas のドキュメントを参照してください。
Event Replicator Administration を使用してレプリケーション定義を保守する場合、いくつかの Software AG のミドルウェアコンポーネントのインストールが必要です。 Entire Net-Work Client または Entire Net-Work のバージョン 7.2 以降のクライアント側へのインストールが推奨されます。 Event Replicator Administration は、Entire Net-Work 5.9(このバージョンの Entire Net-Work TCP/IP Option のシンプル接続ラインドライバが含まれます)の機能限定版である Entire Net-Work Administration、および Entire Net-Work Client に付属しています。
上記の Entire Net-Work 製品を使用する場合、Event Replicator Administration を使用して保守を行う Event Replicator Server および Adabas データベースは、UES が有効でなければなりません。 Event Replicator Administration と Event Replicator Server および Adabas データベース間のコミュニケーションを確立する方法として、Windows 版の Entire Net-Work 2.6 および Entire Net-Work を使用する方法があります。 5.8.1.
Event Replicator Administration および Event Replicator 要件の詳細については、Event Replicator for Adabas のドキュメントを参照してください。
Software AG のマルチシステム処理ツールである Entire Net-Work により、ネットワーク全体にわたる範囲において Adabas およびその他のサービスタスクとの通信が可能になり、分散処理のメリットを受けられます。 この柔軟性により、次の操作が可能になります。
ネットワークが構成されたシステム上で、データベースの場所に左右されずに Adabas データベースアプリケーションを実行する
さまざまなネットワークノード上に存在するコンポーネントを使用して、分散された Adabas データベースを操作する
特定のタイプのタスクの実行に最も適切なネットワークノード上で、他のネットワークシステムからこれらのサービスへのアクセスを制限しないで、そのタスクを実行する
Entire System Server(旧バージョンの Natural Process)にアクセスして、リモートシステムでオペレーティングシステム依存の機能を実行する
クライアント/サーバーアプリケーションを実装するために、Entire Broker にアクセスする
Mainframe Entire Net-Work は、BS2000、z/OS、VSE、z/VM および富士通の MSP をサポートします。 この Entire Net-Work は、オペレーティングシステムおよびハードウェアアーキテクチャが異なっている可能性がある、異なる物理または仮想マシン上で実行しているクライアントとサーバープログラム間の透過的な接続を提供します。
Entire Net-Work は、ミッドレンジプラットフォームの OpenVMS、UNIX および AS/400、およびワークステーションプラットフォームの OS/2、Windows、および Windows NT でも使用できます。
最も低いレベルでは、Entire Net-Work はリモートシステム上のターゲットまたサーバーに向けられたメッセージを受け取り、適切な送信先に届けます。 これらの要求に対する応答は、要求の発行元のクライアントアプリケーションに返されます。その際、アプリケーションへの変更は不要です。
操作方法、およびサーバーの場所や操作上の特徴は、ユーザーおよびクライアントアプリケーションに対して完全に透過的です。 サーバーおよびアプリケーションは、Entire Net-Work がインストールされ、通信可能なシステム内の任意のノードに配置できます。 ネットワークターゲットおよびサーバーのユーザービューは、ユーザーのローカルノード上にある場合と同様に表示されます。 遠隔処理の遅延により、一部のトランザクションのタイミングが変わる可能性がある点に注意してください。
Entire Net-Work は、アプリケーションをプラットフォーム特有の構文要件から解放し、ユーザーが潜在的なネットワークの特性に制限されることを防ぎます。 また、(回線ダウン時)ダイナミックな再構築および再ルーティング機能を備え、ネットワークパスの最適化に寄与し、またネットワークレベルの統計情報を生成します。
Entire Net-Work は、クライアント/サーバー機能を必要とする関連ホストまたはワークステーションシステムにインストールされています。 1 つのシステムは、Entire Net-Work コントロールモジュール、コントロールモジュールサービスルーチン、および必要なすべてのラインドライバで構成されています。 Entire Net-Work がインストールされたシステムは、ネットワークのノードとなります。 各ノードから近接する他ノードへのリンクは、名前およびドライバのタイプによって決まります。
各 Entire Net-Work ノードには、受信要求用の要求キューが存在します。 このキューは、Adabas で使用するコマンドキューと類似しています。このキューにより、ノードはローカルで実行中のユーザー/クライアントプログラムからの Adabas コールを受信できるようになります。Adabas コールは Entire Net-Work によりキューが解除され、要求されたサービスが存在するノードに転送されます。
Entire Net-Work の各ローカルノードは、すべてのアクティブなネットワークサービスの情報を常に得ています。したがって、ユーザーの要求を実行できるか、または拒否すべきかを判断できます。 要求が実行可能な場合はメッセージが転送されます。実行が不可能な場合は、Entire Net-Work はコール元のユーザーに直ちに通知します。これは、Adabas ルーターがローカルのデータベース要求に対して行う処理と同等です。
実際のネットワークデータトラフィックは、Entire Net-Work ラインドライバにより制御されます。このラインドライバは、VTAM、IUCV、DCAM、XCF、および TCP/IP などのサポートされるコミュニケーションアクセスメソッドへのインターフェイス、またはチャネル間アダプタ(CTCA)などのハードウェアデバイスへの直接的なインターフェイスとなります。 各 Entire Net-Work ノードには、そのノードでアクティブなアクセスメソッドに必要なラインドライバのみが含まれます。 さらに、各ラインドライバは、他のノードへの複数の接続をサポートします。このラインドライバのモジュラー設計により、新しいアクセスメソッドをシステムへ簡単に追加できます。
Entire Net-Work XTI インターフェイスにより、ユーザーは独自のクライアント/サーバーアプリケーションの作成が可能になります。アプリケーションは、主に Adabas の構造の影響を受けない C で記述します。 XTI は、移植性に優れたアプリケーションを作成するための、国際的に認められた仕様です。 理論上では、XTI 仕様に準拠して作成されたアプリケーションは、XTI 実装をサポートしている他のどのようなプラットフォームへも簡単に移植が可能です。
Entire Net-Work XTI の実装は、同一のコンピュータ内および異なるコンピュータで実行しているプログラム間のコミュニケーションをサポートします。 Entire Net-Work は、アプリケーションプログラマからは、転送プロバイダとして見えます。
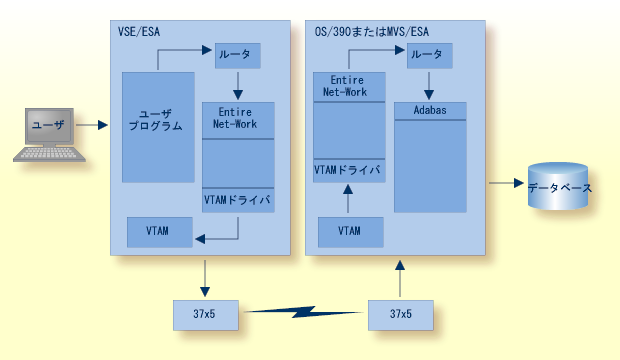
詳細については、Entire Net-Work のドキュメントを参照してください。
Entire Transaction Propagator(ETP)により、Adabas ユーザーは単一データベースまたは分散ネットワーク内のデータベースファイルを複製、またはレプリケートできるようになります。 コピーは、ネットワーク全体にわたって分散させることができ、各ユーザーの場所から迅速で効率的にファイルにアクセスできるようになります。
分散データベースの概念は、操作の効率および柔軟性を提供しながら、同時にほぼ無制限のデータ容量を実現できます。 このようなネットワーク化されたデータベース構造は、特定の部署が必要とするデータベースデータの一部分をローカルシステム上に配置し、同時に共通データベースリソースとして企業全体で利用できることを意味します。
分散データベースに特性は、データを最も必要とする場所に、そのデータの複製を配置できる点にあります。 このような特性があるために、コピーされた複数のデータファイルを、データベースネットワーク全体に配置できますが、ユーザーからはこのコピーは論理的に 1 つのファイルとして見えます。
通常は、レプリケートされたファイルは、変更が発生するごとに、すべてのファイルコピーにおけるデータの保全性を確保するための複雑な制御処理を必要とします。 書き込みトランザクションより読み込みトランザクションの比率が高い分散システムでは、このような厳密な制御を必要としない場合があります。 ETP では、ファイルのレプリケーションに厳密性の低い制御プロセスが採用されていますが、実質的には、ファイルのレプリケーションによる長所をすべてを実現しています。 マスタ/レプリケートの制御システムを使用して、ETP はすべてのレプリケートコピーをユーザー指定の間隔でマスターコピーと再同期します。
Software AG の先進の第 4 世代アプリケーション開発環境である Natural、および分析や設計、コード生成、およびリポジトリ機能を有する Software AG の主要なアプリケーション開発用製品ファミリを使用することで、Adabas の利用レベルが向上します。
Natural から Adabas への直接アクセス、または Entire Access コールを使用した Adabas SQL Server 経由のアクセスが可能です。
FDT では Adabas ファイル内の物理レコードを定義するのに対し、Natural プログラムでは、ファイルにアクセスするときの物理ファイルの論理ビューを定義し使用します。 ビューは、データ定義モジュールとユーザービューの 2 つのレベルを持つことができます。
データ定義モジュール(DDM)は、Adabas FDT と非常に似ている Natural モジュールです。 DDM は、一連のフィールドおよびその属性(タイプ、フォーマット、長さなど)で構成され、レポートフォーマット、編集マスクなどの追加的な仕様を含めることができます。
DDM には、FDT に定義したフィールドすべて、またはそのフィールドのサブセットを含めることができます。 各 Adabas ファイルには、少なくとも 1 つの DDM が必要です。 例えば、Employees という Adabas ファイルには、Employees という DDM が必要です。 Natural ステートメントの READ EMPLOYEES BY NAME は、実際には物理ファイルではなく DDM です。DDM は、Natural ステートメントを Adabas ファイルにリンクします。
1 つの Adabas ファイルに、複数の DDM を定義できます。 複数の DDM を定義することで、ファイル内のフィールドへのアクセスを制限できます。 例えば、役職者が使用するプログラム用の DDM には、制限情報を持つフィールドを含めて、一般ユーザーが使用するプログラム用の DDM にはこれらのフィールドを含めないようにできます。 ワークステーショングループでは、データベース管理者はグループ用の標準 DDM セットを定義できます。
既存の Natural DDM から、新しい Adabas FDT を作成できます。 逆に、FDT が作成または変更されると、Adabas は DDM を自動的に生成または上書きすることができます。
注意:
Adabas ファイルからフィールドを削除する場合は、そのフィールドを参照する Natural
プログラムから該当フィールドを削除する必要があります。
Natural のユーザービューには通常、DDM 内のフィールドのサブセットが含まれます。 ユーザービューは、Data Area Editor 内、またはプログラムまたはルーチン内で定義できます。 ユーザービューが DDM を参照するとき、フォーマットと長さは DDM で定義されてるため、新たに定義する必要はありません。 DDM またユーザービューでは、FDT 内のフィールドとは異なる順序でフィールドを定義できます。
Adabas のアクセスはフィールドを基本にしています。Natural プログラムは必要なフィールドのみにアクセスしたり、必要なフィールドのみを取得します。 Natural ステートメントからは、自動的に Adabas 検索や取得操作を呼び出すことができます。
Adabas では、さまざまな順次アクセスメソッドとランダムアクセスメソッドがサポートされます。 Natural ステートメントごとに、別々の Adabas アクセスパスおよびコンポーネントを使用します。最も効率的な方法は、必要とする情報の種類および取得が必要なレコード数によって異なります。
詳細については、Natural のドキュメントを参照してください。
Predict(Adabas データディクショナリシステム)により、データディクショナリの設定と更新ができます。 データディクショナリは、標準の Adabas ファイル内に格納されるため、Natural から直接アクセスできます。
データディクショナリには、データの定義、構造、使用法についての情報が含まれます。 実際のデータ自身ではなく、データまたはメタデータに関する情報が格納されています。 ディクショナリは、データの定義をすべて含む情報の格納場所であり、データ属性、特性、データ源、使用法および他のデータとの相互関係を含んでいます。 ディクショナリは、データをより有用にするための情報を収集します。
データディクショナリにより、DBA は組織のデータリソースのより高度な管理や制御が可能になります。 より高度なデータディクショナリのユーザーは、プロジェクト管理やシステム設計においてこれが有効なツールであることを認めています。
オンラインモードでもバッチモードでも、ディクショナリに対してデータベースに関する情報を格納できます。 Adabas ディクショナリ内のデータの記述には、ファイル、各ファイルに定義されたフィールド、ファイル間の関係に関する情報が含まれます。 使用法に関する記述には、そのデータを使用するシステム、プログラム、モジュールおよびレポートに関する情報の他、データの所有者と使用するユーザーに関する情報が含まれます。 ディクショナリエントリは、次のような情報から成ります。
ネットワーク構造
Adabas データベース
ファイル、フィールド、および相互の関係
所有者と使用者
システム、プログラム、モジュールおよびレポート
フィールド整合性チェック(処理ルール)
標準のデータディクショナリレポートは、次の情報を出力できます。
データディクショナリの全内容
フィールド情報、ファイル情報、相互の関連情報
ファイルごとのフィールド情報
詳細については、Predict のドキュメントを参照してください。