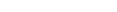
This chapter describes the procedures used to link application programs, and to call Adabas to execute an Adabas command.
There are two kinds of Adabas direct calls, one for each of the different control block interfaces supported by Adabas:
The ACB direct call interface is the classic direct call interface, used for Adabas releases prior to Adabas Version 6.1. Direct calls in this format require the use of the classic Adabas control block (ACB). If you have been using releases of Adabas prior to Adabas Version 6.1, the direct calls used by your applications use the ACB direct call interface.
The ACBX direct call interface is the extended direct call interface, used for Adabas releases starting with Adabas Version 6.1. Direct calls in this format require the use of the extended Adabas control block (ACBX). If you have purchased and installed Adabas Version 6.1 (or later), you can use this format of direct call in your applications. Otherwise, you cannot.
Adabas Version 6.1 (and subsequent versions) fully supports both the ACB and the ACBX direct call interfaces:
Existing application programs that use the ACB direct call interface can continue to run in the same way, without change.
In addition, you can decide whether you want to use the ACBX-based or ACB-based direct call interface in your application programs, on a call-by-call basis. The same program can use both interfaces.
The control block and the related buffers specify which Adabas command is to be executed and provide any additional information (parameters or operands) required for the command. The pointer to the appropriate control block (ACB or ACBX) must always be the first operand specified in an Adabas call.
This document covers the following topics:
All application programs have to be linked to an Adabas interface. The following interfaces are available:
| Interface name | Name of the shared library on UNIX | Name of the DLL on Windows |
|---|---|---|
| adalnkx | libadalnkx.s[ol] | adalnkx.dll |
| adalnk | libadalnk.s[ol] | adalnk32.dll |
| adalnknc | libadalnknc.s[ol] | adalnknc.dll |
The following table shows when to use which interface:
| adalnkx | adalnk | adalnknc | |
|---|---|---|---|
| Multi-thread applications | x | ||
| Single-thread applications | x | x | x |
| Net-work 2 support | x | x | |
| Net-work 7 support | x | x | |
| XA support | x | x | x |
| ACB direct call interface | x | x | x |
| ACBX direct call interface | x |
Notes:
There are various ways of linking the application to the Adabas interface:
- Dynamic Link
The application is linked with the required shared library for the Adabas interface. LD_LIBRARY_PATH must contain $ACLDIR/lib so that the shared library can be found at runtime.
If you have set the environment as suggested in the Adabas installation, the library path contains $ACLDIR/lib, where the shared library can be found at runtime.
- Loading via stub
The application is linked with the Adabas stub object adabasx.o (for loading adalnkx) or adabas.o (for loading adalnk) in the directory $ACLDIR/lib. Then at runtime the $ADALNK environment variable has to point to the shared library to be used. When linking with the stub adabasx.o, the environment variable $ADALNKX has to point to the shared library libadalnkx.so. LD_LIBRARY_PATH must contain $ACLDIR/lib because the Adabas interface calls other shared libraries from this directory.
- Loading via dlopen
You can also load the Adabas interface via dlopen. It is not necessary to specify the full path in the dlopen call if you have set the environment as suggested in the Adabas installation; then the library path contains $ACLDIR/lib where the Adabas interface is stored.
Note:
The Adabas interface may only be loaded once. Closing the Adabas interface with dlclose and reloading it can cause errors.
Note:
If you want to use an Adabas interface when an application has
the S-bit set, the installation root directory must be /opt/softwareag. Then
/opt/softwareag/AdabasClient/lib contains the current Adabas interfaces, which
can be used to load the Adabas interfaces from applications with S-bits.
Important:
adalnk/adalnkx contain a signal handler
which, for example, displays a stack backtrace after a signal SIGUSR1. This
signal handler can be deactivated by setting the environment variable
SMP_SIGNAL_HANDLING to 0. This is necessary if your application has its own
signal handling, because otherwise signals might no longer be processed as
expected by the application's signal handler because of conflicts with the
adalnk/adalnkx signal handler. For example, Natural uses this signal for
printing. If you use the environment variable settings provided by the Adabas
installation, they already include the setting of SMP_SIGNAL_HANDLING to
0.
Unlike Adabas Version 3, where a different interface (adalnk32) was provided for linking 32 bit-mode applications on 64 bit UNIX platforms, starting with Adabas Version 5.1, Adabas provides the same interfaces as described above in a 32 bit-mode version in a separate directory. Starting with Adabas Version 6.1, the interfaces for the 32 bit-mode can be found in $ACLDIR/$ACLVERS/lib_32.
Note:
While the installation provides the setting of the environment
variable $LD_LIBRARY_PATH for the 64 bit-mode, it does not for the 32
bit-mode.Users running Adabas applications in 32 bit-mode on 64-bit platforms
must take care to ensure that they set the $LD_LIBRARY_PATH correctly before
they start the applications.
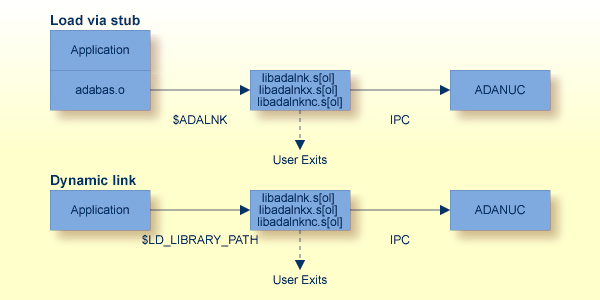
Link with adankx.lib, adalnk32.lib or adalnknc.lib. This way, at runtime, the corresponding DLL is dynamically linked from %PATH%. If you haven't modified %PATH% since installing Adabas, the DLLs are loaded from %ACLDIR% (32-bit mode) or %ACL64DIR% (64-bit mode).
Notes:
For further information, such as compile and link options, see the example makefile under%ACLDIR%\..\examples\client and the sample C code in the same directory.
It is also possible to use LoadLibrary or LoadLibraryEx to load the Adabas interface. It is recommended not to specify the full path for the DLL, since the folder where the correct Adabas interface is stored depends on the installed Adabas versions and the Windows operating system and the mode (32 or 64 bit); the Adabas installation sets the PATH in such a way, that the correct Adabas interface is found.
Note:
The Adabas interface may only be loaded once. Freeing the
Adabas interface with FreeLibrary or FreeLibraryAndExitThread and reloading it
may cause errors.
When making a direct call using the ACB interface, syntax such as the following should be used (this is a COBOL example):
CALL 'ADABAS' USING acb-control-block-name
[format-buffer]
[record-buffer]
[search-buffer]
[value-buffer]
[ISN-buffer]
In an ACB direct call, Adabas expects buffers to be specified in the order shown in this syntax. If no buffers are required for a call, no buffers need be specified. However, if a given call does not require a format buffer, but does require one of the other buffers (for example, a record buffer), a dummy (or blank) format buffer must be specified prior to the record buffer. Likewise, if a call requires only an ISN buffer, dummy format, record, search, and value buffers must be supplied as well.
The following table describes each of the italicized, replaceable items in this syntax. For more information about the format of the ACB control block and Adabas buffers, read Adabas Control Block (ACB) and Defining Buffers. For information about the relationships between different ABD types, read Understanding the Different Buffer Types.
| Replace | With |
|---|---|
| acb-control-block-name | The pointer to the Adabas Control Block (ACB) to use for the call. |
| format-buffer | The name of or pointer to the format buffer to use for the call. Only one format buffer can be specified in a single ACB direct call. |
| ISN-buffer | The name of or pointer to the ISN buffer to use for the call. Only one ISN buffer can be specified in a single ACB direct call. |
| record-buffer | The name of or pointer to the record buffer to use for the call. Only one record buffer can be specified in a single ACB direct call. |
| search-buffer | The name of or pointer to the search buffer to use for the call. Only one search buffer can be specified in a single ACB direct call. |
| value-buffer | The name of or pointer to the value buffer to use for the call. Only one value buffer can be specified in a single ACB direct call. |
The way direct calls are made in your applications when using the new ACBX interface is different than when using the classic ACB interface. In addition, the calls are different for mainframe applications and open systems applications. This section covers the following topics:
The way direct calls are made in your applications when using the new ACBX interface is different than when using the classic ACB interface. When making a direct call using the ACBX interface in open system applications, syntax such as the following should be used (this is a C example):
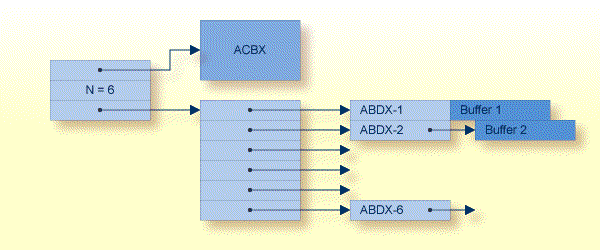
adabasx(ACBX_pointer, ABD-count, ABD-list-pointer)
Each ABD either directly precedes its associated buffer or contains a pointer to the buffer. It effectively represents the buffer.
ABDs can be specified in any sequence in an ACBX interface direct call. However, if an ABD requires a matching ABD of another type, Adabas will match them sequentially. For example, if three format buffer ABDs and three record buffer ABDs are included in the call, the first format buffer ABD in the call is matched with the first record buffer ABD in the call, the second format buffer ABD is matched with the second record buffer ABD, and the third format buffer ABD is matched with third record buffer ABD.
If unequal numbers of match-requiring ABDs are specified, Adabas will generate a dummy ABD (with a buffer length of zero) for the missing ABD. For example, if three format buffer ABDs are specified, but only two record buffer ABDs are specified, a dummy record buffer ABD is created for use with the third format buffer ABD. If you would prefer that the dummy record buffer ABD be used for the second format buffer ABD instead, you must specify the dummy record buffer ABD yourself prior to the record buffer ABD to be used by the third format buffer ABD.
For commands where data in the record buffer is not described by a format specification in the format buffer, no format buffer segments need be specified; if any are specified, they are ignored. This applies to only a few commands; the most prominent of them is OP.
The following table describes each of the italicized, replaceable items in this syntax. For more information about the format of the extended Adabas control block (ACBX), Adabas buffer descriptions (ABDs), and Adabas buffers, read Extended Adabas Control Block (ACBX), Adabas Buffer Descriptions (ABDs), and Defining Buffers. For information about the relationships between different buffer types, read Understanding the Different Buffer Types.
| Parameter | Description |
|---|---|
| ACBX_pointer | The pointer to the extended Adabas control block (ACBX) to use for the call. |
| ABD-count | The number of the ABD pointers included in the ABD list for the direct call. |
| ABD-list-pointer | The pointer to the ABD list for the direct call. The ABD list contains pointer references for all of the ABDs used by the ACBX direct call. For more information about the ABD list, read ABD Lists. |
These adabasx parameters are shown in the following graphic:
Important:
The ACBX and the ABDs must be initialized before the first
Adabas call by using the calls SETACBX(ACBX_pointer) and SETABD(ABD_pointer)
respectively.
The way direct calls are made in your applications when using the new ACBX interface is different than when using the classic ACB interface. When making a direct call using the ACBX interface in mainframe applications, syntax such as the following should be used (this is a COBOL example):
CALL 'ADABAS' USING acbx-control-block-name
reserved-fullword
reentrancy-token
[format-buffer-ABD record-buffer-ABD [multifetch-buffer-ABD]]...
[search-buffer-ABD]
[value-buffer-ABD]
[ISN-buffer-ABD]
[performance-buffer-ABD]
[user-buffer-ABD]
Each ABD either directly precedes its associated buffer or contains a pointer to the buffer. It effectively represents the buffer.
ABDs can be specified in any sequence in an ACBX interface direct call. However, if an ABD requires a matching ABD of another type, Adabas will match them sequentially. For example, if three format buffer ABDs and three record buffer ABDs are included in the call, the first format buffer ABD in the call is matched with the first record buffer ABD in the call, the second format buffer ABD is matched with the second record buffer ABD, and the third format buffer ABD is matched with third record buffer ABD.
If unequal numbers of match-requiring ABDs are specified, Adabas will generate a dummy ABD (with a buffer length of zero) for the missing ABD. For example, if three format buffer ABDs are specified, but only two record buffer ABDs are specified, a dummy record buffer ABD is created for use with the third format buffer ABD. If you would prefer that the dummy record buffer ABD be used for the second format buffer ABD instead, you must specify the dummy record buffer ABD yourself prior to the record buffer ABD to be used by the third format buffer ABD.
For commands where data in the record buffer is not described by a format specification in the format buffer, no format buffer segments need be specified; if any are specified, they are ignored. This applies to only a few commands; the most prominent of them is OP.
The following table describes each of the italicized, replaceable items in this syntax. For more information about the format of the extended Adabas control block (ACBX), Adabas buffer descriptions (ABDs), and Adabas buffers, read Extended Adabas Control Block (ACBX), Adabas Buffer Descriptions (ABDs), and Defining Buffers. For information about the relationships between different buffer types, read Understanding the Different Buffer Types.
| Replace | With |
|---|---|
| acbx-control-block-name | The pointer to the extended Adabas control block (ACBX) to use for the call. |
| format-buffer-ABD | The name of or pointer to the format buffer ABD that defines a format buffer segment to use for the call. Each format buffer segment must end with a period and be a complete and valid standalone format buffer. Multiple format buffer ABDs can be specified in a single ACBX direct call. |
| ISN-buffer-ABD | The name of or pointer to the ISN buffer ABD that defines an ISN buffer segment to use for the call. Only one ISN buffer ABD can be specified in a single ACBX direct call. |
| multifetch-buffer-ABD | The name of or pointer to the multifetch buffer ABD that defines a multifetch buffer segment to use for the call. Multiple multifetch buffer ABDs can be specified in a single ACBX direct call. Currently not supported by Adabas on open systems. |
| performance-buffer-ABD | The name of or pointer to the performance buffer ABD that defines a performance buffer segment. Currently not supported by Adabas on open systems. |
| record-buffer-ABD | The name of or pointer to the record buffer ABD that defines a record buffer segment to use for the call. Multiple record buffer ABDs can be specified in a single ACBX direct call. |
| reentrancy-token | The ADALNK reentrancy token. This is a fullword in the calling program's storage where ADALNK stores the address of its static data area. This fullword should be set to zero before the first Adabas call. It should then remain unchanged for all subsequent direct calls while the program runs. |
| reserved-fullword | The fullword containing binary zeros. This fullword is reserved for use by Adabas and should be set to binary zeros before the first Adabas call. |
| search-buffer-ABD | The name of or pointer to the search buffer ABD that defines a search buffer segment to use for the call. Only one search buffer ABD can be specified in a single ACBX direct call. |
| user-buffer-ABD | The name of or pointer to the user buffer ABD that defines a user buffer segment (extension) to use for the call. A single user buffer ABD can be specified in an ACBX direct call. |
| value-buffer-ABD | The name of or pointer to the value buffer ABD that defines a value buffer segment to use for the call. Only one value buffer ABD can be specified in a single ACBX direct call. |
Any application program can make both ACB and ACBX direct calls. The control block (ACB or ACBX) is the first parameter in Adabas calls using either the ACB or ACBX interfaces. Adabas determines which control block is used for a call by the presence of a value starting with the letter "F" at offset 2 of the control block. Offset 2 in the ACB is the command code field (ACBCMD), but since there is no valid F* Adabas command, no valid direct call using the ACB will contain a value starting with the letter "F" at offset 2. Offset 2 in the ACBX is a new version field (ACBXVER) identifying the new ACBX.
The presence or absence of an "F" at offset 2 determines how Adabas interprets the direct call. If an "F" is specified in offset 2, Adabas interprets the control block and remaining direct call parameters as an ACBX call; if an "F" is not specified in offset 2, Adabas interprets the control block and remaining direct call parameters as an ACB call. If, for some reason, the remaining control block fields and direct call parameters are not specified correctly for the type of call indicated by the presence or absence of an "F" at offset 2 (for example, if ACB parameters are specified for an ACBX call), errors may result or the results of the call may not be as expected.
You can freely mix ACB and ACBX direct calls in the same application.
Two kinds of control blocks are now supported by Adabas:
The Adabas control block (ACB) is the classic control block, used for Adabas releases prior to Adabas Version 6.1. If you have been using releases of Adabas prior to Adabas Version 6.1, the direct calls used by your applications use the ACB. It is important to note that Adabas Version 6.1 (and later) fully supports the ACB, so you are not required to update your existing applications once you install Adabas Version 6.1 (or later).
The extended Adabas control block (ACBX) can be used in Adabas releases starting with Adabas Version 6.1. The ACBX supports the increased buffer sizes and segmented buffers introduced in Adabas 6.1. If you have purchased and installed Adabas Version 6.1 (or later), you can use the ACBX in direct calls from your applications. Otherwise, you cannot.
To ensure user program compatibility with later Adabas releases, all control block fields not used by a particular command should be set to zeros or blanks, depending on field type.
The position of each field in a control block is fixed. In addition, all values in the control block must be entered in the data type defined for the field. For example, the ISN field is defined as binary format; therefore, any entry made in this field must be in binary format.
Notes:
This section covers the following topics:
The Adabas control block (ACB) is 80 bytes long. This section covers the following topics:
The following table describes the format of the ACB. We recommend that you set unused ACB fields to binary zeros before the direct call is initiated.
| Name | Field | Control Block Position | Offset | Length (in Bytes) | Format |
|---|---|---|---|---|---|
| ACBTYPE | Call Type | 1 | 00 | 1 | binary |
| reserved | (reserved) | 2 | 01 | 1 | binary |
| ACBCMD | Command Code | 3-4 | 02 | 2 | alphanumeric |
| ACBCID | Command ID | 5-8 | 04 | 4 | binary |
| ACBFNR | File Number | 9-10 | 08 | 2 | binary |
| ACBRSP | Response Code | 11-12 | 0A | 2 | binary |
| ACBISN | ISN | 13-16 | 0C | 4 | binary |
| ACBISL | ISN Lower Limit | 17-20 | 10 | 4 | binary |
| ACBISQ | ISN Quantity | 21-24 | 14 | 4 | binary |
| ACBFBL | Format Buffer Length | 25-26 | 18 | 2 | binary |
| ACBRBL | Record Buffer Length | 27-28 | 1A | 2 | binary |
| ACBSBL | Search Buffer Length | 29-30 | 1C | 2 | binary |
| ACBVBL | Value Buffer Length | 31-32 | 1E | 2 | binary |
| ACBIBL | ISN Buffer Length | 33-34 | 20 | 2 | binary |
| ACBCOP1 | Command Option 1 | 35 | 22 | 1 | alphanumeric |
| ACBCOP2 | Command Option 2 | 36 | 23 | 1 | alphanumeric |
| ACBADD1 | Additions 1 | 37-44 | 24 | 8 | alphanumeric / binary |
| ACBADD2 | Additions 2 | 45-48 | 2C | 4 | alphanumeric / binary |
| ACBADD3 | Additions 3 | 49-56 | 30 | 8 | alphanumeric |
| ACBADD4 | Additions 4 | 57-64 | 38 | 8 | alphanumeric |
| ACBADD5 | Additions 5 | 65-72 | 40 | 8 | alphanumeric / binary |
| ACBCMDT | Command Time | 73-76 | 48 | 4 | binary |
| ACBUSER | User Area | 77-80 | 4C | 4 | not applicable |
The content of the control block fields and buffers must be set before an Adabas command (call) is issued. Adabas also returns one or more values or codes in certain fields and buffers after each command is executed.
We recommend that you set unused ACB fields to binary zeros before the direct call is initiated.
Each of the fields in the ACB is described in this section, in the order they appear in the ACB format. The descriptions are valid for most Adabas commands; however, some Adabas commands use some control block fields for purposes other than those described here. For complete information about how these fields are used by each Adabas command, read Commands.
The first byte of the Adabas control block (ADACB) is used by the Adabas API to determine the processing to be performed.
The values for logical requests are:
| Hex | Indicates ... |
|---|---|
| 00 | a 1-byte file number (file numbers between 1 and 255) or DBID. |
| 30 | a 2-byte file number (file numbers between 1 and 65535) or DBID. |
All other values in the first byte of the ADACB are reserved for use by Software AG.
Because an application can reset the value in the first byte of the ADACB on each call, it is possible to mix both one- and two-byte file number (DBID) requests in a single application. In this case, you must ensure the proper construction of the file number (ACBFNR) and response code (ACBRSP) fields in the ADACB for each call type. See the discussions of these fields for more information.
Software AG recommends that an application written to use two-byte file numbers always places hex 30 in the first byte of the ADACB, the logical database ID in the ACBRSP field, and the file number in the ACBFNR field. The application can then treat both the database ID and file number as 2-byte binary integers, regardless of the value for the file number in use.
Applications written in Software AG's Natural language need not include this first byte of the Adabas ACB because Natural supplies appropriate values.
The command code defines the command to be executed, and comprises two alphanumeric characters (for example, OP, A1, BT).
The command ID field is used by many Adabas commands to identify logical read sequences, search results, and (optionally) decoded format buffers for use by subsequent commands. You can specify alphanumeric or binary command IDs as you choose or you can request the generation of new binary command IDs by Adabas. See the section Using Command IDs for more information about command IDs. For ET, CL, and some OP commands, Adabas returns a binary transaction sequence number in the command ID field.
Note:
Internally, the command ID field is treated as binary, even
though alphanumeric values are often stored in this field. For cross-platform
calls this means that there is no EBCDIC - ASCII conversion, and that the bytes
are swapped if the integer arithmetic is different on the client and nucleus
platforms. However, for those users who specify alphanumeric values, a 4 byte
blank value is also considered to be an empty command ID, like a binary 0
value. This is valid for both ASCII and EBCDIC blanks; in the following, both
ASCII blanks (0x20202020) and EBCDIC blanks (0x40404040) are considered as
blank ID values.
The file number may be one or two bytes.
For an application program issuing Adabas commands for file numbers between 1 and 255 (single byte), build the control block as follows:
| Position | Action |
|---|---|
| 1 | Place hex 00 in the first byte of the ADACB. |
| 9 | Place the file number in the low-order byte of the ACBFNR field of the ADACB. The high-order byte of the ACBFNR field is used to store the logical (database) ID or number. |
Adabas permits the use of file numbers greater than 255 on logical requests. For an application program issuing Adabas commands for file numbers between 256 and 5000 (two-byte), build the control block as follows:
| Position | Action |
|---|---|
| 1 | Place hex 30 in the first byte of the ADACB. |
| 9 | Use both bytes in ACBFNR for the file number, and use the two bytes in ACBRSP for the database (logical) ID. |
The response code field is used for two-byte database IDs.
It is also always set to a value when the Adabas command is completed. Successful completion is normally indicated by a response code of zero. For repeatable commands that process sequences of records or ISNs, other response codes indicate end-of-file or end-of-ISN-list. Non-zero response codes are defined in the Adabas Messages and Codes.
The ISN field both specifies a required four-byte Adabas ISN value required by the command and, where appropriate, returns either the first ISN of a command-generated ISN list, or an ISN of the record read by the command.
ISN lower limit specifies the starting point in an ISN list or range where processing is to begin. For OP commands, an optional user-specific non-activity timeout value can be specified in this field. An OP command also returns Adabas release information in this field (see also the Additions 5 field description).
The ISN quantity is a count of ISNs returned by a command. The count can be a total of all ISNs in an ISN list, or the total ISNs entered into the ISN buffer from a larger pool of ISNs by this operation. The OP command uses this field to specify an optional user-specific transaction time limit; it returns system and call type information flags in the ISN quantity field (see also the Additions 5 field description).
The format, record, search, value, and ISN buffer length fields specify the size of the related buffers. A buffer's size usually remains the same throughout a transaction. In some ISN-related operations, the ISN buffer size value determines how a command processes ISNs; for example, specifying a zero ISN buffer length causes some commands to store a resulting ISN list in the Adabas work area. If a buffer is not needed for an Adabas command, the corresponding length value should be set to zero. In some cases (multifetch option, as an example), there is a limit on the length of the buffer; see the specific command descriptions for more information.
The Command Option 1 and 2 fields allow you to specify processing options (ISN hold, command-level prefetching control, returning of ISNs, and so on).
The Additions 1 field sometimes requires miscellaneous command-related parameters such as qualifying descriptors for creating ISN lists.
The Additions 2 field returns compressed record length in the last two bytes and decompressed length of record buffer-selected fields in the first two bytes for all An, Ln, Nn, and S1/2/4 commands. OP (open) and RE (read ET data) commands return transaction sequence numbers in this field. If Entire Net-work is installed, some response codes return the node ID of the "problem" node in the last two bytes of the Additions 2 field.
If a command results in a nucleus response code, the addition 2 field's first two bytes (47 and 48) can contain a hexadecimal subcode to identify the cause of the response code. Response codes and their subcodes (as decimal equivalents) are described in the Adabas Messages and Codes.
The Additions 3 field is for providing a user`s password for accessing password-protected files. If the file containing the field is actually password-protected, the password in this field is replaced with spaces (blanks) during command execution before Adabas returns control to the user program.
On Mainframes, the Additions 4 field must be set to the cipher code of a file, if a command reads or writes records of an encrypted (ciphered) Adabas file. On UNIX and Windows platforms this field is not used.
Instead of using the command ID as a format buffer ID, Additions 5 can be used to store the format buffer ID for a command separately. Please refer to the section "Using Format Buffer IDs" for further information.
The command time field is used by Adabas to return the elapsed time that was needed by the nucleus to process the command. In contrast to the mainframe, where this field is always filled by Adabas, it is only filled on open systems platforms if Command Logging is switched on or if the nucleus is started with the environment variable ADA_CMD_TIME set (the value is irrelevant).
The user area field is reserved for use by the user program. When making logical user calls, the user area is neither written nor read by Adabas.
For compatibility with future Adabas releases, Software AG recommends that you set unused control block fields to null values corresponding to the field's data type.
The extended Adabas control block, the ACBX, supports the increase in the buffer sizes in Adabas commands. It is 192 bytes in length (versus the 80 bytes used by the ACB). The existing, non-extended Adabas Control Block (ACB) is still supported and your existing applications will still work, but if you want to take advantage of some of the extended features provided in Adabas Version 6.1 (or later), you must use the new ACBX. Specifically, you must use the ACBX if you are using the long buffer (buffers longer than 32K) or segmented buffer (multiple format/record buffer pairs or format/record/multifetch buffer triplets) features introduced with Adabas Version 6.1.
Otherwise, your application programs may freely switch between Adabas calls using the existing direct call interface (ACB) and calls using the new interface (ACBX).
The following table describes the format of the ACBX. We recommend that you set unused ACBX fields to binary zeros before the direct call is initiated.
| Name | Field | Control Block Position | Offset | Length (in bytes) | Format |
|---|---|---|---|---|---|
| ACBXTYP | Call Type | 1 | 00 | 1 | binary |
| ACBXRSV1 | Reserved 1 | 2 | 01 | 1 | binary |
| ACBXVER | Version Indicator | 3-4 | 02 | 2 | binary |
| ACBXLEN | ACBX Length | 5-6 | 04 | 2 | binary |
| ACBXCMD | Command Code | 7-8 | 06 | 2 | alphanumeric |
| ACBXRSV2 | Reserved 2 | 9-10 | 08 | 2 | binary |
| ACBXRSP | Response Code | 11-12 | 0A | 2 | binary |
| ACBXCID | Command ID | 13-16 | 0C | 4 | binary |
| ACBXDBID | Database ID | 17-20 | 10 | 4 | numeric |
| ACBXFNR | File Number | 21-24 | 14 | 4 | numeric |
| ACBXISN | ISN | 25-32 | 18 | 8 | binary |
| ACBXISL | ISN Lower Limit | 33-40 | 20 | 8 | binary |
| ACBXISQ | ISN Quantity | 41-48 | 28 | 8 | binary |
| ACBXCOP1 | Command Option 1 | 49 | 30 | 1 | alphanumeric |
| ACBXCOP2 | Command Option 2 | 50 | 31 | 1 | alphanumeric |
| ACBXCOP3 | Command Option 3 | 51 | 32 | 1 | alphanumeric |
| ACBXCOP4 | Command Option 4 | 52 | 33 | 1 | alphanumeric |
| ACBXCOP5 | Command Option 5 | 53 | 34 | 1 | alphanumeric |
| ACBXCOP6 | Command Option 6 | 54 | 35 | 1 | alphanumeric |
| ACBXCOP7 | Command Option 7 | 55 | 36 | 1 | alphanumeric |
| ACBXCOP8 | Command Option 8 | 56 | 37 | 1 | alphanumeric |
| ACBXADD1 | Additions 1 | 57-64 | 38 | 8 | alphanumeric/ binary |
| ACBXADD2 | Additions 2 | 65-68 | 40 | 4 | binary |
| ACBXADD3 | Additions 3 | 69-76 | 44 | 8 | alphanumeric/ binary |
| ACBXADD4 | Additions 4 | 77-84 | 4C | 8 | alphanumeric |
| ACBXADD5 | Additions 5 | 85-92 | 54 | 8 | alphanumeric/ binary |
| ACBXADD6 | Additions 6 | 93-100 | 5C | 8 | alphanumeric/ binary |
| ACBXRSV3 | Reserved 3 | 101-104 | 64 | 4 | binary |
| ACBXERRA | Error Offset in Buffer | 105-112 | 68 | 8 | binary |
| ACBXERRB | Error Character Field | 113-114 | 70 | 2 | alphanumeric |
| ACBXERRC | Error Subcode | 115-116 | 72 | 2 | binary |
| ACBXERRD | Error Buffer ID | 117 | 74 | 1 | alphanumeric |
| ACBXERRE | Reserved | 118 | 75 | 1 | binary |
| ACBXERRF | Error Buffer Sequence Number | 119-120 | 76 | 2 | binary |
| ACBXSUBR | Subcomponent Response Code | 121-122 | 78 | 2 | binary |
| ACBXSUBS | Subcomponent Response Subcode | 123-124 | 7A | 2 | binary |
| ACBXSUBT | Subcomponent Error Text | 125-128 | 7C | 4 | alphanumeric |
| ACBXLCMP | Compressed Record Length | 129-136 | 80 | 8 | binary |
| ACBXLDEC | Decompressed Record Length | 137-144 | 88 | 8 | binary |
| ACBXCMDT | Command Time | 145-152 | 90 | 8 | binary |
| ACBXUSER | User Area | 153-168 | 98 | 16 | not applicable |
| ACBXRSV4 | Reserved 4 | 169-193 | A8 | 24 | do not touch |
The content of the control block fields and buffers must be set before an Adabas command (call) is issued. Adabas also returns one or more values or codes in certain fields and buffers after each command is executed.
We recommend that you set unused ACBX fields to binary zeros before the direct call is initiated.
Each of the fields in the ACBX is described in this section, in the order they appear in the ACBX format. The descriptions are valid for most Adabas commands; however, some Adabas commands use some control block fields for purposes other than those described here.
The first byte of the Adabas control block (ADACBX) is used by the Adabas API to determine the processing to be performed.
When issuing an Adabas command, set this field to binary zeros. This indicates that a logical user call is being made (ACBXUSER equate).
Applications written in Software AG's Natural language need not include this first byte of the Adabas ACBX because Natural supplies appropriate values.
This field is reserved. Set this field to zero.
The version indicator identifies whether the Adabas control block uses the new ACBX or the classic ACB format. If this field is set to a value starting with the letter "F" (for example "F2"), Adabas treats the Adabas control block as though it is specified in the ACBX format. If this field is set to any other value, Adabas treats the control block as though it is specified in the classic ACB format.
The ACBX length field should be set to the length of the ACBX structure passed to Adabas (the ACBXQLL equate, currently 192).
The command code defines the command to be executed, and comprises two alphanumeric characters (for example, OP, A1, BT).
This field is reserved. Set this field to zero.
This field gets set to a value when the Adabas command is completed. Successful completion is normally indicated by a response code of zero. For repeatable commands that process sequences of records or ISNs, other response codes indicate end-of-file or end-of-ISN-list. Non-zero response codes are defined in the Adabas Messages and Codes documentation.
The command ID field is used by many Adabas commands to identify logical read sequences, search results, and (optionally) decoded format buffers for use by subsequent commands. You can specify alphanumeric or binary command IDs as you choose or you can request the generation of new binary command IDs by Adabas. See the section Using Command IDs for more information about command IDs. For ET, CL and some OP commands, Adabas returns a binary transaction sequence number in the command ID field.
Note:
Internally, the command ID field is treated as binary, even
though alphanumeric values are often stored in this field. For cross-platform
calls this means that there is no EBCDIC - ASCII conversion, and that the bytes
are swapped if the integer arithmetic is different on the client and nucleus
platforms. However, for those users who specify alphanumeric values, a 4 byte
blank value is also considered to be an empty command ID, like a binary 0
value. This is valid for both ASCII and EBCDIC blanks; in the following, both
ASCII blanks (0x20202020) and EBCDIC blanks (0x40404040) are considered as
blank ID values.
Use this field to specify the database ID. The Adabas call will be directed to this database.
This field is a four-byte binary field, but at this time only two-byte database IDs are supported. Therefore, the database ID should be specified in the low-order part of the field, with leading binary zeros.
Use this field to specify the number of the file to which the Adabas call should be directed.
This field is a four-byte binary field, but the file number should be specified in the low-order part of the field, with leading binary zeros.
The ISN field specifies any required Adabas ISN value required by the command and, where appropriate, returns either the ISN of the record read by the command , or the first ISN of an ISN list generated by the command.
The ACBXISN field is an eight-byte field, which is not yet used, but only 4-byte values are allowed. The high-order part of the ACBXISN field must contain binary zeros.
The ISN Lower Limit field specifies the starting point in an ISN list or range where processing is to begin.
For OP commands, an optional user-specific non-activity timeout value can be specified in this field. The OP command also returns Adabas release information in this field.
The ACBXISL field is an eight-byte field, which is not yet used, but only 4-byte values are allowed. The high-order part of the ACBXISL field must contain binary zeros.
The ISN Quantity field is the count of ISNs returned by a search (Sx) command. The count can be a total of all ISNs in an ISN list, or the total ISNs entered into the ISN buffer segment from a larger pool of ISNs by this operation.
For an OP command, an optional user-specific transaction time limit may be specified in this field. The OP command returns system and call type information in this field.
The ACBXISQ field is an eight-byte field, which is not yet used, but only 4-byte values are allowed. The high-order part of the ACBXISQ field must contain binary zeros.
The Command Option 1 - 8 fields allow you to specify processing options (ISN hold, command-level prefetching control, returning of ISNs, and so on). In Adabas Version 6.1, only the Command Option 1 and Command Option 2 field are supported. However, the other Command Option fields are provided for potential expansion in future Adabas releases.
The Additions 1 field sometimes requires miscellaneous command-related parameters such as qualifying descriptors for creating ISN lists, or the second file number of a coupled file pair.
OP (open) and RE (read ET data) commands return transaction sequence numbers in this field.
The other values for Additions 2, as described under Additions 2 in the ACB, are also provided, but the ACBX contains other fields for these values; it is recommended that you use the new fields if you want to access these values with the ACBX interface.
The Additions 3 field is for providing a user's password for accessing password-protected files. This field is always reset to blanks during command execution.
On Mainframes, the Additions 4 field must be set to the cipher code of a file, if a command reads or writes records of an encrypted (ciphered) Adabas file. On UNIX and Windows platforms this field is not used.
Instead of using the command ID as a format buffer ID, Additions 5 can be used to store the format buffer ID for a command separately. Please refer to the section "Using Format Buffer IDs" for further information.
This field is not used at this time. It must be set to binary zeros.
This field is reserved. This field must be set to binary zeros.
The Error Offset in Buffer specifies the offset in the buffer, if any, where the error is detected during the direct call.
The ACBXERRx fields are only set when a response code is returned from a direct call. The ACBXERRA, ACBXERRD, and ACBXERRE fields are only set when the response code is related to buffer processing.
This field identifies the two-byte Adabas short name of the field, if any, that was being processed when the error was detected.
The ACBXERRx fields are only set when a response code is returned from a direct call.
This field stores the subcode of the error that occurred during direct call processing.
The ACBXERRx fields are only set when a response code is returned from a direct call. If Entire Net-work is installed, some response codes return the node ID of the problem node in this field.
This field contains the ID (from the ABDID field) of the buffer referred to by the ACBXERRA field, so that the buffer causing the error can be identified, when multiple buffers are involved.
The ACBXERRx fields are only set when a response code is returned from a direct call. The ACBXERRA, ACBXERRD, and ACBXERRE fields are only set when the response code is related to buffer processing.
This field contains the sequence number of the buffer referred to by the ACBXERRA and ACBXERRD fields.
The ACBXERRx fields are only set when a response code is returned from a direct call. The ACBXERRA, ACBXERRD, and ACBXERRE fields are only set when the response code is related to buffer processing.
This field contains the response code from any error that occurred when an Adabas add-on product intercepts the Adabas command.
This field contains the response subcode from any error that occurred when an Adabas add-on product intercepts the Adabas command.
This field contains the error text of any error that occurred when an Adabas add-on product intercepts the Adabas command.
This field returns the compressed record length when a record was read or written.
This is the length of the compressed data processed by the successful Adabas call. If the logical data storage record spans multiple physical data records, the combined length of all associated physical records may not be known. In this case, Adabas returns high values in the low-order word of this field.
This field returns the decompressed record length. This is the length of the decompressed data processed by the successful call. If multiple record buffer segments are specified, this reflects the total length across all buffer segments.
The command time field is used by Adabas to return the elapsed time that was needed by the nucleus to process the command. In contrast to the mainframe, where this field is always filled by Adabas, it is only filled on open systems platforms if Command Logging is switched on or if the nucleus is started with the environment variable ADA_CMD_TIME set (the value is irrelevant).
The user area field is reserved for use by the user program. When making logical user calls, the user area is neither written nor read by Adabas.
This field is reserved for use by Adabas. Your user program should set this field to binary zeros before the first Adabas call using this ACBX and then leave it unmodified thereafter.
The ACBX differs in many ways from the ACB. The ACBX includes some fields that are not included in the ACB and the sizes of some ACBX fields are larger than their ACB equivalents. These expansions in the ACBX have been made to ensure that its structure can be flexible enough to handle potential future enhancements to Adabas, without altering its fundamental structure for many years.
This section describes the differences between the ACB and the ACBX:
The ACBX is 192 bytes in length; the ACB is 80 bytes long.
The buffer length fields are not included in the ACBX as they are in the ACB. When using the ACBX direct call interface, they are instead provided in the individual Adabas buffer descriptions (ABDs). So the ACBX contains no buffer fields corresponding to the ACBFBL, ACBIBL, ACBRBL, ACBSBL, and ACBVBL found in the ACB; the ABDs associated with the call are used instead. One ABD represents an individual Adabas buffer segment. They are described in Adabas Buffer Descriptions.
The number of command option, additions, and reserved control block fields are larger in the ACBX:
The ACBX contains eight command option fields, up from the two command option fields available in the ACB.
The ACBX contains six additions fields, up from the five additions fields available in the ACB.
The ACBX contains four reserved fields, up from one reserved field available in the ACB.
Reserved ACBX fields must be set to binary zeros; the reserved 4 field (ACBXRSV4) should be initialized to binary zeros and then left unchanged.
The lengths of many control block fields are larger in the ACBX than in the ACB, but note that the value length that is really supported is often smaller than the actual field length - this was done in order to enable larger values in future Adabas versions without having to change the interface. The following table summarizes these changes:
| Field Title | Length | ||
|---|---|---|---|
| ACB | ACBX | ||
| Field | Value | ||
| File Number | 2 (with call type 0x30 in File Number) | 4 | 2 |
| Database ID | 2 (with call type 0x30 in Response Code) | 4 | 2 |
| ISN | 4 | 8 | 4 |
| ISN Lower Limit | 4 | 8 | 4 |
| ISN Quantity | 4 | 8 | 4 |
| Compressed Record Length | 2 (in Additions 2) | 8 | 2 |
| Decompressed Record Length | 2 (in Additions 2) | 8 | 4 |
| Command Time | 4 | 8 | 8 |
| Format Buffer Length | 2 | 8 (in the ABD) | 4 |
| Record Buffer Length | 2 | 8 (in the ABD) | 4 |
| Search Buffer Length | 2 | 8 (in the ABD) | 4 |
| Value Buffer Length | 2 | 8 (in the ABD) | 4 |
The following additional fields are available in the ACBX:
| ACBX Name | Description |
|---|---|
| ACBXADD6 | Additions 6 |
| ACBXCOP3 | Command options 3 |
| ACBXCOP4 | Command options 4 |
| ACBXCOP5 | Command options 5 |
| ACBXCOP6 | Command options 6 |
| ACBXCOP7 | Command options 7 |
| ACBXCOP8 | Command options 8 |
| ACBXDBID | The database ID. In the ACB, the database ID is stored in the response code field (ACBRSP) for hex 30 calls and in the first byte of ACBFNR for other logical calls. |
| ACBXERRA | Error offset into the buffer (32-bit). |
| ACBXERRB | Error character field (field name). |
| ACBXERRC | Error subcode. |
| ACBXERRD | Error buffer ID, if multiple buffers are involved. |
| ACBXERRE | Error buffer sequence number, if multiple buffers are involved. |
| ACBXERRG | Error offset into the buffer (64-bit) - this field is not yet supported. |
| ACBXLCMP | Compressed record length (or portion of record if the entire record is not read). In the ACB, the compressed record length is stored in the Additions 2 field (ACBADD2). |
| ACBXLDEC | Decompressed record length. In the ACB, the decompressed record length is stored in the Additions 2 field (ACBADD2). |
| ACBXLEN | The length of the ACBX, currently 192 |
| ACBXRSV2 | Reserved. The value of this field must be set to zero. |
| ACBXRSV3 | Reserved. The value of this field must be set to zero. |
| ACBXRSV4 | Reserved for use by Adabas. |
| ACBXSUBR | Subcomponent response code, used by Adabas add-on products. |
| ACBXSUBS | Subcomponent response subcode, used by Adabas add-on products. |
| ACBXSUBT | Subcomponent error text, used by Adabas add-on products. |
| ACBXVER | When set to F2, this field indicates to Adabas that the new extended ACB (ACBX) is used. |
There are a number of cases where an ACB field that has multiple purposes has been split out into additional fields in the ACBX:
In the ACB, the Response code field (ACBRSP) is used to store the database ID for hex 30 calls. For the other logical calls the one-byte database ID was stored in the first byte of the file number field, ACBFNR. The ACBX provides a Database ID field (ACBXDBID) for this purpose.
In the ACB, the ACBADD2 field is used to retain error information for certain Adabas response codes. In the ACBX, error information fields (ACBXERR* series) are provided for this purpose.
In the ACB, the ACBADD2 field is used to return, for a successful call, the compressed and decompressed record lengths of the processed data. In the ACBX, for a successful call, the Compressed Record field (ACBXLCMP) contains the length of the compressed data processed by Adabas and the Decompressed Record field (ACBXLDEC) contains the length of the decompressed data.
The offset and sequence of ACBX fields is generally different from the corresponding ACB fields, as depicted in the following table.
| Offset | ACB Field Name | ACBX Field Name |
|---|---|---|
| 00 | ACBTYPE (Call type) | ACBXTYPE (Call type) |
| 01 | reserved | ACBXRSV1 (reserved 1) |
| 02 | ACBCMD (Command code) | ACBXVER (ACBX version indicator) |
| 04 | ACBCID (Command ID) | ACBXLEN (ACBX length) |
| 06 | (ACBCID continued) | ACBXCMD (Command code) |
| 08 | ACBFNR (File number) | ACBXRSV2 (reserved 2) |
| 0A | ACBRSP (Response code -- used for the database ID with X’30’ calls) | ACBXRSP (Response code) |
| 0C | ACBISN (ISN) | ACBXCID (Command ID) |
| 10 | ACBISL (ISN lower limit) | ACBXDBID (Database ID) |
| 14 | ACBISQ (ISN quantity) | ACBXFNR (File number) |
| 18 | ACBFBL (Format buffer length) | ACBXISN (8-Byte ISN) |
| 1A | ACBRBL (Record buffer length) | |
| 1C | ACBSBL (Search buffer length) | |
| 1E | ACBVBL (Value buffer length) | |
| 20 | ACBIBL (ISN buffer length) | ACBXISL (8-Byte ISN Lower Limit) |
| 22 | ACBCOP1 (Command option 1) | |
| 23 | ACBCOP2 (Command option 2) | |
| 24 | ACBADD1 (Additions 1) | |
| 28 | (ACBADD1 continued) | ACBXISQ (8-Byte ISN Quantity) |
| 2C | ACBADD2 (Additions 2) | |
| 30 | ACBADD3 (Additions 3) | ACBXCOP1 (Command option 1) |
| 31 | (ACBADD3 continued) | ACBXCOP2 (Command option 2) |
| 32 | (ACBADD3 continued) | ACBXCOP3 (Command option 3) |
| 33 | (ACBADD3 continued) | ACBXCOP4 (Command option 4) |
| 34 | (ACBADD3 continued) | ACBXCOP5 (Command option 5) |
| 35 | (ACBADD3 continued) | ACBXCOP6 (Command option 6) |
| 36 | (ACBADD3 continued) | ACBXCOP7 (Command option 7) |
| 37 | (ACBADD3 continued) | ACBXCOP8 (Command option 8) |
| 38 | ACBADD4 (Additions 4) | ACBXADD1 (Additions 1) |
| 40 | ACBADD5 (Additions 5) | ACBXADD2 (Additions 2) |
| 44 | (ACBADD5 continued) | ACBXADD3 (Additions 3) |
| 48 | ACBCMDT (Command time) | (ACBXADD3 continued) |
| 4C | ACBUSER (User area) | ACBXADD4 (Additions 4) |
| 54 | --- | ACBXADD5 (Additions 5) |
| 5C | --- | ACBXADD6 (Additions 6) |
| 64 | --- | ACBXRSV3 (reserved 3) |
| 68 | --- | ACBXERRG (Error offset in buffer, 64-bit -- this is not yet supported). |
| 6C | --- | ACBXERRA (Error offset in buffer, 32-bit) |
| 70 | --- | ACBXERRB (Error character field) |
| 72 | --- | ACBXERRC (Error subcode) |
| 74 | --- | ACBXERRD (Error buffer ID) |
| 75 | --- | ACBXERRE (Error buffer sequence number) |
| 78 | --- | ACBXSUBR (Subcomponent response code) |
| 7A | --- | ACBXSUBS (Subcomponent response subcode) |
| 7C | --- | ACBXSUBT (Subcomponent error text) |
| 80 | --- | ACBXLCMP (Compressed record length) |
| 88 | --- | ACBXLDEC (Decompressed record length) |
| 90 | --- | ACBXCMDT (Command time) |
| 98 | --- | ACBXUSER (User area) |
| A8 | --- | ACBXRSV4 (reserved 4) |
If an Adabas call using the ACBX interface is made that requires buffer specifications, Adabas buffer descriptions (ABDs) must be used. ABDs must not be used when specifying an Adabas call using the classic ACB interface; if an Adabas call using the ACB interface is made that requires buffer specifications, specify the buffers or pointers to the buffers directly in the Adabas call itself. For more information about the ACBX and ACB interface direct calls, read Calling Adabas.
As the ACBX interface supports segmented buffers (multiple pairs of format and record buffers, or multiple triplets of format, record, and multifetch buffers), the total number of buffers in an ACBX call is not fixed and limited. The individual buffers are no longer described by fields in the ACBX itself (in the way the buffer lengths are defined in the ACB); instead, each buffer has its own Adabas buffer description (ABD) structure that describes what kind of buffer it is, where it is located, what size it is, and other pertinent information.
In UNIX and Windows applications, the addresses of ABDs are specified in the ABD list associated with the call; in mainframe system applications, the addresses of ABDs are specified directly in the Adabas call.
This section describes the structure of an ABD and ABD lists:
Using ABDs in an ACBX interface direct call, the buffers used in a direct call can be contiguous or discontiguous. You can define ABDs for the following types of buffers:
Format buffers
Record buffers
Multifetch buffers
Search buffers
Value buffers
ISN buffers
Each Adabas buffer segment is represented by a single ABD, although you can define multiple ABDs of a given type in the same program. Offset 4 (ABDID) in each ABD identifies the type of buffer defined by the ABD.
In an ACBX interface call, there is a one-to-one correspondence between ABD and buffer specifications; each buffer you want to specify must have a corresponding ABD. The buffer can be specified in the ABD itself or referenced by indirect reference.
ABDs can be specified in any sequence in an ACBX interface direct call. However, if an ABD requires a matching ABD of another type, Adabas will match them sequentially. For example, if three format buffer ABDs and three record buffer ABDs are included in the call, the first format buffer ABD in the call is matched with the first record buffer ABD in the call, the second format buffer ABD is matched with the second record buffer ABD, and the third format buffer ABD is matched with third record buffer ABD.
If unequal numbers of match-requiring ABDs are specified, Adabas will generate a dummy ABD (with a buffer length of zero) for the missing ABD. For example, if three format buffer ABDs are specified, but only two record buffer ABDs are specified, a dummy record buffer ABD is created for use with the third format buffer ABD. If you would prefer that the dummy record buffer ABD be used for the second format buffer ABD instead, you must specify the dummy record buffer ABD yourself prior to the record buffer ABD to be used by the third format buffer ABD.
For commands where data in the record buffer is not described by a format specification in the format buffer, no format buffer segments need be specified; if any are specified, they are ignored. This applies to only a few commands; the most prominent of them is OP.
For information about the relationships between different buffer types, read Understanding the Different Buffer Types.
The following table describes the structure of the ABD.
| Name | Field | Control Block Position | Offset | Length (in bytes) | Format |
|---|---|---|---|---|---|
| ABDLEN | ABD length | 1-2 | 00 | 2 | binary |
| ABDVER | Version indicator | 3-4 | 02 | 2 | binary |
| ABDID | Buffer Type ID | 5 | 04 | 1 | alphanumeric |
| ABDRSV1 | Reserved 1 | 6 | 05 | 1 | binary |
| ABDLOC | Buffer location flag | 7 | 06 | 1 | alphanumeric/binary |
| ABDRSV2 | Reserved 2 | 8 | 07 | 1 | binary |
| ABDRSV3 | Reserved 3 | 9 | 08 | 4 | binary |
| ABDRSV4 | Reserved 4 | 13 | 0C | 4 | binary |
| ABDSIZE | Buffer size (allocated length) | 17-24 | 10 | 8 | binary |
| ABDSEND | Data length to send | 25-32 | 18 | 8 | binary |
| ABDRECV | Data length received | 33-40 | 20 | 8 | binary |
| ABDRSV5 | Reserved 5 | 41-44 | 28 | 4 | binary |
| ABDADR | Indirect address pointer (if ABDLOC= C'I') | 45-48 | 2C | 4 | alphanumeric |
| --- | Buffer (if ABDLOC=C' ' or X'00') | 49-n | 30 | user-defined | not applicable |
Each of the fields in the ABD is described in this section, in the order they appear in the ABD structure.
Required. Use this field to specify the length of the ABD. Currently, the value of this field must be 48.
Required. This field identifies the version of the ABD structure. A value of C'G2' in this field indicates that the buffer definition is in the new, extended ABD structure.
Required. Use this field to identify the type of buffer described by the ABD, as shown in the following table:
| ID Setting | Type of Buffer |
|---|---|
| C'F' | Format |
| C'I' | ISN |
| C'M' | Multifetch |
| C'R' | Record |
| C'S' | Search |
| C'V' | Value |
This field is reserved and must be set to binary zeros.
Required. Use this field to identify whether the location of the buffer is defined at an indirect address or is defined at the end of the ABD itself. If this field is set to "I" (C'I'), Adabas assumes indirect addressing is specified and will use the address specified in the indirect address pointer field (ABDADDR). In this case the buffer must reside in 31-bit addressable storage in the primary address space.
If this field is blank (C' ') or contains hexadecimal zeros, the buffer must immediately follow the ABD.
This field is reserved and must be set to binary zeros.
This field is reserved and must be set to binary zeros.
This field is reserved and must be set to binary zeros.
Required. Use this field to specify the size of the buffer (in bytes), as it is allocated. A size of zero indicates a dummy buffer, which is treated as if it was not specified at all.
Required. Use this field to specify the length of the data (in bytes) to be sent to Adabas. The maximum value of this field cannot exceed the value set for the buffer size field (ABDSIZE). A buffer is sent to Adabas only if it is an input buffer for the type of command being issued.
Note:
At this time, you must specify the same value for this field
as you specify for the maximum buffer size (ABDXSIZE field). This is a
temporary limitation of Adabas Version 6.1, that will be resolved in a future
release.
This field specifies the length of the data (in bytes) returned to Adabas. The Adabas router sets this value at the end of call processing. The maximum value of this field will not exceed the value set for the buffer size field (ABDSIZE). A buffer is received from Adabas only if it is an output buffer for the type of command being issued.
This field is reserved and must be set to binary zeros.
If you set the buffer location flag field (ABDLOC) to C'I' (indirect buffer), specify the address of the actual buffer in this field. More than 32 KB of data can now be specified in an Adabas buffer.
If you set the buffer location flag field (ABDLOC) to C' ' (blanks), this field should contain the actual buffer. More that 32 KB of data can be specified in an Adabas buffer using the ACBX interface. For complete information on defining buffers, read Defining Buffers.
An ABD list is a file containing a list of pointer references to the Adabas buffer descriptions (ABDs) used for a direct call. ABD lists are used only for open systems ACBX direct calls. In the list, one ABD pointer is required for every buffer segment that is needed for the direct call.
ABD lists can include pointers to the ABDs for the following types of buffers: format, record, multifetch, search, value and ISN. Multiple ABDs of the same type can be specified in an ABD list.
ABDs can be specified in the list in any sequence. However, if an ABD requires a matching ABD of another type, Adabas will match them sequentially. For example, if three format ABDs and three record ABDs are included in the list, the first format ABD in the list is matched with the first record ABD in the list, the second format ABD is matched with the second record ABD, and the third format ABD is matched with third record ABD. If unequal numbers of match-requiring ABDs are listed (for example, if three format ABDs are listed, but only two record ABDs), Adabas will generate a dummy ABD for the missing ABD (in this case a dummy record ABD will be created).
For complete information about the relationships between the different types of ABD or buffer specifications, read Understanding the Different Buffer Types.
If your direct calls use the ACB direct call interface, you can define five different types of buffers: format, record, search, value, and ISN buffers. These buffers are specified elsewhere in your application and are indirectly referenced in the ACB direct call (via pointer references).
If your direct calls use the ACBX direct call interface, you can define different types of buffer segments using Adabas buffer descriptions (ABD) and their associated buffer definitions: format, record, multifetch, search, value and ISN buffers. Each Adabas buffer segment is represented by a single ABD, although you can define multiple ABDs of some types in the same program. (For example, you can define multiple format ABDs for use by the same program.) A single buffer definition is associated with each ABD -- either indirectly by pointer reference or directly in the ABD itself. For detailed information about ABDs, including their structure, read Adabas Buffer Descriptions (ABDs).
This section covers the following topics:
| Understanding the Different Buffer Types | Describes the different buffer types and the relationships between them, and correspondingly, the relationships between their associated ABDs (if you are making ACBX interface direct calls). |
| Format and Record Buffers | Describes format and record buffers and their syntax, together with examples |
| Multifetch Buffers | Describes multifetch buffers and their syntax. |
| Search and Value Buffers | Describes search and value buffers and their syntax, together with examples |
| ISN Buffers | Describes ISN buffers and their syntax. |
The following syntax depicts the relationships between the different types of buffers that can be specified for a direct call. It should assist you in determining which buffer specifications are dependent on the presence of others.
Notes:
[format-buffer record-buffer... [multifetch-buffer]]... [search-buffer value-buffer] [ISN-buffer]
The following table describes the elements in this syntax:
| Element | Description | Conditions |
|---|---|---|
| format-buffer | A format buffer segment to use for the call. Each format buffer segment must end with a period and be a complete and valid standalone format buffer. | Required only if you need to specify the
fields to be processed during the execution of an Adabas read or update
command.
When required, multiple format buffers can be specified for an ACBX interface direct call. Only one format buffer can be specified in an ACB interface direct call. If a format buffer is specified in the call, a corresponding record buffer must also be specified. Optionally, in an ACBX interface direct call,a corresponding multifetch buffer can also be specified. |
| ISN-buffer | An ISN buffer segment to use for the call. | Required only if you need to set aside an
area in storage to store ISNs or (in the case of an ACB interface direct call)
an area to store the record descriptor elements (RDEs) of multifetched records.
When required, only one ISN buffer should be specified for the call. |
| multifetch-buffer | A multifetch buffer segment to use for the ACBX interface call. This buffer is only available for ACBX interface direct calls. |
Used only by ACBX interface direct calls and required only if you need to set aside an area in storage to store the record descriptor elements (RDEs) of multifetched records. When required, multiple multifetch buffers can be specified for an ACBX interface direct call. If a multifetch buffer is specified, corresponding format and record buffers must also be specified. |
| record-buffer | A record buffer segment to use for the call. | Required only if you need to set aside an
area of storage to store record data required or collected for the call.
When required, multiple record buffers can be specified for an ACBX interface direct call. Only one record buffer can be specified in an ACB interface direct call. If a record buffer is specified in the call, a corresponding format buffer must also be specified. Optionally, in an ACBX interface direct call,a corresponding multifetch buffer can also be specified. |
| search-buffer | A search buffer segment to use for the call. | Required only if search criteria are
required to select records for the call.
If a search buffer is specified in the call, a corresponding value buffer must also be specified. Only one search and value buffer pair can be specified in a single direct call. |
| value-buffer | A value buffer segment to use for the call. | Required only if search criteria are
required to select records for the call.
If a value buffer is specified in the call, a corresponding search buffer must also be specified. Only one search and value buffer pair can be specified in a single direct call. |
The format buffer specifies the fields to be read/updated during the execution of an Adabas read/update command.
For read commands, the values of the fields specified in the format buffer are returned by Adabas in the record buffer.
Format Buffer AA,BB. names of the fields to be read
Record Buffer value(AA) value(BB) field values returned by Adabas
For add/update commands, the new values for the fields specified in the format buffer are provided by the user in the record buffer.
Format Buffer XX,YY. names of the fields to be updated
Record Buffer value(XX) value(YY) field values provided by user
This section describes the syntax used to construct the format buffer.
The field names used in the examples in this section are based on the two file definitions contained in Appendix A in this manual.
Note:
There are several restrictions for format buffers, which are
described in Messages and Codes, Nucleus Response
Codes, response
41.
The syntax of the format buffer is as follows:
{[{nX|'literal'}, ...] field_definition [segment | {,length}] [,format] [,edit_mask][,#'char_set']}, ... .
A comma must be used to separate adjacent format buffer entries. One or more spaces may be present between entries. The last entry may not be followed by a comma. The format buffer must be terminated with a period.
The following special option is available: a format buffer with the value `C.' will return the compressed record in the record buffer.
The terms nX, literal, field_definition, segment, length, format, edit_mask and #'char_set', which are used in the syntax of the Format Buffer, are described below.
For READ commands, nX specifies that n spaces are to be inserted in the record buffer by Adabas immediately before the next field value. The maximum allowed value of n is 253.
Format Buffer AA,5X,BB. 5 blanks are to be inserted between
values for fields AA and BB
For UPDATE commands, nX causes n positions in the record buffer to be ignored by Adabas.
Format Buffer AA,5X,BB. 5 positions between values for fields
AA and BB are to be ignored
Record Buffer value(AA) 5 bytes value(BB)
For READ commands, the character string contained within the quotation marks is to be inserted in the record buffer immediately before the next field value. The character string provided may be 1 - 254 bytes in length and may contain any alphanumeric character except a quotation mark.
Format Buffer AA,'text',BB. 'text' is to be inserted between
values for AA and BB
Record Buffer value(AA)text value(BB)
The field_definition field indicates the elementary field, multiple-value field or periodic group to be used. Ranges of adjacent elementary fields can also be specified. For multiple value fields (MU) and periodic groups (PE), index ranges can be specified. The permissible combinations are as follows, where the field name is indicated by `name':
name [mu_pe_index] name A [mu_pe_index] name [pe_index]C name S name-name name L[mu_pe_index] name D[mu_pe_index]
where mu_pe_index is one of:
mu_index pe_index pe_and_mu_index
mu_index specifies an MU index or a range of MU indicies for an MU field. pe_index specifies a PE index for a PE or a range of PE indices for a PE. For mu_index and pe_index the following values may be specified:
- i
MU index for MU field or PE index for PE
- i-j
Range of MU indices or PE indices
- N
highest MU index for MU field or PE index for PE
- 1-N
Range of all MU indices or PE indices (not permitted with update commands)
Note:
If you specify 1-N, and no value exists, because the periodic group or the multiple-value field is empty, no occurrence is displayed. This is an inconsistency to mainframe, where at least one occurrence is displayed.
pe_and_mu_index specifies a PE index or a range of PE indices, and an MU index or a range of MU indices for an MU field in a PE. The following values may be specified:
- i(m)
i = PE index, m = MU index for MU field in PE
- i(m-n)
i = PE index, m-n = range of MU values for MU field in PE
- i(N)
i = PE index, N = highest MU index for MU field in PE
- i(1-N)
i = PE index, range of all MU indices for MU field in PE (not permitted with update commands)
- N(m)
N = highest PE index, m = MU index for MU field in PE
- N(m-n)
N = highest PE index, m-n = range of MU indices for MU field in PE
- N(N)
Highest PE index and highest MU index for MU field in PE
- N(1-N)
Highest PE index, range of all MU values for MU field in PE (not permitted with update commands)
- i-j(m)
i-j = range of PE indices, m = MU index for MU field in PE
- i-j(m-n)
i-j = range of PE indices, m-n = range of MU indices for MU field in PE
- i-j(N)
i-j = range of PE indices, N = highest MU index for MU field in PE
- i-j(1-N)
i-j = range of PE indices,1-N = range of all MU values for MU field in PE (not permitted with update commands)
If you specify a range both for the MU indices and for the PE indices, the corresponding sequence of record buffer elements starts with all specified elements for the lowest specified PE index, and ends with all specified elements for the highest specified PE index.
AA1-2(3-4) |
Is equivalent to AA1(3),AA1(4),AA2(3),AA2(4). |
These combinations are described in detail in the following.
The following combinations are permitted for name [mu_pe_index]:
name
The name of the field (or group) for which the value (or values) is requested, or a new value (or values) is being provided.
The name specified must be two characters in length and must be present in the field definition table of the file being read/updated.
The name may refer to an elementary field, a group or a multiple-value field. The field or group must not belong to a periodic group. The first occurence of a multiple-value field without MU index references the first value of the multiple-value field, the second occurence to the second value of the multiple-value field, etc. The same multiple-value field should not be specified without MU index and with MU index in the same format buffer; the results of a command using such a format buffer are undefined.
A subdescriptor or superdescriptor name may be specified for an access command if no parent field of the descriptor is a multiple field or a field within a periodic group. Phonetic or hyperdescriptors must not be used. For the L9 command, any descriptor other than a phonetic descriptor is allowed.
For UPDATE commands, the same name may not be used more than once (except in the case of multiple-value fields as explained below).
A name which refers to a group results in all of the fields within the group being referenced.
GA |
Refers to group GA (equivalent to the specification AA,AB). |
A group name may not be used if the group contains a multiple-value field.
The use of group names will result in a significant reduction in the time required to process the command.
Specifying multiple-value fields without an index in an UPDATE command allows you to replace all old multiple-value field values by exactly the number of fields specified in the format buffer. In this way, the multiple-value field count of an MU field without the NU option can be reduced again.
name mu_or_pe_index
The user must specify which occurrence is to be referenced, if one of the following is to be referenced:
a periodic group;
a field within a periodic group that is not a multiple-value field;
a multiple-value field;
a subdescriptor or superdescriptor with a field within a periodic group as parent field, which does not have a multiple-value field as parent field;
a subdescriptor or superdescriptor with a multiple-value field as parent field, which does not have a field within a periodic group as parent field.
This is done by appending a numeric subscript (leading zeros permitted) to the name.
Note:
Subdescriptors or superdescriptors with fields within a
periodic group or a multiple-value fields as parent field in the format buffer
are not supported with Adabas versions < 5.1.
GB3 |
The third occurrence of the periodic group GB is referenced (fields BA3, BB3, BC3). |
BB6 |
The field BB in the 6th occurence of the periodic group GB is referenced. |
MF02 |
The second value of the multiple-value field MF is referenced. |
N refers to the last occurence of a periodic group, a field in the last occurence of a periodic group or a multiple-value field for a read command; for an update command, a new occurence will be appended. A periodic group name must not be used if the periodic group contains a multiple-value field.
A range of occurrences of a periodic group (or a field within a periodic group) may be referenced by specifying the first and last occurrence number to be referenced (connected by a hyphen) after the name. A multiple-value field may also be referenced. A descending range may not be specified. A periodic group name must not be used if the periodic group contains a multiple-value field.
GB2-4 |
The second through fourth occurrences of the periodic group GB are referenced (BA2, BB2, BC2, BA3, BB3, BC3, BA4, BB4, BC4). |
BA2-4,BC2-4 |
The second through fourth occurrences of BA and BC are referenced (BA2, BA3, BA4, BC2, BC3, BC4). |
MF1-3 |
The first 3 values of the multiple-value field are referenced. |
GB2-GB4 |
Invalid, incorrect syntax. |
GB4-2 |
Invalid, descending range. |
name 1-N means the first to the last occurrence of the field.
name mu_and_pe_index
If a multiple-value field contained within a periodic group or a subdescriptor or superdescriptor where a parent field is a field within a periodic group and a parent field is a multiple-value field (they can be the same – a multiple-value field within a periodic group) is to be referenced, the periodic group occurrence number (i), followed by the desired multiple-value field value (m) or range of values (m-n), must be specified.
Note:
Subdescriptors or superdescriptors with fields within a
periodic group or a multiple-value fields as parent field in the format buffer
are not supported with Adabas versions < 5.1.
CB2(5) |
The fifth value of the multiple-value field CB in the second occurrence of the periodic group GC is to be referenced. |
CB2(1-5) |
The first five values of the multiple-value field CB in the second occurrence of the periodic group GC are to be referenced. |
N means the last occurrence of either the last occurrence of the element in a periodic group or the last value of a multiple-value field or both. In an update command, this means an append of a value.
If a range of multiple-value field values within a range of periodic group occurrences is to be referenced, the range of the periodic group occurrences (i-j), followed by the range of the multiple-value field values (m-n) must be specified.
CB1-2(1-4) |
The first four values of the multiple-value field CB in the first occurrence of the periodic group GC are referenced, followed by the first four values of CB in the second occurrence of GC. |
Appending an `A' to the name of an elementary field, a multiple-value field, a field within a periodic group, or a multiple-value field within a periodic group indicates the add option. The permitted combinations are the same as for name [mu_pe_index].
If this option is used, a value can be added to a field instead of the value in the field being overlayed. This saves some Adabas calls, e.g. the sequence L4-A1 can be reduced to a single A1 call.
The following formats are supported: unpacked (U), packed (P), fixed point (F) and floating point (G).
For all commands other than A1, the A suffix is ignored.
The highest occurrence number of a periodic group, or the number of existing values of a multiple-value field, or the number of existing values of a multiple value field in a PE for one occurrence or a range of occurrences of the PE may be obtained by appending the literal `C' to the periodic group or multiple-value field name.
GBC |
The highest occurrence number of the periodic group GB is referenced. |
MFC |
The number of existing values of the multiple-value field MF is referenced. |
For UPDATE commands, a `C' element is ignored and its corresponding count within the record buffer is skipped.
The count is returned in the record buffer as a one-byte binary number, unless an explicit length and/or format is specified by the user (see length and format parameters).
The count of the existing values of a multiple-value field within a periodic group may be obtained by indicating the periodic group occurrence with a one or two digit index and the literal `C' immediately following the multiple-value field name.
CB4C |
The count of the existing number of values of the multiple-value field CB in the fourth occurrence of the periodic group GC is referenced. |
For UPDATE commands, a `C' element is ignored and its corresponding count within the record buffer is skipped. This is one byte for count fields which are specified without a length override.
The user cannot directly update the contents of multiple-value field or periodic group count fields. These count fields are automatically updated by Adabas when multiple-value field values and periodic group occurrences are added/deleted.
MFNC |
Specifies the count of existing values of the multiple-value field in the final periodic group. |
The `S' element is used when reading or updating the SQL null–value attribute of fields which have SQL null-value support. The `S' element is formed by appending the literal `S' to the field name.
This element can only be applied to elementary fields that are not in a periodic group, with the NC option (SQL null value supported) specified. If no other format or length is specified, it is 2 bytes long and the format is fixed point.
For UPDATE commands, the SQL null value will be stored in the field if the corresponding value in the record buffer is –1. Any other negative values result in a response 52. Positive values and 0 are ignored.
The `S' element is only required for UPDATE commands if the elementary field is being changed to the null value; otherwise the `S' element is not required but may be used. The `S' element and name element can be anywhere within the format buffer. When an `S' element updates a field's value to null then a following name element is ignored.
Several format buffer elements which refer to the same field cannot be contained within a format buffer for an UPDATE command.
For READ commands, the following information is returned in the `S' element:
| Value in S element | Meaning |
|---|---|
| -1 | Field contains the SQL null value. |
| 0 | Field is significant and the value is not truncated. |
| 1 | Field is significant and the value is truncated, the length of the value does not fit into the S element (for example, with default format F and default length 2: value length is greater than 32767). |
| >1 | Field is significant and the value is truncated: length of the value. |
The notation name-name may be used to reference a series of consecutive fields (as ordered in the field definition table). The user specifies the beginning and ending field names connected by a hyphen. No multiple-value field or periodic group may be contained within the series, and no length or format override is permitted.
A name which refers to a group may not be specified as the beginning or ending name, but a group may be embedded within the series.
Standard format and length is in effect for all the fields within the series.
AA-AC |
The fields AA, AB and AC are referenced. |
AA-GC |
Invalid, the series may not contain a multiple-value field or periodic group. |
GA-AC |
Invalid, the series may not begin/end with a group. |
AA,5,U,-AD |
Invalid, a length and/or format override is not permitted with a series notation. |
The format buffer indicator, L, can be used to retrieve or specify the actual length of any alphanumeric or Unicode field value that is either a multiple-value field or a field within a periodic group. This format buffer element is referred to as the length indicator.
The length indicator is specified using the field name followed by the character L (for example, FB='ACL.' would return the length of the AC field). By default, the compressed field length is returned in four-byte binary format.
When used with MU or PE fields, the length indicator must specify occurrence indices, including the range of occurrence index.
Consider the following examples.
In the following example, the length of the fifth value of the multiple-value field CB in the second occurrence of periodic group would be returned:
FB='CBL2(5).'
In the following example, the lengths of the first ten values of multiple-value field MF would be returned:
FB='MFL1-10.'
The following example for the multiple-value field MF is illegal as the length indicator does not support MU fields without an occurrence index:
FB='MFL.'
Using the D element (daylight saving time indicator) in the format buffer is only allowed for fields with DT and TZ option. It indicates if daylight saving time was active for the date/time value. The default format for a D element is F with length 2 bytes. Its value is the number of seconds to be added to the standard time in order to get the current local time; this is usually 0 when daylight saving time is not active and 3600 when daylight saving time is active. For update format buffers, the value of the D element is subtracted from the value specified for the field in the record buffer in order to get the standard time. Using the D element also allows you to specify time values during the hour in which the daylight saving time is switched off again. If you specify date/time values in this hour, which occurs twice in add/update commands without a D element, it is assumed the values belonging to standard time are meant. In add/update commands for each D element there must be a 1:1 relationship between the D element and the corresponding date/time edit mask element. If your format buffer contains a D element, the value must be a correct daylight saving time indicator value valid for the time specified; otherwise you get a response code 55 with subcode 31.
In add and update commands, it is possible to specify the moment when the standard time or the daylight saving time ends, both as standard time and as daylight saving time value, but if you read such a value again, it is always displayed as the beginning of the new time period.
In the following example, the local time zone is MET (Middle European Time)., and field values for a field defined with the edit mask E(DATETIME) are read:
| Internal Value (UTC) | Field Values for Edit Mask E(DATETIME) | Value of D Element |
|---|---|---|
| 20080121135000 | 20080121145000 | 0 |
| 20091025003000 | 20091025023000 | 3600 |
| 20091025013000 | 20091025023000 (1) | 0 |
(1) In add or update commands it is also possible to specify 20091025030000 with D element 3600.
The length and format parameters are used to indicate that a field value is to be returned or provided in a length and/or format different from the standard length and/or format of the field.
The length specified must be large enough to contain the value in the chosen format and must not exceed the maximum length permitted (see following figure).
For alphanumeric and Unicode fields you can specify an asterisk (*) instead of a length in the format element. The presence of an asterisk indicates that the amount of space available for the field value in the record buffer is variable and depends on the actual value of the field. However, unlike the zero length specification setting, no four-byte length field precedes the field value in the record buffer; the record buffer area corresponding to the format element only contains the value of the field. The actual field value length should be retrieved for read commands and must be specified for update commands using the new format buffer length indicator, L. For more information about the length indicator, read Length Indicator (L), elsewhere in this guide.
In the following example, the record buffer for LB field L1 contains only the value of the L1 field, followed by the value of the AA field for which 10 bytes have been allotted.
FB='L1,*,AA,10,A.'
In the following example, the record buffer for LB multi-value field L2 contains the first ten values of L2.
FB='L21-10,*.'
The record buffer is not necessarily required to provide sufficient space for the entire field if its format element includes an asterisk length setting. However, in read command processing, the field value can be truncated if both of the following conditions are met:
The record buffer space available is insufficient for the field value.
A field with asterisk notation is specified at the end of the format buffer.
In these conditions, no error is returned. If this were the case
in the second example above (FB='L21-10,*.'), Adabas would
truncate the ten values to be read down to the length of the corresponding
record buffer segment. (The truncation occurs from right to left; that is, the
last value is truncated first; if the remaining space is still insufficient,
the second-to-last value is truncated, and so on.) In extreme cases, if no
space is available at all for the field value, the value is truncated down to
zero bytes.
In the first example above (FB='L1,*,AA,10,A.'), if
the record buffer segment is too short, no truncation occurs because this is
not allowed for fields specified with a fixed length or length of zero (0).
Instead, the nucleus returns response code 53 (record buffer too small).
Only read commands executed by the Adabas nucleus may truncate values specified with the asterisk notation; no truncation occurs in update commands. In addition, the ADACMP utility does not truncate values specified with the asterisk notation.
The format specified must be compatible with the standard format of the field (see the following table of length/format parameters). The processing rules for format conversion are shown later in this section.
These parameters may only be specified for an elementary or multiple-value field.
If the length and/or format parameters are omitted, the field value is returned/must be provided according to the standard length and/or format of the field. If a length of zero is specified, or name refers to a field which is defined as a variable-length field (no standard length), the value returned by Adabas will be preceded by a binary field which contains the length of the value (including the length indicator). For UPDATE commands, this length indicator must be provided by the user. The length of the length indicator is
4 bytes if the field has the L4 option;
2 bytes if the field has the LA option;
1 byte if the field has neither of these options.
| Source Format |
Max. Length |
Explanation |
Destination Formats |
|---|---|---|---|
| A | 16381 (if the field has the option L4 or LA and is not a descriptor), or 1114 (if the field has the L4 or LA option and is a descriptor), else 253 | Alphanumeric | A |
| B | 126 | Binary (unsigned) | A, F, P, U |
| F | 8 | Fixed point (signed) | A, B, P, U |
| G | 8 | Floating point | G |
| P | 15 | Packed decimal Signed, `+' = nA, nC, nE, nF `–' = nB or nD in least significant byte, where `n' is the least significant digit of a given value |
A, B, F, U |
| U | 29 | Unpacked decimal Signed, `+' = 3n in least significant byte `–' = 7n in least significant byte, where `n' is the least significant digit of a given value (as in zoned format) |
A, B, F, P |
| W | For the internal value stored in UTF-8: 16381 (if the field has the option L4 or LA, and is not a descriptor), 1144 (if the field has the option L4 or LA, and is a descriptor), else 253. The external values, which may use different encodings, may be larger, if the field has the option LA or L4, but without one of these options the external values are also limited to 253 bytes. | Unicode | W |
All lengths are in bytes. The signs in P and U formats are hexadecimal in nibbles or bytes.
Conversion from BINARY is limited to values between 0 and 2**64 - 1; conversion to BINARY is limited to values between 0 and 2**80 -1.
Conversion from or to FIXED POINT is limited to values between -(2**63) and 2**63 - 1.
Conversion from a numeric format to alphanumeric results in an unpacked value, left–justified, without leading zeros and with trailing blanks. For example, the three–byte packed value `10043F' would be converted to `3130303433202020'. Value truncation is possible with this type of conversion. Floating point fields (G format) cannot be converted to another format. Conversions from 4 byte G format to 8 byte G format and vice versa are also not allowed.
Note:
Starting with Adabas Version 6.3 SP2, for source format U,
the sign bytes on EBCDIC machines, converted to ASCII, are also allowed as
input for the sign bytes (see following table):
| Digit | EBCDIC, Hex | Display | ASCII, Hex |
|---|---|---|---|
| +0 | C0 | { | 7B |
| +1 | C1 | A | 41 |
| +2 | C2 | B | 42 |
| +3 | C3 | C | 43 |
| +4 | C4 | D | 44 |
| +5 | C5 | E | 45 |
| +6 | C6 | F | 46 |
| +7 | C7 | G | 47 |
| +8 | C8 | H | 48 |
| +9 | C9 | I | 49 |
| -0 | D0 | } | 7D |
| -1 | D1 | J | 4A |
| -2 | D2 | K | 4B |
| -3 | D3 | L | 4C |
| -4 | D4 | M | 4D |
| -5 | D5 | N | 4E |
| -6 | D6 | O | 4F |
| -7 | D7 | P | 50 |
| -8 | D8 | Q | 51 |
| -9 | D9 | R | 52 |
When the length indicator is specified for a field in the format buffer of a read command, the number of bytes required for the field value in the record buffer (without padding and with no further length indication) is returned at the corresponding field position in the record buffer. The amount of space required in the record buffer is based on the field format and the UES-related definitions for the database, file, and user.
For Unicode fields, the length indicator currently always returns the internal length, i.e. the length of the value in UTF-8 encoding. This may be changed in a future version of adabas, so that the length of the value in another encoding is returned. It is, therefore, strongly recommended that you currently use the length indicator for reading W fields only if the default encoding for the Adabas session is UTF-8 and if no encoding is specified in a corresponding format buffer element with asterisk length. Otherwise you may receive different results with a future version of Adabas.
If character LB field L1 (format A) contains a 40,000-byte value, consider the following examples:
Suppose the format buffer specification for L1 is:
FB='L1L,4,B.'
The record buffer will contain the four-byte binary length of the value of field L1:
0x00009C40
Suppose the format buffer specification for L1 is:
FB='L1L,4,B,L1,*,A.'
The record buffer will contain the four-byte binary length of the value of field L1 at the beginning of the record buffer area , followed by 40,000 characters of the actual L1 data.
If a field in the format buffer is specified with its
corresponding length indicator (for example, FB='L1L,4,B,L1,*.'),
and if the field is not subject to blank compression (the NB option
is specified for the field in the FDT), the length returned is the
number of bytes specified when the value was stored. However, if the field is
subject to blank compression, the length returned is the number of significant
left-most bytes, beyond which the value is padded with blanks.
If a field in the format buffer is specified with its
corresponding length indicator (for example, FB='L1L,4,B,L1,*.'),
and if the field is null suppressed (the NU option is specified for the field
in the FDT) and the field value is all blanks, the returned field value length
is zero; if the field is not null suppressed, the returned field value length
is the length of one blank (one byte for alphanumeric fields and UTF-8 Unicode
fields).
When a length indicator is specified in the format buffer for an update command, the corresponding value in the record buffer specifies the actual value length of the field in the record buffer. Only one length indicator for the base field can be specified and it must be accompanied by the asterisk (*) length notation in the format buffer.
The length indicator must occur in its format buffer segment prior to any format element that implies a variable length in the record buffer (due to the use of asterisk notation or zero length notation). In other words, the length indicator is located in a constant position, independent of the values of any fields mentioned in the format.
In addition, if you elect to combine the length indicator and an asterisk length notation value request in the same format buffer for an MU or PE field, the value requests must use corresponding ranges as the length requests. It does not matter whether the length requests and value requests are specified in the same or different format buffer segments. Consider the following examples, where XX is an LA or LB field with the MU option:
The following valid examples request the length of the first two values of the XX field as well as their actual values.
FB='XXL1-2,XX1-2,*.'
FB='XXL1,XXL2,XX1,*,XX2,*.'
The following invalid examples are attempts to request the length of the first two values of the XX field as well as their actual values. However, these examples are invalid because the ranges specified for the MU field in the length and value requests are not specified in a corresponding manner.
FB='XXL1,XXL2,XX1-2,*.'
FB='XXL1-2,XX1,*,XX2,*.'
The following two format buffers request the length of the third and fourth values of the XX field, as well as their actual values.
FB='XXL3,XXL4.'
FB='XX3,*,XX4,*.'
The following invalid format buffers attempt to request the length of the third and fourth values of the XX field, as well as their actual values, but fail because the ranges specified for the length and value requests are not specified in a corresponding manner.
FB='XXL3,XXL4.'
FB='XX3-4,*.'
Specifying segment instead of length allows you to process only a part of a field, which is of particular interest for LOB fields. You can only specify segment for fields defined with the format A. segment has the following syntax:
(byte_number, length [, length2])
For MU fields in PE, segment can only be specified if both the PE and MU index have been specified. If no segment is specified, the complete field is processed.
byte_number specifies the byte number of the first byte of the field segment to be processed; byte_number may be either a number or ‘*’.
If a number is specified, it denotes the position of the byte within the value where the segment to be processed start; the first (leftmost) byte of the value has byte number 1.
If you specify byte_number = ‘*’, it is called the *-position. If you specify a *-position, it means that the segment starts at the current position. For an L1, L4 or A1 command with command option 2=‘L’, the current position is specified in the field ISN LOWER LIMIT in the control block as the number of bytes preceding the segment to be processed; by specifying a *-position you can process different segments of a field using the same format buffer. For other commands, the current position is always the first (leftmost) byte of the field value. In a read command, only one field value can be processed with *-position; therefore, more than one format buffer element with *-position must not be specified in the format buffer.
Notes:
length is the length in bytes of the field segment to be processed. The specified number of bytes must be provided at the corresponding position in the record buffer.
length2 is optional and relevant only for update (A1) commands; for other commands length2 is ignored. It specifies the length of the area in the old value that is replaced by the new segment; if specified, currently the value of length2 must be equal the value of length. If not specified, all remaining data of the old field value starting from position byte_number is replaced by the data in the record buffer.
Notes:
edit_mask is one of:
numeric_edit_mask E(date_time_edit_mask_name)
Numeric edit masks are used according to the standard edit mask rules as used in the COBOL programming language.
A numeric edit mask may only be specified for numerically-defined fields. All data that is being returned by Adabas to an edited field is converted to unpacked decimal format, regardless of the standard format of the field. The maximum number of digits (other than edit characters) which may be returned to an edited field is 15.
The user must ensure that the length parameter for the field for which an edit format has been specified is sufficiently large to contain the field value plus all required edit characters, otherwise Adabas will return a response code.
| Format | Default Length | Numeric Edit Mask Generated Maximum Length |
|---|---|---|
| E1 | 15 | zzzzzzzzzzzzzzz |
| E2 | 16 | zzzzzzzzzzzzzz9- |
| E3 | 17 | zzzzzzzzz99.99.99 |
| E4 | 17 | zzzzzzzzz99/99/99 |
| E5 | 20 | z.zzz.zzz.zzz.zzz,zz |
| E6 | 20 | z,zzz,zzz,zzz,zzz,zz |
| E7 | 21 | z,zzz,zzz,zzz,zz9.99- |
| E8 | 21 | z.zzz.zzz.zzz.zz9.99- |
| E9 | 21 | *,***,***,***,**9.99- |
| E10 | 21 | *.***.***.***.**9.99- |
| E11 | - | Reserved |
| E12 | - | Reserved |
| E13 | - | Reserved |
| E14 | - | Reserved |
| E15 | - | Reserved |
Format Buffer Field Value Edited Value XC,15,E1. 009877 bbbbbbbbbbb9877 XC,8,E4. 301177 30/11/77 XB,5,E7. -366 3.66- XB,7,E9. 542 **5.42b
For date/time fields defined with a date/time edit mask you can specify a date/time edit mask. While numeric edit masks are only allowed for read commands, date/time edit masks are also allowed for update commands. The edit masks are the same edit masks that are used in the file definition. The following combinations of edit masks in the field definition and edit masks in the format buffer are allowed (columns=format buffer, rows=FDT):
| DATE | TIME | DATETIME | TIMESTAMP | NATTIME | NATDATE | UNIXTIME | XTIMESTAMP | |
| DATE | A/A | -/- | F/T | F/T | F/T | C/C | F/T | F/T |
| TIME | -/- | A/A | -/- | -/- | -/- | -/- | -/- | -/- |
| DATETIME | T/F | X/- | A/A | F/T | F/T | T/F | C/C | F/T |
| TIMESTAMP | T/F | X/- | T/F | A/A | T/F | T/F | T/F | C/C |
| NATTIME | T/F | X/- | T/F | F/T | A/A | T/F | T/F | F/T |
| NATDATE | C/C | -/- | F/T | F/T | F/T | A/A | F/T | F/T |
| UNIXTIME | T/F | X/- | C/C | F/T | F/T | T/F | A/A | F/T |
| XTIMESTAMP | T/F | X/- | T/F | C/C | T/F | T/F | T/F | A/A |
The first value specifies the behaviour during read commands; the second the behaviour during update commands:
| Value | Meaning |
|---|---|
| -/- | Not allowed. |
| A | Allowed, no conversion required. |
| C | Conversion required; source and target value have the same precision. |
| F | Fill up the value with 0; the target value has a higher precision. Depending on the edit masks, an additional conversion may be required. |
| T | Truncate the value; the target value has a lower precision. Depending on the edit masks, an additional conversion may be required. |
| X/- | Extract the time component from the value for read operations; the target value does not contain date information. Depending on the edit masks, an additional conversion may be required. Only allowed for read operations. |
Adabas allows you to add a date/time edit mask to the field definition of an existing field of formats B, F, P and U. This can result in values in the database that are not correct values for this date/time edit mask.
The following rules apply to the usage of date/time edit masks in the format buffer:
If you don’t specify a date/time edit mask for a field without the TZ option in the format buffer, no date/time conversions and checks are performed.
If you don’t specify a date/time edit mask for a field with the TZ option in the format buffer, the format buffer is treated as the date/time edit mask of the field definition specified.
If you don’t specify length or format together with a date/time edit mask in the format buffer, the default format or length of the field is used - ensure that you specify length or format if the default does not match the date/time edit mask specified.
If a date/time edit mask specified is not compatible with the date/time edit mask in the field definition, you get a response code 41.
If you specify a date/time edit mask for a field defined without the DT option, a check is made to see whether the value is a valid value for this edit mask - if it isn't, you get a response code 55.
If you specify a date/time edit mask that is only allowed only for read commands in the format buffer for an update or add command, you get a response code 44.
If you specify a date/time edit mask in the format buffer for an update or add command, a check is made to ensure that the value is a correct date/time value - you get a response code 55 if the value is not compatible with the edit mask.
If you specified a date/time edit mask in the format buffer for a read command, and the field contains an invalid date/time value, or the length of the field is not sufficient to store the value, you get a response code 55.
This format buffer element may be specified only for W fields, and is used to specify the character set of the corresponding field in the record buffer. You must specify an encoding name that is listed in http://www.iana.org/assignments/character-sets - most of the character sets listed there are supported by ICU, which is used by Adabas for internationalization support.
#'UTF-16BE'
This section provides examples of format buffer and record buffer construction. All the examples in this section refer to the sample Adabas files in Appendix A.
Format Buffer : AA,5X,AB.
Record Buffer : AA value(8 bytes alphanumeric)
5 spaces
AB value(2 bytes packed)
Format Buffer : AA,4,5X,AB,3,U,W1,50,#'UTF-16BE'.
Record Buffer : AA value (4 bytes alphanumeric)
5 spaces
AB value (3 bytes unpacked)
W1 value (50 bytes = 25 characters in UTF-16BE encoding)
Format Buffer : GB1.
Record Buffer : BA1 value (1 byte binary)
BB1 value (5 bytes packed)
BC1 value (10 bytes alphanumeric)
Format Buffer : GB1-2.
Record Buffer : BA1 value (1 byte binary)
BB1 value (5 bytes packed) GB1
BC1 value (10 bytes alphanumeric)
BA2 value (1 byte binary)
BB2 value (5 bytes packed) GB2
BC2 value (10 bytes alphanumeric)
Format Buffer : MF6.
Record Buffer : MF value 6 (3 bytes alphanumeric)
Format Buffer : MF01-02.
Record Buffer : MF value 1 (3 bytes alphanumeric)
MF value 2 (3 bytes alphanumeric)
Format Buffer : GCC,MFC.
Record Buffer : Highest occurrence count for GC (1 byte binary)
Value count for MF (1 byte binary)
Performance improvements may be achieved by using the following guidelines during format buffer construction:
Use group names wherever possible rather than referring to elementary fields individually. The use of group names reduces the time required by Adabas to interpret the format buffer. The use of the field series notation does not result in performance improvements. A field series notation is converted by Adabas into a series of elementary fields;
Use length and format overrides only when necessary. Using overrides requires additional processing time when interpreting the format buffer and when processing the field;
If the same fields of a record are to be read and then updated, the same format buffer should be used for the read and update commands.
The record buffer is used primarily with the read (L1-L6, L9, S1/S2/S4 with read option) and the update (A1, N1/N2) commands.
For read commands, Adabas returns the requested field values in this buffer. The field values are returned in the order specified in the format buffer. A value is returned in the standard length and format defined for the field, unless a length and/or format override was specified in the format buffer. If the value is a null value, it is returned in the format in effect for the field:
| Format | Empty Value Format |
|---|---|
| ALPHANUMERIC | blanks |
| BINARY | binary zeros |
| FIXED POINT | binary zeros |
| FLOATING POINT | binary zeros |
| UNPACKED DECIMAL | unpacked decimal zeros |
| PACKED DECIMAL | packed decimal zeros |
Adabas returns the number of bytes equal to the combined lengths (standard or overridden) of all requested fields.
For update commands, the user provides the values for the fields to be updated in this buffer. If an empty value is being provided, it must be provided according to the format in effect as described above.
The record buffer is also used to transfer information to or from Adabas in the following commands:
End transaction (ET), or close user session (CL). The user provides the data to be stored in an Adabas system file. Storing user data with any of the above commands is optional;
Read ET data (RE). Adabas returns the user data stored in the Adabas system file;
Write user data to the protection log (C5). The user provides the data to be written to the Adabas data protection log;
Open user session (OP). The user indicates the type of updating to be performed (exclusive control or ET logic) together with the files to be accessed/updated. User data stored in the Adabas system file is returned by Adabas (optional);
Read field definitions (LF). Adabas returns the field definitions for the file.
The search and value buffers are used together to define the search criterion to be used to select a set of records using a find command (S1, S2, S4). They are also used read logical sequential (L3/L6) and the read descriptor values (L9) commands to indicate the starting value for a given sequential pass of a file.
The user provides the search expression(s) in the search buffer and the values which correspond to the search expressions in the value buffer.
The search and value buffer are also used with the update record (A1) and delete record (E1) commands; the search buffer syntax for these commands is provided in Adabas Commands.
The search buffer as used with the S1, S2 and S4 commands is constructed according to the following syntax:
search expression [,connecting operator, search expression]... .
A comma must be used to separate all search buffer entries. One or more spaces may be present between entries. The last entry may or may not be followed by a comma. The search buffer must be terminated with a period.
The syntax for a search expression is:
{[name[i]D[,length][,format],] name[i][,length] [,format] [,E(date_time_edit_mask_name)] [,C]
[,#'char_set'][,comparator]} | {nameS[,length] [,format]} | (command_id)
The terms used in this syntax are described in the following sections.
name[i|S]
The name of the field or derived descriptor to be used in the search expression. The name must refer to a field, subdescriptor, superdescriptor, collation descriptor, hyperdescriptor or phonetic descriptor.
If you search for a field within a periodic group, a superdescriptor or collation descriptor derived from a field within a periodic group, or a hyperdescriptor with the PE option, a subscript (leading zeros permitted) may be appended to the name in order to limit the search to only those values located in the occurrence specified. If no subscript is provided, the values in all occurrences will be searched.
If you search for a multiple-value field, or a subdescriptor, a superdescriptor or a collation descriptor derived from a multiple-value field, all values of the field will be used in the search. For this type of fields, it is not possible to restrict the search results by specifying a subscript to only one occurrence of the multiple field.
If the field is defined with the NU option (null value suppression), null values are not stored in the inverted lists; therefore, a search for all the records which have the null value will always result in no records found (even if there are records in Data Storage which contain a null value for the field). This rule also applies to subdescriptors or collation descriptors. A superdescriptor value is not stored if at least one field from which it is derived is defined with the NU option and the value for that field is null.
A search can be made for all of the records that have the SQL null value, by appending an upper case `S' to the field name if the field is defined with the NC option (SQL null value) or with the NU option (null value suppression, here the Adabas null value is interpreted as an SQL null value).
length format
The length and format of the field value as provided in the value buffer may be explicitly stated with these parameters. If the length and/or format parameter is omitted, the value must be provided in accordance with the standard length and format of the field.
Note:
For a superdescriptor, in general, the full length should be
explicitly specified or the default length must be used. Exceptions to this
rule are, for example, superdescriptors that have only alphanumeric parent
fields.
Two figures showing the possible formats which can be used and the processing rules which apply to each format are provided at the end of this section.
E(date_time_edit_mask_name)
Date/time edit masks can be used in the same way as date/time edit masks in the format buffer; please refer to the description of date/time edit-masks in the format buffer for further information.
name[i]D
If you want to specify a date/time value with the daylight saving time indicator, the daylight saving time indicator must be specified first, followed by the field specification including the date/time edit mask. Name and, if specified, the PE index for the daylight saving time indicator must be the same as in the following date/time field specification. The default length and format for the daylight saving time indicator are 2,F.
C
The C option may be specified only for collation descriptors without the HE option. When the option is specified, the corresponding value in the value buffer is not the collating key, but the value of the parent field.
If you don't specify the C option for a collation descriptor without HE option, because you want to specify collation keys that you created yourself with ICU, please note that Adabas uses ICU version 3.2. ICU keys created by a different ICU version may be incompatible with the collation keys used by Adabas.
#'char_set'
This search buffer element may be specified only for W fields, and is used to specify the character set of the corresponding field in the value buffer. You must specify an encoding name that is listed at http://www.iana.org/assignments/character-sets - most of the character sets listed there are supported by ICU, which is used by Adabas for internationalization support.
#'UTF-16BE'
comparator
A comparator may be used as the last entry of a search expression to indicate the logical operation to be performed between the preceding field and its corresponding value in the value buffer.
The following comparators may be specified:
| Comparator | Meaning |
|---|---|
| EQ | equal to |
| NE | not equal to |
| GE | greater than or equal to |
| GT | greater than |
| LE | less than or equal to |
| LT | less than |
For the first operand of an S operator, only the comparators GE and GT are allowed - EQ is also accepted and handled like GE. For the second operand of an S operator, only the comparators LE and LT are allowed - EQ is also accepted and handled like LE.
If no comparator is specified, an `equal to' operation is assumed.
AA. |
AA equal to the value specified in the value buffer. |
AA,LT. |
AA less than the value specified in the value buffer. |
AA,GE. |
AA greater than or equal to the value specified in the value buffer. |
Command_id
A search expression may consist of a command ID value (enclosed within parentheses) which identifies a list of ISNs resulting from a previous find command in which the SAVE ISN LIST option was used. An ISN list resulting from an S8 or S9 command may also be used.
A connecting operator may be used to connect search expressions. The permissible connecting operators (in order of increasing precedence) are:
| Connecting Operator | Meaning | Examples |
|---|---|---|
| R |
Specifies that the results of two search expressions are to be combined using a logical OR operation. |
AA,R,AB. |
| D |
Specifies that the results of two search expressions are to be combined using a logical AND operation. |
AA,D,AB. |
| O |
Specifies that the results of two search expressions are to be combined using a logical OR operation. The O operator may only be used to connect search expressions which use the same descriptor. |
AA,O,AA. Valid AA,O,AB. Invalid |
| S |
Expresses a FROM/TO range which involves two search expressions. The same descriptor must be used in both search expressions. Depending on the comparators defined for the operands, records for which the the field value is equal to the lower or upper bound can be included in the search result or omitted. |
AA,S,AA. AA,GE,S,AA,LE. Range including start and end values AA,GT,S,AA,LT. Range excluding start and end values |
| N |
Excludes a single value or a range of values from a previous FROM/TO range. This operator may only be specified in conjunction with the `S' operator. |
AA,S,AA,N,AA. Valid AA,S,AA,N,AB. Invalid AA,S,AA,N,AA,S,AA. Valid AA,S,AA,N,AA,N,AB. Invalid |
There are two possibilities for constructing a range like NAME between A and Z:
NAME greater equal A `AND' NAME less equal Z
SB := NA,1,GE,D,NA,1,LE. VB := AZ
NAME from A to Z
SB := NA,1,S,NA,1. VB := AZ
If different connecting operators are used within a single search buffer, the operators are processed in the following order:
evaluate all O/S/N operations, if necessary
evaluate D operations, if necessary
evaluate R operations, if necessary
Example: the search buffer: AA,S,AA,N,AA,O,AA,D,BB,R,CC,D,FF.
is evaluated as:(((((AA,S,AA),N,AA),O,AA),D,BB),R,(CC,D,FF))
The search buffer for a search in which soft coupling is to be used is constructed according to the following syntax:
(mfile, mfield, sfile, sfield [,mfile, mfield, sfile, sfield],...) /file/search expression [,operator, search-expression],... .
mfile
The main file. This file must also be specified in the file number field of the Adabas control block. The final resulting ISN list will contain ISNs contained in the main file only.
mfield
The field in the main file which is to be used as the soft coupling link field. This field must be a descriptor, subdescriptor, superdescriptor or hyperdescriptor. It may not be contained within a periodic group.
sfile, sfield
For each ISN selected from this sfile (according to the search criterion), the field specified as sfield will be read. The value of the field will then be used to determine which ISNs in the main file have a matching value.
sfield must be a field, either a non-descriptor or a descriptor, but not a subdescriptor, superdescriptor, hyperdescriptor collation descriptor or phonetic descriptor. It must have the same format as mfield. The standard length may be different.
The field may not be contained within a periodic group.
A maximum of 42 soft coupling criteria may be specified.
Please refer to the section Search/Value Buffer Examples in this chapter for examples of search criteria for soft coupling.
The search buffer as used with the L3, L6 and L9 commands is constructed according to the following syntax:
{L3_SB_element [,comparator].} | {L3_SB_element,S, L3_SB_element.}
The first form of the search buffer is used if the value buffer contains only the starting value or ending value for the processing sequence. The entry in the command option 2 field and the comparator used determines whether the value specified in the value buffer is interpreted as the starting descriptor value or as the ending descriptor value.
The second form of the search buffer is used if the value buffer contains both the starting value and the ending value for the processing sequence. The first value in the value buffer specifies the lower limit of the range, and the second value specifies the upper limit of the range. Whether it is the lower limit or the upper limit that determines the starting value or the ending value depends on whether ascending or descending sequence has been specified. This makes it possible for an application program to change the direction of processing by simply modifying the entry in the command options 2 field in the control block.
The syntax of an L3_SB_element is:
[name [i] D [,length] [,format] ,] name [i] [,length] [,format] , [,C]
where
- name D
If you want to specify a date/time value with the daylight saving time indicator, the daylight saving time indicator must be specified first, followed by the field specification including the date/time edit mask.
- name
The name of the descriptor to be used for sequence control. The name specified must be the same as that specified in the Additions 1 field in the control block.
- i
If the descriptor for which values are to be returned is contained in a periodic group, this option can be used to specify the occurrence number for which values are to be returned. The value specified in the ISN field of the control block will be ignored if both the search buffer and the value buffer are specified. All of the occurrences of a given value will be returned if no index is specified.
Note:
This option can only be used with the L9 command.- length
The length of the value as provided in the value buffer. If the length is not specified, it is assumed that the value is being provided using the default length of the descriptor as specified in the FDT.
- format
The format of the value as provided in the value buffer. If the format is not specified, it is assumed that the value is being provided using the default format of the descriptor as specified in the FDT.
- comparator
The comparators GE (greater than or equal to), GT (greater than), LE (less than or equal to), and LT (less than) can be used. GE is assumed if no comparator is specified.
- C
The C option may only be specified for collation descriptors without the HE option. When this option is specified, the corresponding value in the value buffer is not the collating key, but the value of the parent field.
If you don't specify the C option for a collation descriptor without HE option, because you want to specify collation keys that you created yourself with ICU, please note that Adabas uses ICU version 3.2. ICU keys created by a different ICU version may be incompatible with the collation keys used by Adabas.
The user specifies the values for each descriptor specified in the search buffer in the value buffer.
The values provided must be in the same sequence as the corresponding search expressions specified in the search buffer.
All values provided must correspond to the standard length and format of the corresponding descriptor, unless the user has explicitly overridden the standard length or format in the search buffer.
Note that for phonetic descriptors and for hyperdescriptors with the HE option, you must specify not the internal search value, but rather a corresponding parent field value.
If the search expression consists of a command ID, no corresponding entry is made in the value buffer. However, a non–zero value buffer length must be specified.
If the search expression contains a field name FN followed by the S option, the value buffer must contain the either the hexadecimal value FFFF (select all records with the null value in the field FN) or the hexadecimal value 0000 (select all records that do not have a null value in the field FN).
Intervening blanks or other characters such as a comma must not be inserted between the values in the value buffer. No period is required to terminate the value buffer.
This section contains examples of search and value buffer construction. All examples refer to the sample Adabas files in Appendix A. The values for the value buffer are shown in character and/or hexadecimal notation.
Search Buffer : AA.
Value Buffer : 12345bbb
0x3132333435202020
Result: This search returns the ISNs of all the records in file 1 which contain the value 12345 for field AA. The same search may be performed using AA,5. in the search buffer and the value 12345 (without trailing blanks) in the value buffer.
Search Buffer : AA,D,AB. Value Buffer : 0x3132333435363738002C
Result: this search returns the ISNs of all the records in file 1 which contain the value 12345678 for the field AA and the value +2 for the field AB.
Search Buffer : AA,D,AB,3,U.
Value Buffer : 12345678002
0x3132333435363738303032
Result: this search produces the same result as the preceding search. It shows the use of the length and format override in the search buffer.
Search Buffer : XB,3,U,O,XB,3,U,O,XB,3,U.
Value Buffer : 284285290
0x323834323835323930
Result: this search returns the ISNs of all the records in file 2 which contain any of the values 284, 285, or 290 for the field XB. Length and format overrides are also used.
Search Buffer : XB,S,XB. Value Buffer : 0x020C030C
Result: this search returns the ISNs of all the records in file 2 which contain any value within the range +20 to +30 for the field XB.
Search Buffer : XB,S,XB,N,XB. Value Buffer : 0x020C030C027C
Result: this search returns the ISNs of all the records in file 2 which contain any of the values in the range +20 to +30 but not +27 for the field XB.
Search Buffer : XB,S,XB,O,XB,S,XB. Value Buffer : 0x001C200C500C600C
Result: this search returns the ISNs of all the records in file 2 which contain any of the values in the range +1 to +200 or +500 to +600 for the field XB.
Search Buffer : MF.
Value Buffer : ABC
0x414243
Result: this search returns the ISNs of all the records in file 1 which contain the value ABC for any value of the multiple-value field MF.
Search Buffer : MF2. Invalid.
Search Buffer : BA. Value Buffer : 0x04
Result: this search returns the ISNs of all the records in file 1 which contain the value 4 in any occurrence of the descriptor BA (which is contained in a periodic group).
Search Buffer : BA3. Value Buffer : 0x04
Result: this search returns all the records in file 1 which contain the value4 in the third occurrence of the descriptor BA (which is contained within a periodic group).
Search Buffer : SA. Value Buffer : 0x41424344
Result: this search returns the ISNs of all the records in file 2 which contain the value ABCD for the subdescriptor SA.
Search Buffer : SB. Value Buffer : 0x414243444546474831323334
Result: this search returns the ISNs of all the records in file 2 which contain the value ABCDEFGH1234 for the superdescriptor SB.
Search Buffer : SC. Value Buffer : 0x020F313233343536
Result: this search returns the ISNs of all the records in file 2 which contain the value +20 for the field XB and the value 123456 for the field XC.
Search Buffer : (CID1),D,(CID2). Value Buffer : not used
Result: this search returns the ISNs present in both ISN lists identified by the command IDs CID1 and CID2.
Search Buffer : (CID1),D,AB,3,U.
Value Buffer : 123
0x313233
Result: this search returns the ISNs of all the records in file 1 for which an ISN is present in the ISN list identified by CID1 and which contain the value +123 for the field AB.
Search Buffer : AB,3,U,GT.
Value Buffer : 100
0x313030
Result: this search returns the ISNs of all the records in file 1 which contain a value greater than +100 for the field AB.
Search Buffer : AB,3,U,GT,D,AA,1,GT.
Value Buffer : 100A
0x31303041
Result: this search returns the ISNs of all the records in file 1 which contain a value greater than +100 for the field AB and a value greater than A for the field AA.
Search Buffer : AB,R,AC,3,NE,D,MF. Value Buffer : 0x001C414243414243
Result: this search returns the ISNs of all records in file 1 that contain the value 0x001C in the filed AB or don't contain the value 0x414243 in the first three bytes of the field AC and contain this value in the field MF.
Note:
The following example assumes that the field ZZ is an
alphanumeric field with the NC option. The field ZZ does not appear in the
sample listings in Appendix A.
Search Buffer : AA,4,A,D,ZZS. Value Buffer : 0x41424344FFFF
Result: records are selected with field AA = "ABCD" and a null value in field ZZ.
Search Buffer : AA,4,A,D,ZZS. Value Buffer : 0x414243440000
Result: records are selected with field AA = "ABCD" and a non–null value in field ZZ.
File Number : 4 Search Buffer: (4,AB,1,AC)/1/AB,S,AB. Value Buffer : ...........
Search file 1 for AB=value as provided in the value buffer;
For each resulting ISN in file 1, read the field AC and internally match the value with the corresponding value list for file 4;
The resulting ISN list from file 4 is provided in the ISN buffer.
File Number : 1 Search Buffer: (1,AA,2,AB)/1/AC,D,AE,D,/2/AF,S,AF. Value Buffer : ...........
Search file 2 for AF=... through ... (values provided in the value buffer);
For each resulting ISN in file 2, read the field AB and internally match the value with the corresponding value list for file 1;
Search file 1 for AC=... and AE=... (values provided in the value buffer);
Match resulting ISN lists from steps 2 and 3;
ISNs resulting from step 4 are provided in the ISN buffer.
File Number : 1
Search Buffer: (1,AA,2,AB;1,AA,5,BA)
/1/AC,D,AE,D,/2/AF,S,AF,D,/5/BC,S,BC.
Search file 2 for AF=... through ... (values provided in the value buffer);
For each resulting ISN in file 2, read the field AB and internally match the value with the corresponding value list for file 1;
Search file 5 for BC=... through ... (values provided in the value buffer);
For each resulting ISN in file 5, read the field BA and internally match the value with the corresponding value list for file 1;
Search file 1 for AC=... through ... (values provided in the value buffer);
Match the resulting ISN lists from steps 2, 4 and 5;
ISNs resulting from step 6 are provided in the ISN buffer.
Search Buffer : AA,4,A,NE.
Value Buffer : ABCD
0x41424344
Result: this selects all records with field AA not equal to "ABCD".
Search Buffer : AA,4,A,R,BB,LT.
Value Buffer : ABCD3000
0x4142434433303030
Result: this selects all records with field AA equal to "ABCD" or field BB less than "3000".
Search Buffer : AA,4,A,R,(TEST).
Value Buffer : ABCD
0x41424344
Result: this selects all records with field AA equal to "ABCD" or which are members of the ISN list "TEST".
Multifetch buffers are needed only for some Adabas commands run using the ACBX direct call interface; they are not needed for any ACB interface direct calls.
A multifetch buffer defines an area in storage to which Adabas can return the record descriptor elements (RDEs) of multifetched records. This buffer is only required by Adabas commands for which the multifetch option has been activated (by setting Command Option 1 to "M"). RDEs are each 16 bytes long.
When the multifetch option M is set in the Command Option 1 field of an ACBX command, Adabas returns all records being read in the specified record buffer segments, based on the format specifications in the corresponding format buffer segments. For each record buffer segment, the corresponding multifetch buffer segment contains multifetch headers describing the records in the record buffer segment.
For BT or ET commands, a multifetch buffer is not needed if Command Option 1 is set to "M". In this case, the ISN buffer is used to store the ISNs that need to be removed from the hold queue.
When a multifetch buffer is required, a corresponding format and record buffer are expected as well. If they are not provided, Adabas will create dummy format and record buffers (with length zero) to pair with the multifetch buffer. For complete information about the relationships between the different types of ABD or buffer specifications, read Understanding the Different Buffer Types.
Adabas returns the ISNs of the records which satisfy the search criteria in this buffer.
Each ISN is provided as a four-byte binary number. The ISNs are provided in ascending sequence. For the S2 or S9 command, the ISNs are provided according to the user–specified sort sequence.
If the ISN buffer is not large enough to contain the entire resulting ISN list, Adabas will store (if requested) the overflow ISNs on the Adabas temporary working space. These overflow ISNs may be retrieved at a later time (see Programming Considerations, ISN List Processing for more detailed information).
Note:
Since the ACB interface does not support multifetch buffers, for
calls that use the ACB interface the ISN buffer is used instead of the
multifetch buffer if the mutlifetch option is set.
The following table describes how values in the record/value buffer are converted for update (including add)/search commands, and how the values in the data record are converted for read commands.
| Target Format - Standard format of the field specified* for update/search commands - Format specified in the format buffer for read commands |
Source Format - Format specified in the Format/Search Buffer for update/search commands - Standard format of the field specified for read commands |
Adabas Processing |
|---|---|---|
| ALPHANUMERIC | ALPHANUMERIC | Only the length is adapted. |
| BINARY, PACKED, UNPACKED |
The value is converted to UNPACKED, leading zeros are removed, the value is left justified with trailing spaces added if necessary. | |
| BINARY/FIXED | BINARY/FIXED | Only the length is adapted. |
| PACKED, UNPACKED |
The value is converted to BINARY/FIXED POINT. | |
| FLOATING POINT | FLOATING POINT | No conversion required. Different lengths cause a response code 41/61. |
| PACKED | PACKED | Only the length is adapted. |
| BINARY, UNPACKED, FIXED |
The value is converted to PACKED format. | |
| UNPACKED | UNPACKED | Only the length is adapted. |
| BINARY, PACKED, FIXED |
The value is converted to UNPACKED format. | |
| UNICODE | UNICODE | The value in the encoding specified as charset in the format/value buffer or in the OP command is converted to UTF-8. |
All other format combinations result in a response code 41 (format buffer) or 61 (search buffer).
* Subdescriptor format is the same format as the field from which it
is derived.
If all of the fields from which a superdescriptor is
derived are unpacked, the superdescriptor standard format is alphanumeric,
unpacked or binary, depending on the definition of the superdescriptor. If not
all of the fields from which it is derived are unpacked, the default
superdescriptor format is alphanumeric if at least one of the fields from which
it is derived is alphanumeric, otherwise it is binary.
Binary values are treated as unsigned numbers. Fixed point, floating point, unpacked and packed values are treated as signed numbers.
Valid signs which may be provided are:
Fixed point |
The sign is contained in the high-order bit 0 = positive 0x00000005 = +5 |
Floating point |
The sign is contained in the most-significant bit of the 4 or 8 bytes. |
Unpacked |
The sign is contained in the four high-order bits of the low-order byte (zoned format). 0x313233 = +123 |
Packed |
The sign is contained in the four low-order bits of the low-order byte. Input Output ----- ------ A,C,E,F C=positive B,D D=negative 0x123C = +123 If a search value is being provided for a superdescriptor which is derived from a packed field, an `A', `C', `E', `F' for positive or a `B', `D' for negative must be provided in the low nibble of the last byte. |
In application servers, multiple clients access the database through one server.
Due to the fact that the server issues the Adabas calls on behalf of the client, the server is the only virtual Adabas user that can be seen by the nucleus. The intention is to issue calls only from the server, but for the nucleus to recognize each user.
The Adabas user identification is made up from the node name, the user name, the environment-specific identification (process ID) and a timestamp.
The user identification information is set up on the client, which then provides the server with the information, or it is generated on the server.
In order to obtain the user identification information, the application has to issue a call lnk_get_adabas_id(). The interface for this routine is as follows:
#include "adabas.h" int lnk_get_adabas_id (int buffer_length, unsigned char *buf);
The first argument buffer_length describes the length of a buffer that is addressed by a second argument buf. This buffer will be filled with the user identification by lnk_get_adabas_id(...). The buffer length that is supplied must be sufficient to accommodate all of the information that is returned. The structure that is returned is as follows:
struct adaid {
unsigned short s_level; //security: equivalent structure level: 3
unsigned short s_size; //size of the data structure
unsigned char s_node[8]; //Adabas node name
unsigned char s_user[8]; //Adabas user name
unsigned int s_pid; //process identification, 4 bytes
long long s_timestamp //microseconds since 1970
};
For the current version, the structure level is 3, and the returned buffer length is 32 bytes. This user identification information must be sent to the server. The server has to issue a function call lnk_set_adabas_id() in order to make the user identification available to Adabas. The interface for this routine is as follows:
#include "adabas.h" int lnk_set_adabas_id (unsigned char *buf);
The argument is a pointer to a buffer that contains the user identification structure that is returned by lnk_get_adabas_id(...) on the client, or is generated on the server. ADALNK checks the input structure using the length field and the structure level, and makes the information available to Adabas. The user identification information has to be written by the server each time the client changes.
There are the following requirements for server-generated user identifications: neither the ASCII node name nor the ASCII user name nor the process ID may be filled with binary zeroes.
Notes:
Caution:
If you still use Adabas version 6.1 with an SP < 11 or
Adabas version 6.2 or Net-Work version 7.3, the timestamp is not used for
Adabas sessions where these versions are used. In such cases you have to take
the following into consideration: if you want to create a new Adabas session
with lnk_set_adabas_id, it is your responsibility to ensure that the
combination (node, user, pid) in the adaid structure specified is not used for
another Adabas session. Because the timestamp information is not yet used as
part of the user identification, it is not sufficient that there are different
timestamps in the adaid structure. If an existing user identification without a
timestamp is used, unexpected errors will occur since both clients share the
same Adabas session, which is not what is intended - a typical error in such a
case is an Adabas response code 153 if both clients issue an Adabas call at the
same time.
| Warning: If an application uses lnk_set_adabas_id, it is no longer possible for Adabas to recognize whether an Adabas call is the first call for an Adabas session. Therefore, transaction consistency following an Adabas nucleus restart is only guaranteed if the nucleus is started with the option OPEN_REQUIRED. |
Note:
Because Net-Work also uses lnk_set_adabas_id, you should always
use the option OPEN_REQUIRED if you use Net-Work.
If you write multi-threaded applications, you should use adalnkx.
The standard way to call Adabas in multi-threaded applications is for each thread that needs to execute Adabas calls to have its own Adabas session; each thread first makes an open command, then the Adabas calls to access the database, and finally a close command.
It is also possible to use one Adabas session in different threads by using the functions lnk_get_adabas_id and lnk_set_adabas_id. If you have an active Adabas session in thread 1, and you want to continue it in thread 2, you must first call lnk_get_adabas_id in thread 1 and then call lnk_set_adabas_id in thread 2.
Note:
Older multi-threaded applications that were developed before
adalnkx was available might still call the old interface adalnk. This is
possible if you use the following rules:
the adalnk calls must be synchronized - only one thread at a time may call adalnk;
while adalnkx by default creates a separate Adabas session for each thread, adalnk by default only creates one Adabas session for the whole process. If you want to have more sessions, you must use lnk_set_adabas_id.
The application is responsible for setting the user credentials prior to opening a database session.
The following Adabas Client functions are provided to manage client sessions and set credentials:
| Steps | Function | Description |
|---|---|---|
| 1 (optional) | lnk_set_adabas_id() | Set the session identification. |
| 2 | lnk_set_uid_pw() | Set the authentication credentials for a specific database. |
Step 1 is optional. It is only required in application servers, where multiple clients access the database through one server. The Adabas session identification must then be set prior to setting the credentials.
It is mandatory, when accessing a secured database that the credentials are set prior to the start of each Adabas session and must be set for each database ID that is to be accessed.
The credentials are valid for the duration of the database session. Attempts to set credentials during an open database session will result in a nucleus response 9 “SE”: Security Violation. Open database transactions are backed out.
Database sessions with either invalid credentials or that are initiated without credentials will result in a “Security Violation”: Nucleus response 200 with subcode 31.
Refer to the file security_example.c in Appendix D - Example Files in the Adabas Kit for further information.
#include "adabasx.h" int dbid; static char *uid; static char *passwd; /* ** Set database-specific credentials ** ** This must be done - ** a) for each Adabas Session (Prior to start of session) ** b) for each dbid, which is to be accessed ** */ lnk_set_uid_pw(dbid, uid, passwd);
The Adabas nucleus user exit 21 could be used to set authentication credentials.
The purpose of this routine is to ease the transition of applications to use Adabas authentication. This routine is not intended as a replacement for setting credentials in the application and should be used as briefly as possible.