The following document presents some common use cases for Adabas Client for Java.
The Adabas target can be a local database, or it can be a remote database connection path.
A local Adabas database target is accessed using the classic ADALNK libraries to send Adabas calls. In this case, only a database number must be specified.
/* simple Adabas Database target definition (dbid) */ AdabasTarget target = new AdabasTarget(dbid); target.open();
A remote Adabas database is referenced using an Entire Net-Work (WCP) URL connection string.
AdabasTarget(int dbid, java.lang.String url) Adabas Target definition with an Entire Net-Work remote URL reference.
Sample URL reference:
tcpip://<hostname>.<domainname>:<port>
On mainframe platforms, Adabas Client for Java API uses the EBCDIC (037) character set to connect to and communicate with an Adabas server environment. Software AG recommends that you use UES-enabled mainframe databases in order to avoid this restriction.
Note:
It is also possible to use an Adabas Directory Server or a flat
file named xtsurl.cfg, that contains remote database URL
references.
In addition to the database ID, additional parameters, such as the
file number and short name fields, need to be specified. The main class used to
read data from Adabas is the ReadRequest class.
A simple example application (which accesses the fields AA and AB of file number 11 in database 24) would require the following settings:
/* Short name fields to generate the Adabas Format Buffer */
String fields = new String{"AA","AB"};
/* Create read request with parameter database id and file number */
ReadRequest request = new ReadRequest(24,11).queryFields(fields);
/* Send request and receive results */
QueryResultList list = (QueryResultList) request.readIsnSequence();
The readIsnSequence() method sends the query
to the database and the results will be collected in a list array. The list
contains entries for each database record.
The following example will return the field value instance of field "AC" in the first record:
IRecordEntry record = list.get(0);
IAdaFieldValue fieldValueFirstName = record.getDeepFieldValuebyShortName("AC");
String firstName = fieldValueFirstName.getValue();
Note:
By default, database security is disabled, and therefore no
session information is required for further initialization. As soon as the
database is protected, either by authentication and/or by authorization rules,
session information is required - refer to the
ReadRequest constructors and
AdabasSession class for further information.
The mapping extension allows you to use long names instead of short names (2 byte) to reference Adabas fields. The corresponding metadata is stored in an Adabas database file (map configuration file). It is recommended that you use one configuration file per database.
Refer to the description of the Data Designer for further details about mapping.
The location of the map definition must be registered. This can be
done using the AdabasMapper or
ReadRequest classes:
AdabasMapper
AdabasMapper.addMapStorage(<URL location>,<configuration file number> );
ReadRequest
ReadRequest request = new ReadRequest("EmployeeMap",<url to database>,<map configuration file>).queryFields(fields);
The main class used to read data from Adabas is the
ReadRequest class. The
ReadRequest can be initialized with just the classic
parameters. A simple example application requires the following statements:
/* Long name fields now possible */
String fields = new String{"FirstName","LastName"};
/* Create request containing needed parameters */
ReadRequest request = new ReadRequest("EmployeeMap").queryFields(fields);
/* Send request and receive result */
QueryResultList list = (QueryResultList) request.readIsnSequence();
This example uses the map named EmployeeMap.
The database ID and file number are part of the mapping information. In this
example, the map defines database ID 24 and the file number 11 as the data
location. File 11 is the standard employee demo file delivered with Adabas on
all Linux, Unix and Windows platforms. The Adabas fields are listed in the
“fields” variable. The field FirstName is mapped to AC
and the field LastName is mapped to AE.
The following statements return the field value instance of field LastName in the first record:
IRecordEntry record = list.get(0);
IAdaFieldValue fieldValueFirstName = record.getDeepFieldValueby("LastName");
String firstName = fieldValueFirstName.getValue();
Note:
Please look at the examples folder (mapping) delivered with the
package. Compiling and executing GenerateMappingsExample
will add two example mapping definitions named
EmployeeMap and VehicleMap, which
are used in the other examples. See also the tutorial Adding the
Adabas Client for Java Example Programs in Eclipse.
The ReadRequest class includes extensions to
support the search capabilties of Adabas.
The Adabas Client for Java API includes the method
setSearch. The following table shows some example
search queries.
| Search | Result |
|---|---|
| AE='SMITH' | Search for records with field AE and value SMITH |
| AE>'ADAM' | Search for records with field AE and values greater than ADAM |
| AA>12345 | Search for records where field AA is greater than 12345 |
You only need to add an additional statement to your read request :
String fields = new String{"AA","AB"};
/* Create request containing needed parameters */
ReadRequest request = new ReadRequest(24,11).queryFields(fields);
request.setSearch("AE='SMITH'");
/* Send request and receive result */
QueryResultList list = (QueryResultList) request.readIsnSequence();
A further method is to generate a search tree. Instead of using
the setSearch(...) method, the application can
generate search trees to support further Adabas search capabilities. For
example, it is possible to define values for lower and upper limits:
RecordDefinition definition = request.addFieldsQuery(fields);
/* Get field type for field AE */
AdaFieldType lastName = definition.getDeepFieldbyShortName("AE");
/* Define search tree, one node for lower limit and one node for upper limit */
SearchTree lowerTree = new SearchTree("GE", (IAdaFieldValue) lastName.getFieldValue());
lowerTree.setValue("SCHNEIDER".getBytes());
SearchTree upperTree = new SearchTree("LT", (IAdaFieldValue) lastName.getFieldValue());
upperTree.setValue("SD".getBytes());
lowerTree.bound(upperTree, SearchTree.AND);
request.setSearchTree(lowerTree);
This example will extract only those records that meet the specified criterion of AE >= "SCHNEIDER" and AE < "SD".
This example is also intended to illustrate the relationship between the Data Designer and the variable declarations in the java example programs provided - it shows screen shots from the Data Designer together with variable declarations and statements from the example SuperdescriptorSearchExample.java.
Group field AB.

Super descriptor field S2.

Variable declaration from example SuperdescriptorSearchExample.java.
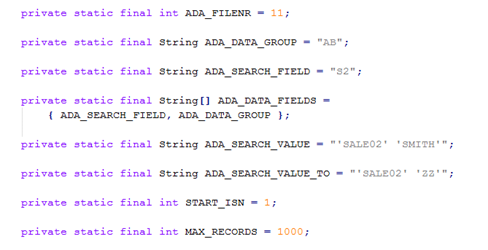
Statements from example SuperdescriptorSearchExample.java.
